




谷歌多模态模型革新:文本图像视频音频一体融合

henry 发自 凹非寺量子位 | 公众号 QbitAI原生,启动!刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——Gemini Embedding 2这次模型最大的变化在于:把文
henry 发自 凹非寺
量子位 | 公众号 QbitAI
原生,启动!
刚刚,谷歌发布了首个原生多模态(Multimodal)嵌入模型——
Gemini Embedding 2
这次模型最大的变化在于:把文本、图像、视频、音频和文档,全部映射进同一个统一的嵌入空间。

换句话说,不同媒介的数据第一次被放进同一个语义坐标系里。
在输入能力上,Gemini Embedding 2支持多种数据类型:
文本:支持最多8192个token图像:每次请求最多处理6张图像,支持PNG和JPEG视频:支持最长120秒的视频输入,格式为MP4和MOV音频:原生嵌入音频数据,无需中间文本转录文档:可直接嵌入最多6页的PDF
此外,模型不仅可以处理单一模态,还支持多模态混合输入(例如图像 +文本)。
这意味着模型可以捕捉不同媒体之间的复杂语义关系,从而更准确地理解现实世界中的信息。
在评测方面,Gemini Embedding 2不仅整体性能较上一代提升,同时也为多模态嵌入任务树立了新的性能基准。
一方面增强了语音处理能力,另一方面也在文本、图像和视频任务中均超越现有领先模型,实现SOTA。
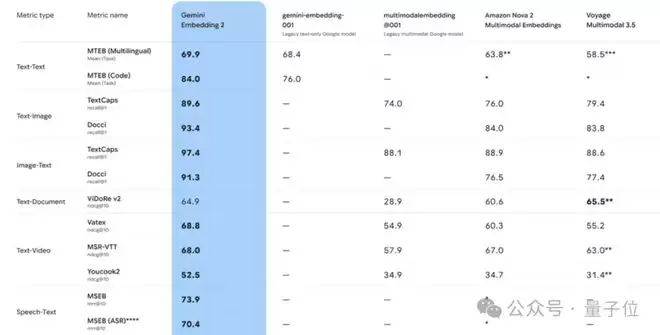
乍看之下,这似乎只是一次底层的数据工程升级。
但实际上,它正为像龙虾这样的AI Agent真正“看懂”世界,提供了关键基础。
目前,Gemini Embedding 2已经通过Gemini API和Vertex AI展开公测。
原生多模态嵌入
嵌入模型(Embedding Model)本质上是把数据转化为稠密向量表示。
在这个向量空间中,语义相似的数据会彼此靠近,不相似的数据则距离更远。
传统的嵌入模型主要针对文本。
例如,在谷歌此前的论文《Gemini Embedding: Generalizable Embeddings from Gemini》中——
Gemini Embedding通过在大语言模型参数中已有的海量知识基础上构建表征,并将得来的嵌入用于:语义检索、文本聚类、分类,排序等下游任务。

但这只停留在文字阶段。
最新的Gemini Embedding 2,则首次彻底打通了多模态数据。
文本、图片、视频、音频和文档,都被压缩到同一个向量空间之中。
而这,就意味着模型实现了“跨模态语义对齐”,能够让猫这个「文字概念」与猫的照片这个「视觉概念」,在统一的嵌入空间中的数学向量的距离极度接近。
通俗来说,当你搜索“猫”的时候,系统不仅能找到相关文字,还能直接找到猫的图片、视频甚至声音。
也正因为如此,很多原本复杂的多模态流程可以被大幅简化。
RAG检索、语义搜索、情感分析,到数据聚类等应用场景,都能直接受益。
更重要的是,这类能力对AI Agent意义巨大。
过去的Agent在操作电脑时,往往只能依赖文字信息。
例如识别按钮上的“设置”“确认”等标签。但真实世界的UI界面,大量信息其实来自视觉结构:
图标、布局、颜色、控件位置,正是传统文本嵌入模型难以处理的部分。
而有了多模态嵌入之后,情况就不同了。
对于像OpenClaw(龙虾)这样需要操作电脑,识别屏幕的Agent来说,它不再只是识别文字。

它可以直接理解:哪个像素区域是设置图标、哪个按钮与当前任务最相关,屏幕截图与文本指令之间的关系
换句话说,Gemini Embedding 2提供了一条统一的感官总线。视觉、听觉与文本信息,都能在同一个语义空间中进行关联。
这也为未来Agent真正理解屏幕、理解环境并代替人类操作电脑,奠定了最重要的语义基础。
在技术层面,Gemini Embedding 2继续采用Matryoshka Representation Learning(MRL)

这种方法允许嵌入向量在保持语义信息的同时进行动态维度缩减。
(注:MRL强制模型把最核心、最关键的特征压缩在向量的前几十维里,次要的特征放在后面,这让开发者可以根据预算和算力,自由决定信息密度的分布管理)
Gemini Embedding 2的默认输出维度为3072维,但开发者可以根据需求缩减,例如:3072维、1536维、768维,从而在性能与存储成本之间取得平衡。
除了支持API调用外,Gemini Embedding 2也支持通过LangChain、LlamaIndex、Haystack、Weaviate、QDrant、ChromaDB和Vector Search等工具调用。
通过为不同类型的数据赋予统一的语义表示,Gemini Embedding 2正在为下一代AI应用:多模态Agent,乃至具身智能机器人提供关键基础设施。
[1]https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/
[2]https://arxiv.org/pdf/2503.07891
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:谷歌多模态模型革新:文本图像视频音频一体融合要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点通义千问系列模型升级至Qwen2,涵盖0 5B至72B共五个尺寸,全部标配分组查询注意力机制,上下文长度最高支持128Ktokens。新增27种语言训练数据,在代码、数学等能力上显著提升,Qwen2-72B超越Llama-3-70B等顶尖开源模型。
腾讯发布混元文生图大模型加速库,生图时间缩短75%,支持ComfyUI界面与HuggingFace三行调用。作为业内首个中文原生DiT架构开源模型,支持中英双语输入,最低11GB显存。
StabilityAI推出StableAudioOpen1 0,专门用于生成鼓点、乐器乐段及环境音效等短音频片段,时长最长47秒。该模型遵循非商业研究社区协议开源,允许用户进行微调,训练数据源自FreeSound及免费音乐档案,确保不含版权材料,可用于研究和创作。
BestyAI全天候智能聊天助手,随时陪伴、建议与倾听。可智能回答天气、旅行攻略、烹饪技巧等问题,对话流畅,支持多语言,安全可靠。提供温暖交流与实用信息,让您随时随地获得帮助。
- 日榜
- 周榜
- 月榜
热点快看