




让多模态检索超越SOTA!ReCALL框架化解生成式与判别式的范式冲突

ReCALL团队 投稿量子位 | 公众号 QbitAI 把生成式大模型拿去当检索器用,是不是有点大材小用,效果还总不尽如人意? 按理说,多模态大模型(MLLM)拥有强大的图文理解和逻辑推理能力,用它来处理图像检索,特别是组合图像检索(CIR)这类复杂任务,本该是降维打击、手到擒来。 但现实却狠狠打了
ReCALL团队 投稿量子位 | 公众号 QbitAI
把生成式大模型拿去当检索器用,是不是有点大材小用,效果还总不尽如人意?
按理说,多模态大模型(MLLM)拥有强大的图文理解和逻辑推理能力,用它来处理图像检索,特别是组合图像检索(CIR)这类复杂任务,本该是降维打击、手到擒来。
但现实却狠狠打了我们的脸。一旦强行把生成式大模型改造成判别式检索器,模型就会出现明显的“水土不服”,甚至发生能力退化——连原本能轻松解决的问题,现在都频频出错。这种生成式与判别式之间的“范式冲突”,已然成了大模型向检索领域落地的主要障碍。

现在,这个行业难题终于被攻破了。来自AI国家队紫东太初团队与新加坡国立大学的研究人员,联手提出了全新的ReCALL框架。这个框架的核心,是一套独创的“诊断-生成-校准”闭环体系,它从根源上化解了范式冲突,让大模型在保留其原生细粒度推理能力的同时,成功转型为高效的检索器。
这项成果已被计算机视觉顶会CVPR 2026正式录用。在CIRR、FashionIQ等主流基准测试中,ReCALL全面刷新了SOTA性能。更重要的是,它为大模型在下游任务中实现“能力无损适配”开辟了一条全新路径,为多模态大模型在垂直领域的深耕打下了坚实基础。
行业痛点:范式冲突致大模型检索“智能倒退”
问题到底出在哪?为什么精明的MLLM一做检索就容易“翻车”?研究团队直指要害:根源在于“范式冲突”。
原生的大模型习惯了生成式范式,它依靠一步步的链式思考来理解图像中那些细微的视觉关联。然而,现有的检索适配方法大多采用判别式范式,粗暴地将这种高维、复杂的思考过程压缩成一个单一的向量,然后拿去计算相似度。
这种生硬的转换,直接引发了一个致命后果——能力退化。
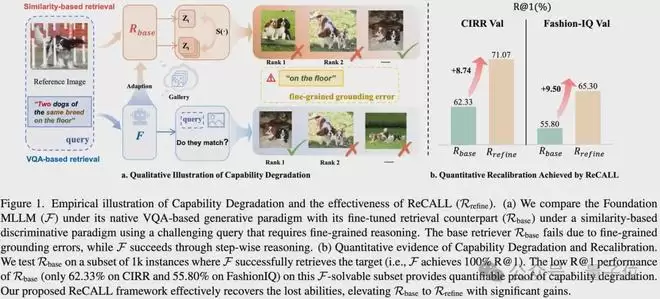
上图左侧的案例就很能说明问题。面对“地板上的两只同品种狗”这种需要细致辨别的查询,原生大模型通过视觉问答可以轻松锁定目标。但经过传统方法微调后的检索器版本,却完全丧失了这种细粒度的定位能力,找出来的全是错误答案。
定量数据更加触目惊心:在那些原生大模型本来能100%答对的样本子集上,微调后的检索器表现一落千丈。在CIRR数据集上,其R@1指标暴跌至62.33%;在FashionIQ数据集上,更是掉到55.80%。这哪里是学会了新技能,分明是把自带的“推理天赋”给弄丢了!
破局之道:ReCALL四阶段校准框架
既然能力退化是因为初期的检索微调把模型“带偏了”,那怎么把它“拉回正轨”?
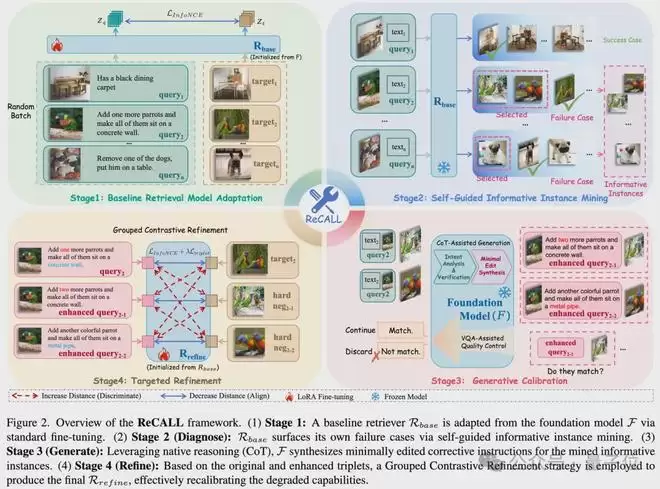
研究团队给出的答案是ReCALL框架,其核心思想颇为巧妙:利用大模型原生的推理能力,去纠正检索空间中的认知盲区。整个流程被严谨地设计为四个阶段。第一阶段完成了检索器的初始化,同时也暴露了退化问题;后续三个阶段,则构成了一套精密的“诊断-生成-打磨”校准管线:
Stage 1:基础检索适配。为了让生成式大模型具备基础的图文检索功能,第一步自然是进行标准微调,将其转化为一个基础检索器。这一步虽然赋予了模型判别能力,但也正是这种“单向量压缩”的暴力操作,为后续的能力退化埋下了伏笔。
Stage 2:自我诊断。老话说得好,“错题本是最好的老师”。让基础检索器在训练集上跑一遍,专门收集那些它“判错”的样本。这些能够高分迷惑检索器的负样本,通常与正确答案只有毫厘之差,它们恰恰就是模型认知最模糊、能力退化最严重的“盲区”。
Stage 3:生成校正。拿到这些“错题”后,研究团队没有简单地让原生大模型重新描述图片,而是设计了一套逻辑严密的链式思考诱导机制。具体来说,这个“讲题”过程被拆解为两个关键步骤:
① 意图分解与验证:大模型首先将原始的修改指令拆解成多个最细粒度的“原子意图”,然后逐一比对参考图和错误答案图,精准定位究竟是哪一个意图在错图中被违背了。
② 最小编辑合成:抓住矛盾点后,大模型会保留所有依然成立的意图,仅仅重写被违背的部分,“打补丁”式地合成出一条全新的、指向错误答案图的修改指令。
通过这种精巧的设计,框架自动生成了从“参考图”到“错图”的全新纠错三元组。这种文字上的“极小幅编辑”,在视觉层面恰好对应了目标图与强干扰错图之间那种微妙差异,从而为检索模型提供了极其明确、高密度的细粒度监督信号。
更重要的是,这种严格遵循“最小编辑原则”的生成方式,有效避免了文本的随意发散,最大程度保证了新构建的训练数据与原始数据集在分布上的一致性。最后,再经过一道视觉问答级别的语义一致性过滤,剔除幻觉和噪声,确保输送给模型的“纠错信号”既精准又可靠。
Stage 4:针对性打磨。有了精确的纠错指令,最后一步就是通过分组对比学习来完成模型的进化。框架会将原始查询和对应的纠错查询打包在同一个批次中进行“对冲”,配合双重优化目标,迫使检索器去清晰分辨那些极其细微的视觉-语义边界,最终将原生大模型的细粒度推理能力完美内化到自身的向量空间中。
正是这一套组合拳,让检索器不仅找回了丢失的推理能力,还将其牢固地整合进了自己的判别体系。
实测成绩:全场景刷新SOTA,细粒度检索能力拉满
ReCALL框架的有效性,在各大主流基准测试中得到了充分验证。

在开放域复杂数据集CIRR上,ReCALL创造了55.52%的R@1新SOTA记录,相比基线模型实现了8.38%的相对提升。而在专门考察细粒度区分能力的子集上,其表现更是达到了惊人的81.49%。在考验极致细节的FashionIQ时尚数据集上,即便面对高度相似的服装干扰项,ReCALL依然取得了最佳表现,平均R@10达到57.04%。

看看上面的实际检索案例就一目了然。基线模型遇到“正视镜头”、“半袖”这类细粒度条件时几乎束手无策;而经过ReCALL校准后的模型,则眼光精准,能迅速锁定目标。
结语
ReCALL的成功,其意义远不止于刷新了组合图像检索的性能纪录。它更重要的价值在于,揭示并修复了多模态大模型在向下游任务迁移时存在的一道“隐形裂痕”。
让大模型做检索,不应该只是粗暴地将其高维的“生成式智慧”压缩降维成单一的“判别式向量”。从“盲目对齐”走向“诊断—生成—内化”的逻辑闭环,标志着大模型的检索适配进入了一个全新阶段——一个更强调保留与激发其原生推理能力的阶段。
当我们不再一味地用海量数据去“喂养”检索器,而是引导模型运用自身的思维链去剖析错题、缝合认知盲区时,奇迹发生了:它不仅找回了丢失的细粒度感知力,更向我们展示了生成与判别这两大范式走向融合与和解的可能性。
这或许正是大模型在众多垂直领域实现“能力无损适配”的关键一步。
论文链接:
https://arxiv.org/abs/2602.01639
项目代码:
https://github.com/RemRico/Recall
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:让多模态检索超越SOTA!ReCALL框架化解生成式与判别式的范式冲突要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Predibase发布业界首个无服务器强化微调平台RFT,采用奖励函数驱动和端到端架构,无需大量标注。在Kernelbench上,微调Qwen2 5-Coder-32B-instruct正确率比DeepSeek-R1和OpenAIo1高3倍,比Claude3 7Sonnet高4倍,仅需十几个数据点。
一款基于乐鑫ESP32-S3的88元开源AI机器人,集成DeepSeek、通义Qwen2 5-Max等大模型,支持角色自定义、声纹识别、离线唤醒、流式对话及LCD显示。采用3D打印外壳,具备Wi-Fi 4G联网与开源源码,可二次开发,实现个性化智能交互,适合创客与教育场景。
总部位于旧金山的自动驾驶卡车初创公司Embark,正携手主流卡车品牌与运输巨头,致力于提升公路运输的安全性与效率。其核心策略并非自主造车,而是打造一个可适配所有卡车型号的AI平台。 商用半挂卡车实现大规模自动驾驶面临的一大挑战,是车辆型号的多样性。运输公司的车队通常混搭沃尔沃、万国、福莱纳等品牌,不
探索AI产品部署的全新方案:降低硬件成本,优化资源利用。核心内容:1 私有化部署AI产品的优势与挑战2 KTransformer算法原理及其显存优化能力3 KTransformer在不同场景下的实际应用与限制 近期调研了一线产品经理在AI领域的实践情况后发现,真正动手做AI的人非常少,绝大多数
- 日榜
- 周榜
- 月榜
热点快看