




MySQL视图与用户权限管理从入门到精通

1. 视图
1.1 视图的基本概念
想象一下,你面前有一张表格,但它并不真正存在于数据库的物理存储中,而是由查询语句动态生成的。这就是视图。你可以把它理解为一个“虚拟表”,它的数据来源于一个或多个基础表(或其他视图)的查询结果。用户可以对视图进行查询、更新等操作,就像操作一张普通的表一样。关键在于,视图本身不存储数据,它只是一个逻辑上的表示,其物理数据完全依赖于背后的基础表。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
1.2 视图的基本操作
1.2.1 创建视图
create view 列名1,列名2,列名3 as select 查询语句...
这里,view 是创建视图的关键字。
1.2.2 使用视图
视图到底有什么用?来看一个典型的场景:保护敏感数据。
假设我们只想查询学生的姓名和总分,而不希望暴露其学号和单科成绩。如果直接查询真实表,虽然可以做到,但存在风险——任何有查询权限的人,都可以随时在SELECT语句里加上那些敏感字段。
# 使⽤真实表进⾏查询 select s.name, sum(sc.score) total from student s, score sc where s.id = sc.student_id group by sc.student_id order by s.id; -- 缺点:可以随时在select关键字后加上学号和各科成绩字段,会暴露学生信息,不安全
这时,视图的价值就体现出来了。我们可以创建一个“安全窗口”。
# 创建视图 create view v_student_total_points as select s.id, s.name, sum(sc.score) total from student s, score sc where s.id = sc.student_id group by s.id order by s.id; -- 使用视图进行查询 select * from v_student_total_points; +-----------+-------+ | name | total | +-----------+-------+ | 唐三藏 | 469 | | 孙悟空 | 179.5 | | 猪悟能 | 200 | | 沙悟净 | 218 | | 宋江 | 118 | | 武松 | 178 | | 李逹 | 172 | +-----------+-------+ -- 只能查询出姓名和总分,进一步保护了学生的个人信息
视图的另一个妙用是简化复杂查询。既然视图本质上是一张虚拟表,那么它自然可以参与表连接。
select * from v_student_total_points v, student s where v.id = s.id; -- 视图本质上是一张虚拟的表,所以可以用视图与真实表进行表连接查询
1.2.3 修改数据
视图与基础表的数据是联动的,这一点需要特别注意。
- 通过真实表修改数据,会影响视图
# 修改唐三藏的JA VA成绩为99分 update score set score = 99 where student_id = 1 and course_id = 1; # 查询视图,发现唐三藏这条记录已被修改 select * from v_student_socre;
- 通过视图修改数据会影响基表
# 更新视图 update v_student_socre_v1 set score = 99 where score_id = 3; # 查看真实表数据,发现已被修改 select * from score where student_id = 1 and course_id = 5;
核心注意事项:
1. 修改真实表会影响视图,修改视图同样也会影响真实表,它们是双向联通的。
2. 但并非所有视图都可以更新。以下几种情况创建的视图是“只读”的,无法通过它来修改底层数据:
-------创建视图时使用聚合函数的视图
-------创建视图时使用 DISTINCT
-------创建视图时使用 GROUP BY 以及 HA VING子句
-------创建视图时使用 UNION 或 UNION ALL
-------查询列表中使用子查询
-------在FROM子句中引用不可更新视图
1.2.4 删除视图
# 语法 drop view 视图名;
1.3 视图的优点
- 简单性:视图可以将复杂的多表连接、嵌套查询封装成一个简单的查询接口。用户无需理解底层复杂逻辑,直接查询视图即可。
- 安全性:这是视图最核心的用途之一。通过创建不包含敏感字段(如密码、薪资)的视图,可以精确控制用户能看到的数据范围,实现数据层面的访问控制。
- 逻辑数据独立性:当底层表结构因业务调整发生变化时,只要视图的查询结果保持不变,依赖该视图的应用程序就无需修改。这实现了应用与数据库的解耦。
- 重命名列:视图允许为查询结果中的列起一个更直观、更符合业务场景的别名,从而增强数据的可读性。
2. 用户与权限管理
数据库安装后,默认的root用户拥有至高无上的权力,可以管理所有数据库。但在实际生产环境中,这显然不是最佳实践。更合理的做法是:为每个应用或业务模块创建独立的数据库,并分配一个专属用户,该用户只能操作自己名下的数据库,无法越界访问其他数据。这就是用户与权限管理要解决的问题。
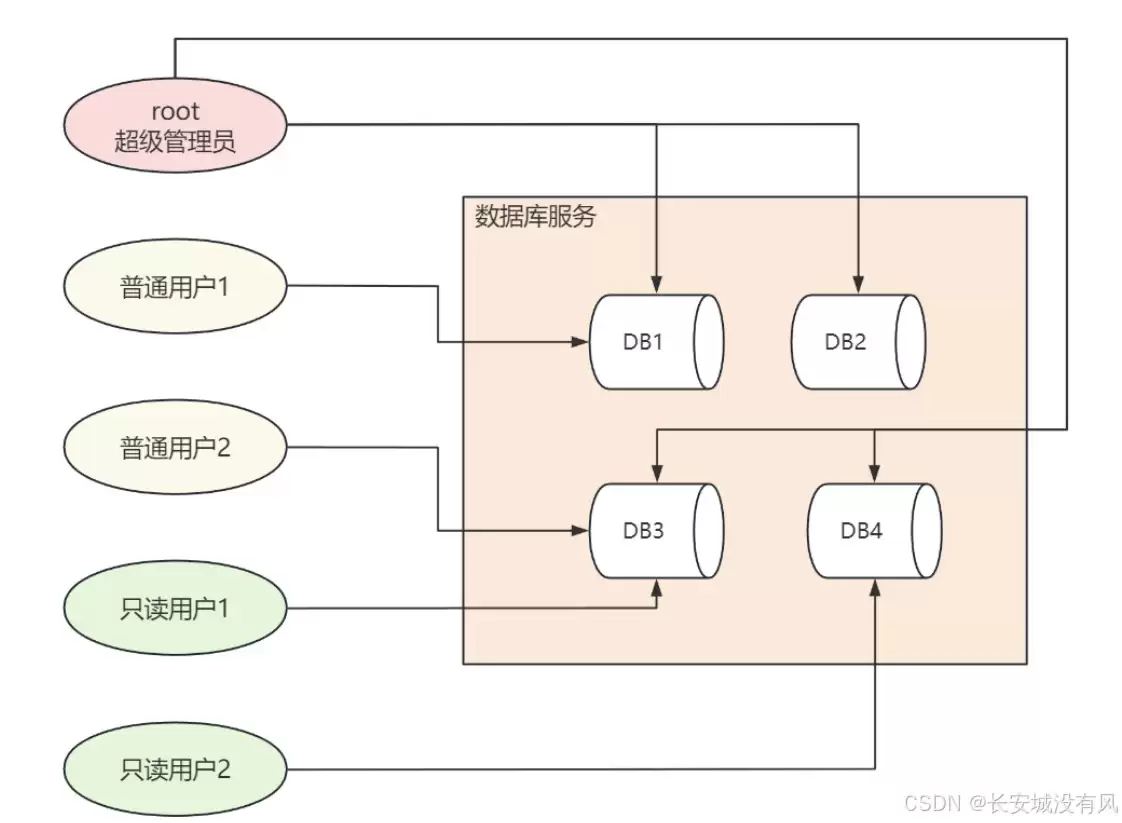
如上图所示,一个清晰的权限架构应该是这样的:
root 可以访问和操纵所有的数据库:DB1, DB2, DB3, DB4
普通用户1 只能访问和操纵数据库DB1
普通用户2 只能访问和操纵数据库DB3
只读用户1 只能访问数据库DB3
只读用户2 只能访问数据库DB4
2.1 用户
2.1.1 查看用户
所有用户信息都存储在mysql数据库的user表中。要查看用户,可以这样做:
-- 选择数据库 use mysql; -- 查看表结构 desc user; -- 查看用户表 select * from user;

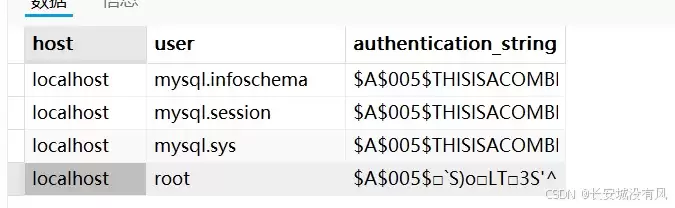
这张表的关键字段含义如下:
host: 允许登录的主机IP或域名,相当于白名单。
localhost表示只能从数据库服务器本机登录。user: 用户名。
*_priv: 用户拥有的具体权限,
Y表示有,N表示无。authentication_string: 加密后的用户密码。
2.1.2 创建用户
create user if not exists 'user_name'@'host_name' identified by 'auth_string';
user_name: 用户名,用单引号包裹,区分大小写。host_name: 允许登录的主机或IP段,同样用单引号包裹。auth_string: 用户的明文密码(注意:某些数据库的密码策略可能禁止使用过于简单的密码)。
例如,创建一个用户名为zhuxulong,密码为123456,且只允许从IP172.20.109.85登录的账户:
create user if not exists 'zhuxulong'@'172.20.109.85' identified by '123456';

创建用户时的几个关键细节:
- 如果不指定
host_name,则默认为'%',意味着允许从任何主机连接。这存在严重的安全风险,强烈不建议在生产环境中这样设置。 user_name和host_name必须分别用单引号包裹。如果写成'user_name@host_name',数据库会将其整体视为一个用户名,主机部分则变成'%'。host_name支持使用子网掩码格式来指定一个IP范围,这在大规模部署中非常有用:A: 198.0.0.0 : A段网络中的任意一台主机
B: 198.51.0.0 B段网络中的任意一台主机’
C: 198.51.100.0 C段网络中的任意一台主机
D: 198.51.100.1 :只包含特定IP地址的主机
2.1.3 修改密码
# 为指定⽤⼾设置密码 【推荐】 ALTER USER 'user_name'@'host_name' IDENTIFIED BY 'auth_string'; # 为指定⽤⼾设置密码 SET PASSWORD FOR 'user_name'@'host_name' = 'auth_string'; # 为当前登录⽤⼾设置密码 SET PASSWORD = 'auth_string';
2.1.4 删除用户
DROP USER [IF EXISTS] 'user_name'@'host_name'[, ...];
2.2 权限与授权
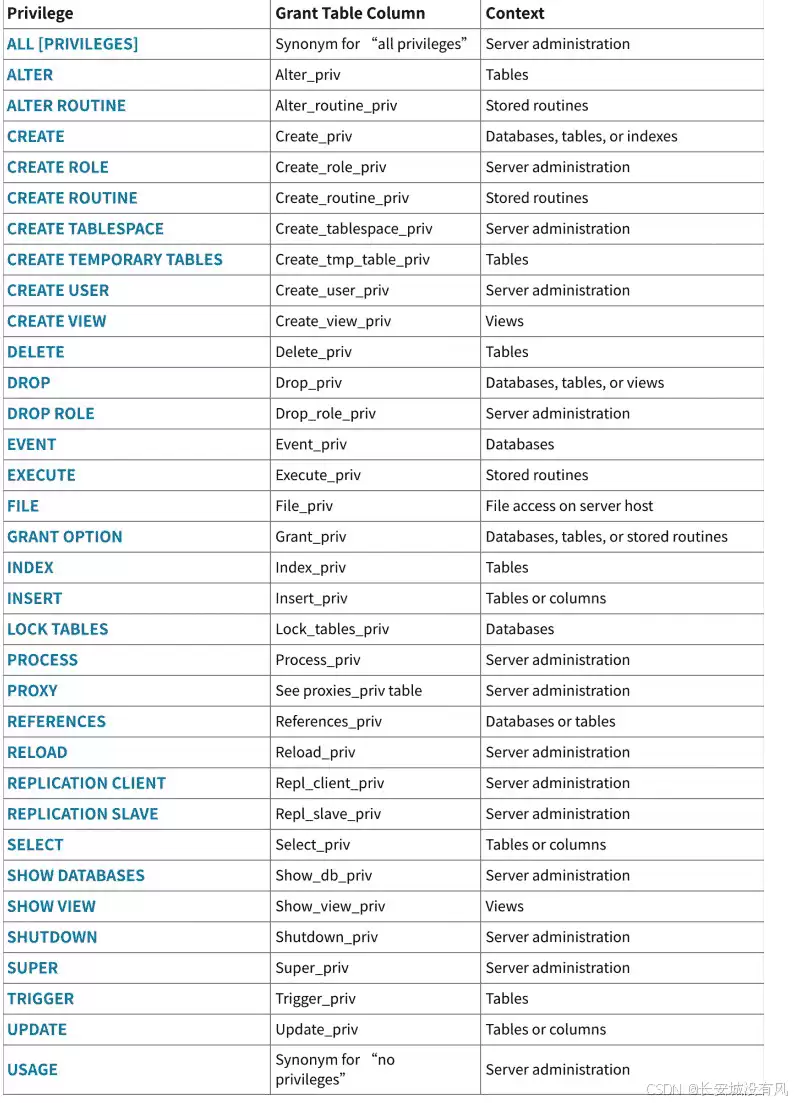
创建用户只是第一步,新用户默认是“光杆司令”,没有任何操作权限。我们需要手动为其授权。MySQL内置了非常丰富的权限,下图是一个常见的权限列表:
2.2.1 给用户授权
授权的基本语法如下:
grant 权限名 on priv_level to 'user_name'@'host_name' [WITH GRANT OPTION]
- 权限名:参考上图中的
Privilege列,如SELECT,INSERT,ALL PRIVILEGES等。 - priv_level: 指定权限的作用范围。常见格式有:
*.*: 所有数据库的所有表(相当于root的部分权限)。db_name.*: 指定数据库下的所有表。db_name.tbl_name: 指定数据库的指定表。
- 'user_name'@'host_name': 指定被授权的用户。
- [WITH GRANT OPTION]: 可选。如果加上,表示允许该用户将自己获得的权限再授予其他用户。
示例:为我们刚才创建的zhuxulong用户授予test数据库中student表的查询(SELECT)权限。
grant select on test.student to 'zhuxulong'@'172.20.109.85';
2.2.2 回收用户授权
权限给出去,也能收回来。回收权限使用REVOKE语句。
revoke 权限名 on 数据库名.表名 from 'user_name'@'host_name';
总结
视图和用户权限管理是数据库安全与数据管理的两大基石。视图通过逻辑封装提供了数据安全、简化访问和结构独立的优雅方案;而精细化的用户与权限管理,则是践行“最小权限原则”、保障数据库安全运行的必备手段。将两者结合使用,能构建起既灵活又安全的数据访问体系。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Redis List存储大量重复数据_利用SADD去重后再存入List优化
Redis List存储大量重复数据?别用SADD去重再存,这是个坑 开门见山,先说结论:千万别用 SADD 对 List 去重后再“存回去”。这个想法听起来挺合理,但实际上是个典型的“数据结构误用”陷阱。List 天生就允许重复,而 SADD 是 Set 结构的专属命令,把这两者硬凑在一起,不仅解

如何解决Python爬虫入库时的SQL注入隐患_使用SQLAlchemy参数映射
如何解决Python爬虫入库时的SQL注入隐患:使用SQLAlchemy参数映射 SQLAlchemy的text()配合:param参数映射之所以安全,是因为数据库驱动会将参数值作为纯数据传入,完全不参与SQL语法解析,从而避免了结构篡改;而错误地使用f-string进行拼接,则会直接导致注入漏洞。

如何利用SQL临时表提升复杂更新效率_分阶段处理中间数据
如何利用SQL临时表提升复杂更新效率:分阶段处理中间数据 面对复杂的数据库更新任务,直接一条UPDATE语句硬上,往往会撞上性能瓶颈。有没有一种方法,能把不可优化的逻辑拆解成可索引的步骤?答案是肯定的,其核心思路就在于:利用临时表固化中间结果,实现分阶段处理。这本质上是一种“空间换时间”的策略,将计

SQL如何实现对关联结果的条件计数_使用COUNT结合CASE_WHEN与JOIN
SQL如何实现对关联结果的条件计数:使用COUNT结合CASE_WHEN与JOIN 在数据分析工作中,一个常见的需求是:统计主表中每个主体在关联表中满足特定条件的记录数量。比如,想知道每个用户有多少个已支付的订单。这听起来简单,但如果不理解COUNT、JOIN和GROUP BY之间的配合机制,很容易

SQL如何对分组结果进行二次聚合_利用嵌套子查询或CTE
SQL如何对分组结果进行二次聚合:利用嵌套子查询或CTE 在数据分析中,我们常常需要先分组汇总,再对汇总结果进行整体计算。比如,先算出每位客户的总消费,再求所有客户总消费的平均值。新手常会直接尝试 A VG(SUM(x)) 这样的写法,结果无一例外会碰壁。这背后的原因,值得深究。 直接写 A VG(








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
