




何恺明、谢赛宁署名,Google DeepMind推出Vision Banana:图像生成器即通才视觉学习者

Vision Banana:生成即理解
在计算机视觉领域,我们习惯了泾渭分明的分工:一类模型专精于“理解”图像,比如做分割、检测;另一类模型则擅长“创造”,也就是生成新图像。长期以来,这两条技术路线并行发展,井水不犯河水。那些主流的表征学习方法,无论是监督学习还是对比学习,几乎都和生成式建模没什么关系。早期的生成式预训练模型虽然也展现出“规模越大、能力越强”的趋势,但论及纯粹的视觉理解任务,效果总是比不过那些非生成式的专家模型。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
然而,过去一年图像和视频生成模型的爆发,带来了一些有趣的“副产品”。这些模型在合成以假乱真的内容时,偶尔会显露出零样本视觉理解的迹象。这不禁让人重新思考一个老问题:一个能“画”出世界的模型,是否本身就“懂”这个世界? 之前的探索要么卡在如何让生成模型按指令输出可量化评估的结果,要么就得为理解任务加入专门模块并进行全量微调,结果往往牺牲了模型的通用性。
为了彻底回答这个问题,Google DeepMind团队交出了一份引人注目的答卷——Vision Banana。它基于强大的图像生成模型Nano Banana Pro,通过一种轻量级的指令微调策略打造而成。值得一提的是,何恺明、谢赛宁等知名学者也位列作者之中,这在一定程度上代表了顶尖研究团队对通用视觉基础模型未来方向的最新判断。

论文链接:https://arxiv.org/pdf/2604.20329
这项研究的核心结论相当直接,甚至有些大胆:只需要在NBP原始的海量训练数据中,混入极少比例的视觉任务数据,同时把所有视觉任务的输出都重新参数化成RGB图像,模型就能在2D和3D视觉理解的多项基准测试中,达到甚至超越SAM 3、Depth Anything 3、Lotus-2等专用模型的水准,并且还能完好保留它原本的图像生成能力。
1.将视觉任务重构为图像生成
这是整个方法最具巧思的一环。想想看,分割掩码、深度图、表面法线图……这些视觉任务的输出格式五花八门。Vision Banana的策略是,为它们设计一套“可解码的可视化方案”,全部统一成RGB图像格式。这样一来,模型的输出既能被人眼直观识别,也能通过明确的规则逆向还原成原始的物理量或语义标签。
举个具体的例子,对于语义分割任务,给模型的指令可能是“用纯黄色 <255, 255, 0> 分割出图中的滑板”。在评估时,只需要在模型生成的图片中找到所有颜色接近<255, 255, 0>的像素点,聚类起来就得到了滑板的精确掩码。
这种策略一举三得:首先,一个模型就能支持多种任务,切换任务只需调整指令,无需改动模型权重;其次,新增训练数据的需求极低,指令微调主要目的是教会模型如何把理解结果“格式化”为RGB输出;最后,模型原始的图像生成能力得以保留,因为它的输出本质始终是图像。
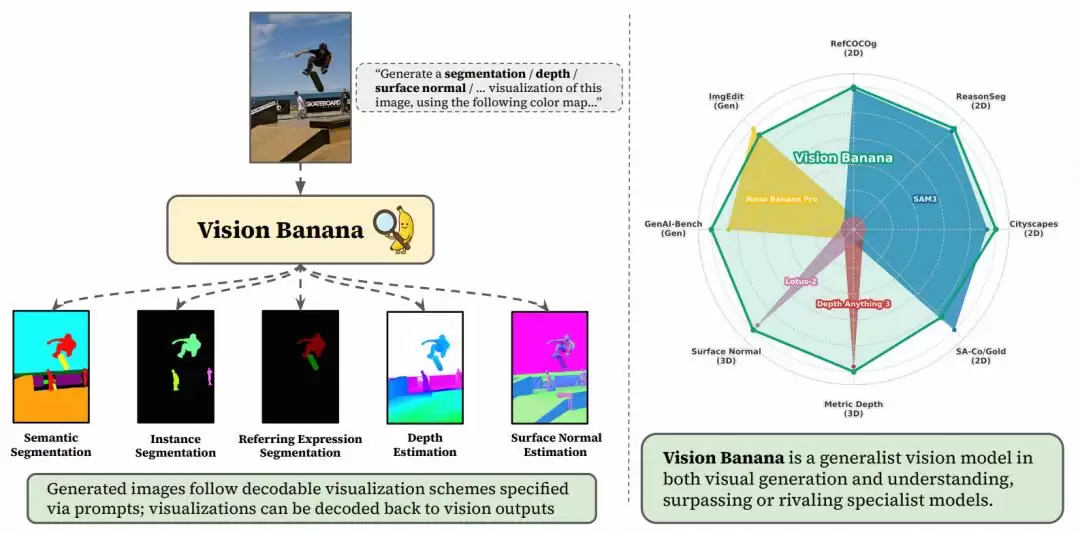
图|研究团队通过对 Nano Banana Pro 进行指令微调,揭示了图像生成器潜在的视觉理解能力。经过指令微调的模型 Vision Banana 能够以精确的格式生成可视化结果,从而支持在主流基准测试上进行评估。
2.轻量级指令微调策略
具体怎么训练呢?研究团队采用了一种“掺沙子”式的混合训练法:将视觉任务数据以极低的比例混入Nano Banana Pro的原始训练数据中,进行联合训练。这个“低比例”是关键,它能确保模型在对齐新视觉任务的同时,不会破坏掉已经学到的、强大的图像生成先验知识。
用于指令微调的视觉任务涵盖了2D和3D。2D任务主要包括指代表达分割、语义分割和实例分割;3D任务则聚焦于单目度量深度估计与表面法线估计。训练数据方面,2D任务利用了内部模型对网络图像生成的标注,3D任务则采用了渲染引擎生成的合成数据。
这里有个非常重要的细节:所有用于最终评测的基准数据集,其对应的训练数据都没有被混入指令微调的数据中。这意味着,我们看到的评测结果,更能真实地反映模型未经特定数据“污染”的通用泛化能力。
3.深度值到 RGB 的可逆双射
深度估计是论文中技术细节最密集的部分,也最能体现工程上的巧思。核心难题在于:深度值的范围是[0, ∞),而RGB值的范围是[0, 1]^3,如何在两者之间建立一个严格可逆的映射关系?
研究团队设计了一个两步走的方案。首先,对深度值进行幂变换,目的是拉高近距离物体的深度分辨率,同时压缩远距离的。这很符合直觉,比如在机器人抓取场景中,近处的物体显然更重要。接着,将归一化后的距离值,沿着RGB色彩立方体的边缘进行分段线性插值,其方式类似于3D希尔伯特曲线的首次迭代。
由于这两步变换都是严格可逆的,最终就构成了从深度值到RGB值的完美双射。训练时,将真实的深度图映射成RGB图作为监督目标;推理时,再将模型生成的RGB图反向解码,就能恢复出度量级的深度信息。
为了提升模型的鲁棒性,训练数据中还加入了Plasma、Inferno、Viridis、灰度等多种不同的色彩映射进行数据增强。值得注意的是,这个深度模型完全基于合成数据训练,没有使用任何真实世界的深度数据,并且在训练和推理过程中都不依赖相机的内外参数。
效果怎么样?
纸上谈兵终觉浅,是骡子是马还得拉出来溜溜。研究团队在2D分割、3D深度估计、表面法线估计这三类任务上,将Vision Banana与各个领域的专家模型进行了全面对比。结果如何呢?
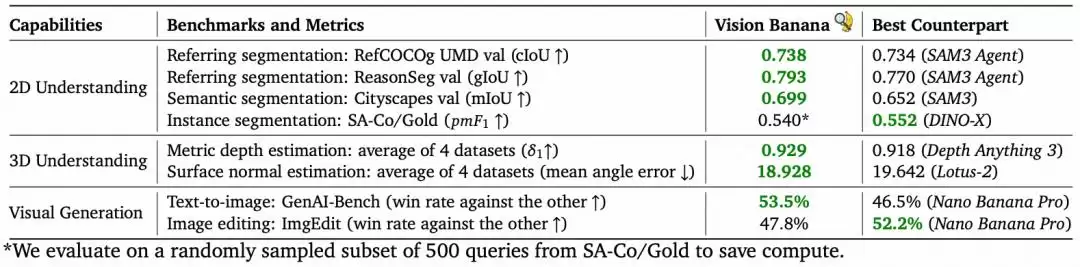
图|经过指令微调后,Vision Banana 在视觉生成与理解任务中的性能表现。
2D分割方面,表现堪称亮眼。在Cityscapes语义分割任务中,Vision Banana的mIoU达到了0.699,相比SAM 3的0.652提升了4.7个百分点,成为目前表现最强的开放词汇分割模型。在RefCOCOg指代分割任务中,其cIoU为0.738,也超过了SAM 3 Agent的0.734。在需要推理的ReasonSeg任务中,配合Gemini 2.5 Pro后,其gIoU达到0.793,高于SAM 3 Agent的0.770,甚至超过了在训练集上专门训练的X-SAM和LISA模型。唯一稍弱的是实例分割,在SA-Co/Gold数据集上的pmF1为0.540,略低于DINO-X的0.552。

表|Vision Banana 与各分割数据集上的 SOTA 方法的对比结果。
3D深度估计方面,优势更为明显。在6个主流基准测试上的平均δ1精度达到了0.882,比UniK3D提升了近6个百分点;AbsRel误差较MoGe-2下降了约20%。特别是在Depth Anything 3评测所使用的四个数据集上,Vision Banana的平均δ1为0.929,优于Depth Anything 3的0.918。
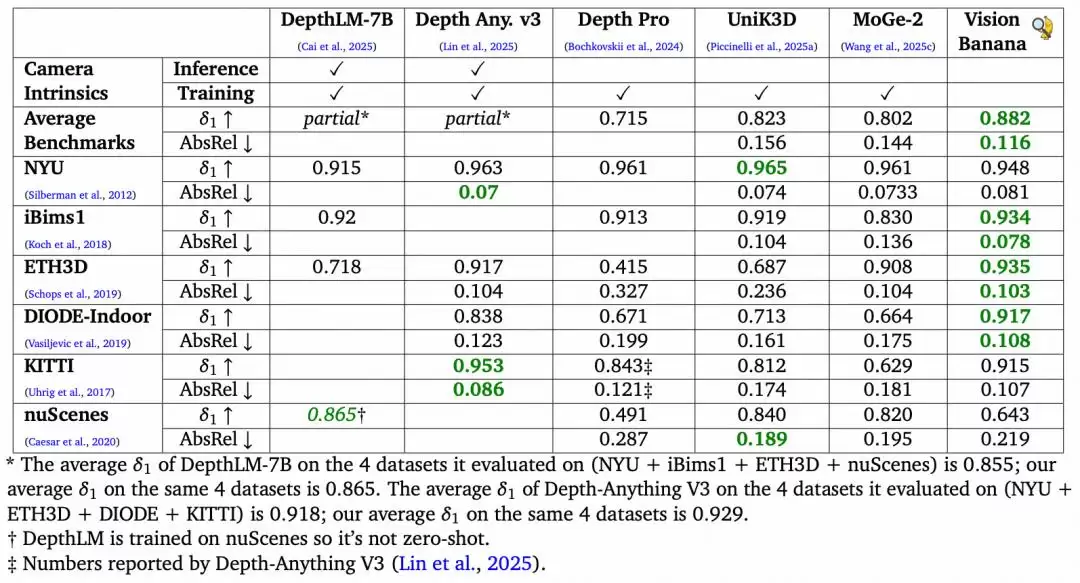
表|零样本迁移设置下的单目度量深度估计结果。Vision Banana 在训练和推理阶段均不使用相机内参的情况下,在公开数据集上取得了更优的结果。
表面法线估计方面,同样可圈可点。在三个室内数据集上,Vision Banana取得了最低的平均角度误差,均值和中值分别为15.549和9.300,优于Lotus-2的均值16.558。在户外VKitti场景中,其表现与Lotus-2基本持平。需要强调的是,Lotus-2曾在Virtual KITTI 2数据集上进行过训练,而Vision Banana始终保持严格的零样本设置。
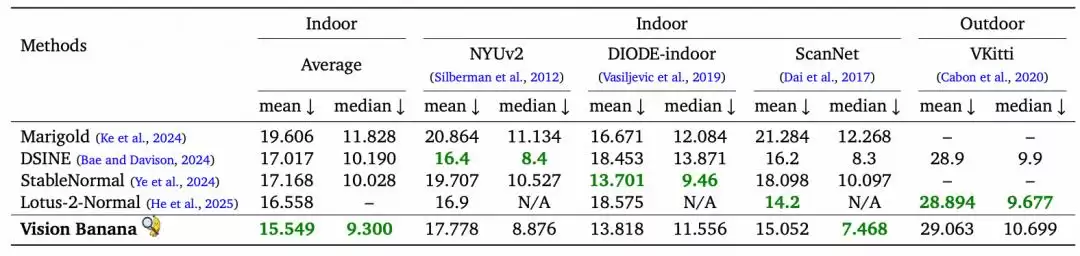
表|表面法线估计结果。Vision Banana 在室内数据集上平均取得了最低的均值和中值角度误差,并在室外场景上与此前的 SOTA 方法持平。
最后,大家可能最关心:加了这么多理解任务,它的“老本行”——图像生成能力还在吗? 测试给出了肯定的答案。在GenAI-Bench文生图对比中,Vision Banana相对于基础模型Nano Banana Pro的胜率为53.5%;在ImgEdit图像编辑任务中,胜率为47.8%。这表明经过轻量级的指令微调后,模型的生成能力依然保持稳定,没有被破坏。
还需要做什么?
当然,研究团队也清醒地指出,Vision Banana并非完美,仍有不少挑战需要在未来工作中攻克。
首先,实例分割性能仍有提升空间。如前所述,其在SA-Co/Gold数据集上的表现仍落后于SAM 3。论文分析认为,部分原因在于Vision Banana并未使用SA-Co数据进行训练,而SAM 3则基于此数据进行了优化。同时,实例分割任务本身也对当前“按类别指定颜色”的推理策略提出了挑战。
其次,计算开销是当前部署的现实瓶颈。使用NBP这样规模的图像生成器进行视觉理解,其推理成本目前仍高于轻量级的专用模型。如果希望大规模部署这种生成式视觉框架,进一步提升推理速度、降低计算成本是必经之路。
再者,任务的输入模态可以进一步拓展。目前的研究仅限于单张图像输入,未来可以探索多视角图像输入甚至视频输入。研究视频生成器是否能学习到更丰富的时间动态表征,是一个极具潜力的方向。此外,像大语言模型那样,扩大指令微调任务的多样性,或许能激发出模型更强的跨任务泛化能力。将强大的视觉基础模型与大语言模型协同集成,以增强复杂的跨模态推理,无疑是下一阶段的重要方向。
从更宏观的视角看,这项工作本质上是在尝试将大语言模型时代的成功范式——“预训练产出通用基座,指令微调将基座对齐到具体任务”——引入视觉领域。如果“生成图像”能够成为各种视觉任务的统一接口,那么“生成”与“理解”这两条曾经相对独立的研究路径,未来完全有可能汇聚到同一个强大的基础视觉模型之中。这或许为我们勾勒出了通向通用视觉智能的一条新路径。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

海康威视披露2025年报:营收超900亿元、净利大增近19%
海康威视2025年报解读:穿越周期,AIoT生态的韧性增长 近日,海康威视2025年的成绩单正式揭晓。报告显示,公司全年实现营业总收入925 08亿元,归母净利润则达到141 95亿元,同比增长18 52%。这份稳健的答卷,为市场注入了一剂强心针。 更值得关注的是2026年一季度的“开门红”:营收2

V8性能旗舰再进化 奥迪SQ8上市113.98万元
网易汽车4月24日报道 在2026北京国际汽车展览会上,一汽奥迪正式揭晓了旗下高性能旗舰——奥迪SQ8的上市价格,最新指导价定为113 98万元。这款车身上,凝聚了同级产品中愈发稀缺的V8机械底蕴,同时融合了动感流畅的Coupe车身设计。它并非简单的性能堆砌,而是将卓越性能、优雅格调与前瞻科技融为一

智能一切移动 卓驭科技发布首个原生多模态基础模型
网易汽车4月24日报道 2026年北京国际车展的大幕,在4月24日正式拉开。今年的舞台上,卓驭科技无疑是最受瞩目的焦点之一。以“智能一切移动”为主题,他们不仅带来了首个原生多模态基础模型,向核心媒体开放了实车体验,更系统性地展示了其“移动物理AI”技术路径下的最新成果——从乘用车、商用车到无人物流和

四维图新全栈量产方案及具身智能亮相2026北京车展
网易汽车4月24日报道 当智能网联汽车的竞争进入“决赛圈”,行业的主线已然清晰:国车加速出海,舱驾智能化快速渗透。在这个关键节点,2026(第十九届)北京国际汽车展览会上,四维图新以“智见新境”为主题,在首都国际会展中心A3馆展示了其AI驱动的全栈汽车智能化量产方案,并首次发布了其在具身智能新赛道的

英特尔称PC游戏性能差距主因软件优化不足,非硬件短板
英特尔称PC游戏性能差距主因软件优化不足,非硬件短板 四月底,英特尔副总裁罗伯特·霍尔洛克在一次访谈中,把PC游戏性能的话题摆上了台面。他的核心观点很明确:当前英特尔处理器在游戏场景下与竞品的表现差异,问题主要出在软件适配和优化这个环节,硬件设计本身并非短板。换句话说,潜力是有的,只是还没被完全“唤








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
