




谷歌新研究:大语言模型可节省80%内存,闪存行业损失50亿美元

3 月 24 日,Google Research 发布了一套名为 TurboQuant 的向量量化压缩算法,宣称能将大语言模型的 KV 缓存(Key-Value Cache)压缩至仅 3 比特,同时
3 月 24 日,Google Research 发布了一套名为 TurboQuant 的向量量化压缩算法,宣称能将大语言模型的 KV 缓存(Key-Value Cache)压缩至仅 3 比特,同时实现零精度损失。
在 NVIDIA H100 GPU 上的测试中,4 比特精度的 TurboQuant 在计算注意力 logits 时取得了相比 32 位未量化基线高达 8 倍的性能提升。这篇论文将于下月在 ICLR 2026 上正式发表,第一作者 Amir Zandieh 是 Google Research 的研究科学家,通讯作者 Vahab Mirrokni 是 Google Research 副总裁兼 Google Fellow。

图丨相关论文(来源:arXiv)
消息发布当天,资本市场给出了自己的解读。内存芯片厂商 SanDisk(SNDK)股价在周三交易时段下跌约 5%,收于 677.86 美元。分析师指出,TurboQuant 所代表的极端压缩技术路线,对于一家凭借 AI 驱动的内存需求在 2025 年股价飙涨近 196% 的芯片公司而言,构成了直接的叙事威胁。这个市场反应或许有些过度,但华尔街的焦虑也不无道理,毕竟 KV 缓存的内存开销,确实已经是 LLM 运营者账单上最大的单项成本之一。
大语言模型在生成文本时,每处理一个 token 都需要计算并存储一组 key 和 value 向量,以便后续生成时不必从头重算。这些向量逐 token 累积,内存占用随上下文长度线性增长。
以 Llama 3 70B 参数模型为例,当并发服务 512 个请求、每个请求的 prompt 长度为 2,048 个 token 时,仅 KV 缓存就需要大约 512GB 的存储空间,几乎是模型权重本身所需内存的四倍。上下文窗口越长,这个数字就越夸张。对于任何在生产环境中运行 LLM 的团队来说,KV 缓存的内存开销早已从技术细节升级为成本核心。
传统的向量量化方法确实可以压缩 KV 缓存,把浮点数映射到低比特的整数表示,但大多数方案都面临一个共同的尴尬:为了保证量化精度,每个数据块都需要额外存储一组全精度的量化常数(比如缩放因子和零点),这些常数本身会增加 1 到 2 个比特的额外开销,相当于一边压缩一边又把空间还回去。TurboQuant 瞄准的正是这个问题。
TurboQuant 本质上是三篇论文的组合成果。第一个组件叫 PolarQuant,将在 AISTATS 2026 上发表。它的核心思路是对输入向量做一次随机旋转,将数据从标准的笛卡尔坐标系转换到极坐标系。传统量化方法在笛卡尔坐标下工作,需要为每个数据块单独计算归一化参数,而极坐标变换后,向量被分解为一个半径(代表信号强度)和一组角度(代表方向信息)。
关键在于,旋转后每个坐标的分布会收敛到一个已知的 Beta 分布(高维下近似高斯分布),且不同坐标之间近似独立。这意味着可以对每个坐标独立地使用最优的标量量化器(通过经典的 Lloyd-Max 算法求解连续一维 k-means 问题),不再需要存储逐块的量化常数,从根本上消除了传统方法的内存开销。
第二个组件是 QJL(Quantized Johnson-Lindenstrauss,量化 JL 变换),已于 AAAI 2025 发表。QJL 利用经典的 Johnson-Lindenstrauss 变换将高维数据降维,同时把每个结果值压到只剩一个符号位(+1 或 -1),整个过程零额外内存开销。它的价值在于提供无偏的内积估计,这对注意力计算至关重要。
TurboQuant 将两者组合成一个两阶段流水线:先用 PolarQuant 以 b-1 比特的精度完成主体压缩,吃掉绝大部分误差;再对残差(主体压缩后剩余的微小误差)施加 1 比特的 QJL 变换,消除内积估计中的偏差。论文从信息论角度证明,这种组合方案的失真率与 Shannon 下界之间只差一个约 2.7 的常数因子。换句话说,TurboQuant 在理论上已经非常接近任何压缩算法所能达到的最优边界。
实验结果的亮点集中在几个方面。在“大海捞针”(Needle-in-a-Haystack)测试中,TurboQuant 在将 KV 缓存压缩至少 6 倍的情况下,取得了与未压缩基线完全一致的 0.997 分,而此前广泛使用的 KIVI 方法在同等压缩条件下得分为 0.981,SnapKV 和 PyramidKV 等 token 级剪枝方案的表现则更弱。
在 LongBench 基准上,覆盖问答、摘要、代码补全和 few-shot 学习等任务,3.5 比特的 TurboQuant 在 Llama-3.1-8B-Instruct 上取得了 50.06 的平均分,与 16 比特全精度缓存的 50.06 持平;即便压到 2.5 比特,平均分也只微降至 49.44。
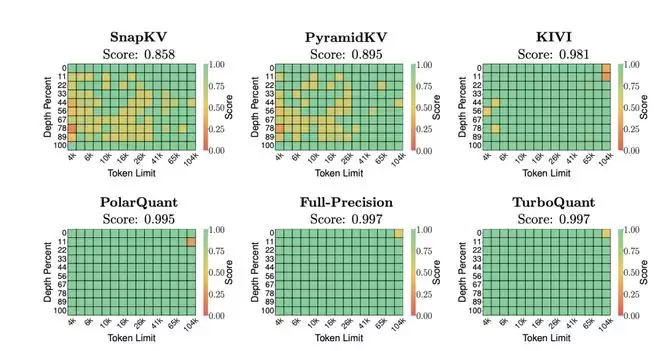
图丨大海捞针基准测试结果(来源:arXiv)
在向量搜索场景中,TurboQuant 同样表现突出。研究团队在 GloVe(200 维)和 OpenAI 嵌入(1536 维、3072 维)数据集上将其与 Product Quantization(PQ)和 RabitQ 做了对比。TurboQuant 在各个维度和比特精度下的 1@k 召回率均优于两个基线,且完全不需要离线构建码本,PQ 需要 37 秒的码本构建时间(200 维、4 比特),RabitQ 需要 597 秒,TurboQuant 只需 0.0007 秒,几乎可以忽略。这意味着它天然适合数据持续更新的在线索引场景。
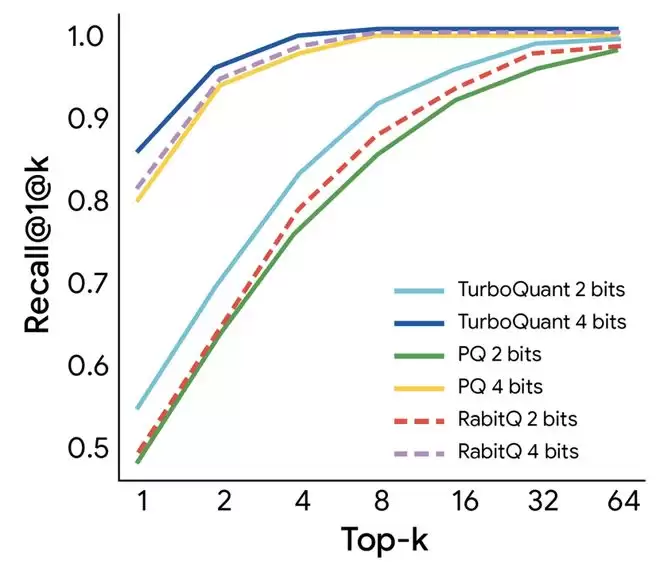
图丨GloVe 数据集(d=200)基准测试结果(来源:Google Researc)
值得一提的是,近期英伟达发布的 KVTC(KV Cache Transform Coding)也致力于这一方向(同样被 ICLR 2026 接收),且宣称可达 20 倍压缩,精度损失控制在 1 个百分点以内。不过两者严格来说解决的是不同环节的问题。
TurboQuant 是向量量化路线,目标是在推理过程中即时把 KV cache 压到低比特,然后直接用量化后的数据计算注意力,同时还兼顾向量搜索场景。 KVTC 走的是变换编码路线,借鉴 JPEG 图像压缩的思路:先用 PCA 去相关,再做自适应量化,最后用 DEFLATE 熵编码进一步压缩。它更侧重于 KV cache 的紧凑存储与传输,典型场景是多轮对话之间把 cache 卸载到 CPU 或 SSD 再恢复,或者跨请求复用 cache。
NVIDIA 研究员 Adrian Lancucki 在接受 VentureBeat 采访时也明确表示,KVTC 针对的是长上下文、多轮对话场景。相比较而言,TurboQuant则针对的是推理计算路径上的实时压缩。
在此之前,KV 缓存量化领域的标准基线是 2024 年发表于 ICML 的 KIVI,它引入了非对称 2 比特量化方案,实现了约 2.6 倍的内存压缩。KIVI 已经集成进了 HuggingFace Transformers,是目前部署最广泛的方案之一。TurboQuant 在同类向量量化路线上直接把压缩比从 2.6 倍拉到 6 倍以上,且不需要任何校准数据,进步幅度相当明显。
需要指出的是,TurboQuant 论文中的实验模型规模止步于 8B 参数左右(Llama-3.1-8B-Instruct、Ministral-7B-Instruct),尚未在 70B 或更大规模的模型上验证。而恰恰是在这些大模型上,KV 缓存的压缩才最迫切、收益也最大。
另外,这篇论文最早于 2025 年 4 月就出现在 arXiv 上,到现在快一年了,谷歌也没有公布最新的代码实现或与现有推理框架(如 vLLM、TensorRT-LLM)的集成计划,虽然社区已经出现了基于 Triton、MLX 和 llama.cpp 的第三方实现尝试。
Mirrokni 团队此前的 Titans 架构和 Nested Learning 范式也是类似情况,论文效果亮眼,学术社区讨论热烈,但最新代码始终没有释出,落地全靠第三方复现。TurboQuant 是否会重复这个模式,目前还不好说。
从这一点上来说,内存股价跌得可能有点太早了,更何况,AI 模型对内存的胃口,总是会迅速膨胀到填满所有可用空间。SemiAnalysis 此前在分析 HBM 发展路线时提过一个观察,可以叫“内存帕金森定律”:每一轮硬件升级或软件优化释放出来的余量,很快就会被更长的上下文窗口、更大的批处理规模、更复杂的推理管线吞掉。
所以,TurboQuant 省下来的那 5 倍内存,大概率不会让 GPU 闲着,它会被用来服务更多并发请求、处理更长的文档,或者跑原本塞不下的大模型。压缩技术扩大的是推理效率的供给侧,不是在缩减内存的需求总量。
参考资料:
1.https://arxiv.org/pdf/2504.19874
2.https://arxiv.org/pdf/2511.01815
3.https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
运营/排版:何晨龙

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

小米SU7六月销量揭晓零售34738辆批发超2万辆
7月1日,小米汽车官方微博发布消息称:2026年6月,月交付量稳定突破30000台。信息虽简短,但详细数据仍需参考乘联会的统计报告。 小米官方未单独公布具体数字,不过乘联会在6月全国乘用车市场分析中清晰列明:小米汽车新能源乘用车零售销量达34738辆,其中主力车型SU7批发销量突破2万辆,具体为20

Meta投资百亿美元建设加拿大首个数据中心
Meta在加拿大阿尔伯塔省投资约100亿美元建设首个海外数据中心,装机容量1吉瓦,预计两三年内建成。同时探索云计算业务,向第三方出售算力。市场对其资本支出逻辑和回报存在质疑。

iPhone 18 Pro A20 Pro芯片沿用LPDDR5X架构
苹果A20Pro芯片未用LPDDR6,沿用LPDDR5X,通道从4条增至6条,位宽达96-bit,优化AI推理、多任务及影像性能,成本与体验间优先释放当下性能。

三星全业务启动AI转型全面引入生成式AI工具
三星宣布全面启动人工智能转型,将在所有关联公司部署双子星、ChatGPT等生成式人工智能工具,覆盖设计、研发、生产、营销、服务等八大核心业务环节,同时设立专职人工智能组织,对高管和员工开展系统培训,并发布人工智能转型共同愿景宣言。

太平洋证券:硅烷材料从光伏辅料拓展至硅碳负极与光纤核心
电子特气是半导体制造第二大耗材,市场规模预计从2024年195亿元增至2030年708亿元。硅烷材料凭借“气体+含硅”双重特性,从光伏辅料向硅碳负极、光纤核心原料跃迁,成为重要增长极。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-09 13:02
2026-07-09 13:02
2026-07-09 13:02
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
热门教程
2026-07-09 13:02
2026-07-09 13:02
2026-07-09 13:02
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
2026-07-09 13:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















