




2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%

阶跃星辰发布StepAudio 2.5 ASR:推理提速400%,长音频处理迎来新突破
4月24日,阶跃星辰正式推出了新一代自动语音识别模型StepAudio 2.5 ASR。这款模型主要瞄准语音转写与长音频处理场景,在架构上玩了个新花样——引入了Multi-Token Prediction(多Token预测)技术来提升推理效率,同时通过扩展上下文窗口,显著强化了对长内容的整体识别能力。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
官方公布的数据相当亮眼:推理速度提升了约400%,时延降低了60%,推理峰值能达到500 tokens/s,而成本则下降了80%。在多项公开测试集上,它也交出了错误率较低的答卷。
精度方面,阶跃星辰宣称StepAudio 2.5 ASR在多个主流评测基准上达到了业内领先水平。效率上,一段约5分钟的音视频能在较短时间内完成转写,并且支持一次性完整处理最长30分钟的音频。更引人注目的是其定价策略:StepAudio 2.5 ASR的服务费用定为0.15元/小时,这仅仅是其上代产品Step ASR 2价格的十分之一。
不过,技术指标是一回事,实际表现如何?在后续的测试中我们发现,模型对不同音频输入的适应性确实存在差异:部分上传的音频文件未能成功识别,而在实时录音场景下,它的表现则相对稳定,整体转写准确度较高。
一、不同模式下语音识别效果存在差异
在官方演示的场景里,面对大段连续的口述内容,StepAudio 2.5 ASR能够实现长时间的连贯输出。识别过程中,文本还原稳定,语义保持完整,长音频的转写质量表现得相当均衡。
不仅如此,模型对复杂语境的适配能力也更强了。无论是日常高频的中英混杂表达,还是像绕口令这种发音紧凑、咬字复杂的特殊语句,它都能稳定完成精准识别与完整转写。看得出来,其抗干扰能力和语言包容性确实有了进一步提升。
▲阶跃星辰官方演示
我们也依托阶跃星辰的在线体验平台做了实测,特意选取了一段张雪峰老师的高考志愿填报课程录音作为测试素材,重点检验模型在长音频场景下的真实识别能力。
这个上传模式主要面向会议纪要整理、采访录音转写、课程内容归档等场景,支持WA V、MP3、OGG、PCM等主流格式,单文件大小不超过20MB,同时支持中文、英文及中英混合识别。
但有意思的是,在多次上传同一段音频后,系统均提示“未检测到清晰语音”,未能完成有效转写。具体原因目前尚不明确。
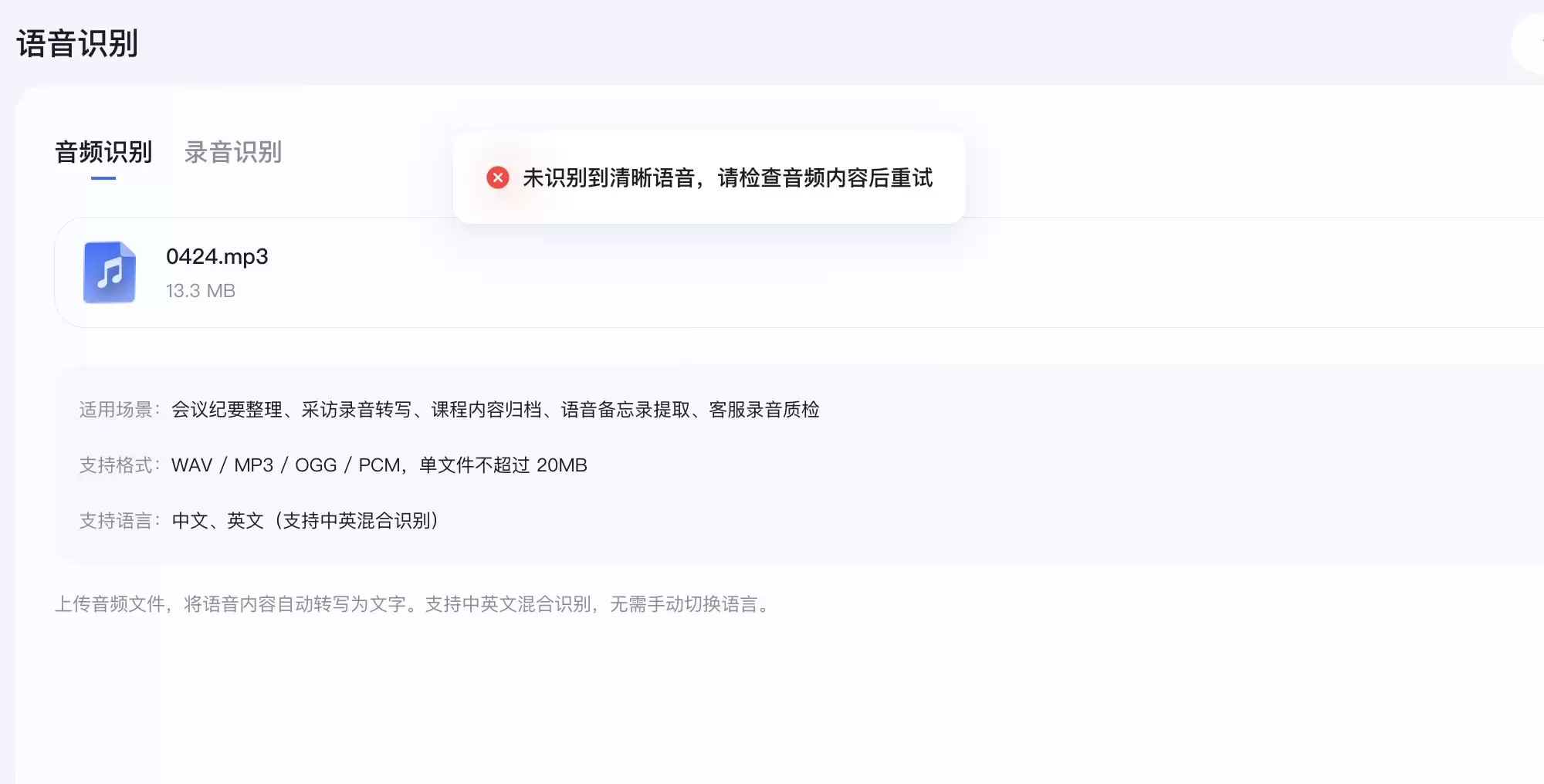
随后,我们切换到了现场录音模式进行测试。这个模式更适合快速语音备忘、现场会议记录等场景,同样支持中英文及混合识别,但单次录音时长上限为2分钟。
这次的识别结果如下:

在这个场景下,模型表现正常,整体转写结果较为准确,对口语内容的还原度很高。关注几个细节:当说话人出现较长停顿时,模型会自动插入额外的逗号进行分割;同时,算法完整保留了日常口语中自然的重复、口头复述等特征,相当真实地还原了原始的语言状态。
二、Multi-Token Prediction优化推理效率
StepAudio 2.5 ASR这次的一个核心亮点,是将Multi-Token Prediction技术引入了语音识别赛道。它沿用了Step 3.5 Flash的同款技术方案,采用Audio Encoder+Linear Adapter+LLM+MTP-5的融合架构,从根本上打破了传统串行输出的限制。
简单来说,这个模型可以单次预测多组候选Token,再结合并行验证机制快速输出识别结果,从底层架构上优化了推理效率。
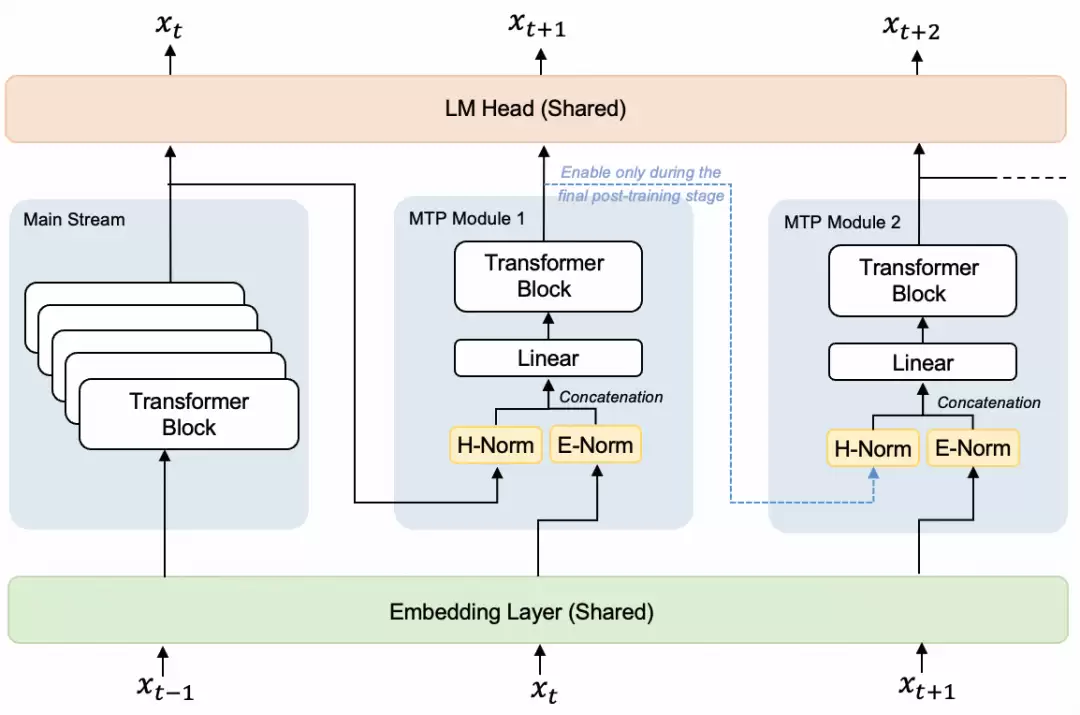
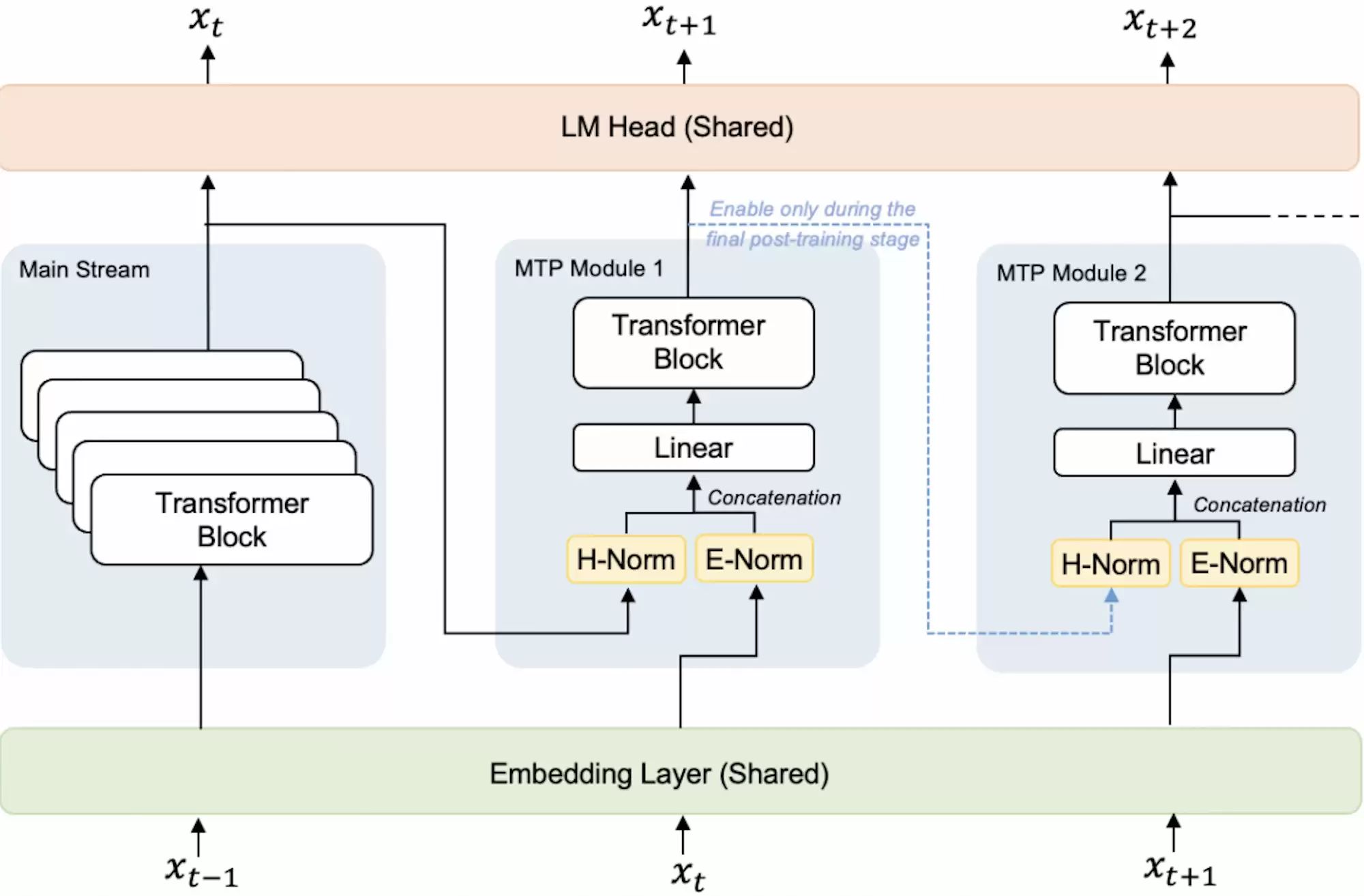
官方实测数据显示,对比传统识别方案,该模型推理速度提升400%,整体时延压缩60%,推理运行成本下降80%,峰值推理速率可达500 tokens/s。这对于提升音视频转写的实时性和性价比,意义重大。
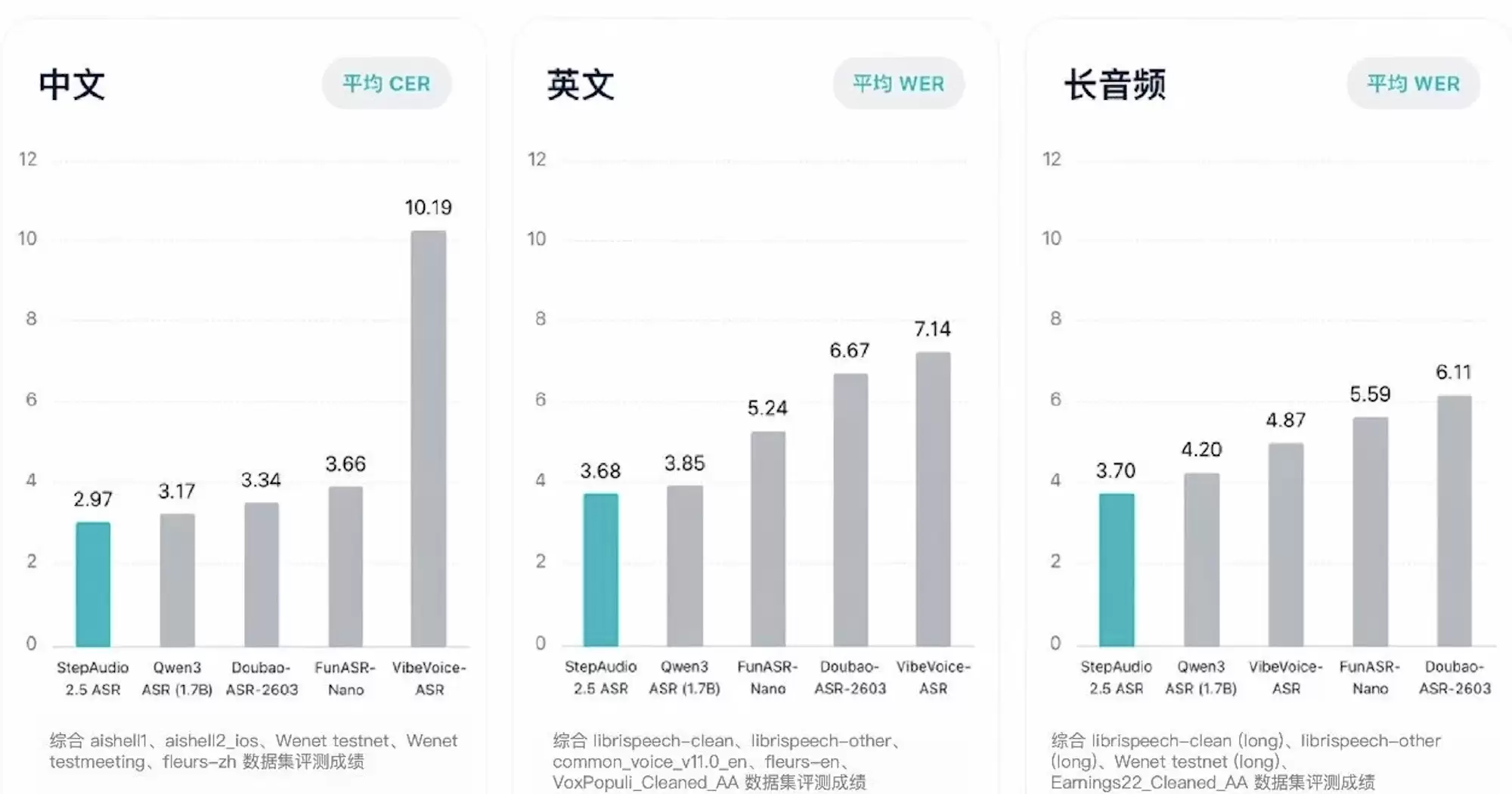
在推理效率的横向对比上,阶跃星辰官方数据显示,StepAudio 2.5 ASR的表现高于Qwen3 ASR(1.7B)、FunASR-Nano、Doubao-ASR-2603等模型。

长音频处理一直是语音识别行业的痛点。目前主流方案多采用先将音频切片、分段识别、最后再拼接的处理模式。但切割后的片段相互独立,容易造成上下文信息割裂,处理长内容时常常出现语义断层、信息遗忘等问题。
对此,StepAudio 2.5 ASR复用了LLM原生的32K上下文窗口能力,支持端到端一次性处理最长30分钟的连续音频,无需分段切割,全程保留完整的上下文关联。这很好地保障了长时段对话、会议、访谈等场景下的识别连贯性。
识别精度层面,该模型在多组权威公开数据集中表现稳定。在LibriSpeech clean/other等五组主流英文开源测试集里,其词错误率优于同期同类模型,能够以更低的算力消耗实现更高质量的转写效果。
针对30分钟满负荷长音频的专项测试显示,模型识别精度始终维持在行业顶尖水平,没有出现长文本识别中常见的精度逐级衰减问题,长时序内容识别的稳定性得到了显著提升。
结语:关键指标提升,真实场景仍是考场
整体来看,StepAudio 2.5 ASR的改进确实抓住了当前语音识别系统的关键:推理效率与长上下文建模能力。速度、成本、长度,这些硬指标上的提升有目共睹。
但话说回来,从实测情况看,模型在不同音频输入条件下的稳定性仍有提升空间。尤其是在面对复杂或非标准音频时,其适配能力如何,仍有待更多真实场景的锤炼和第三方评测的进一步验证。实验室里的高分,终究要在现实世界的考场里接受最终检验。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

欣旺达北京车展秀实力:“欣星环”电池发布,“能量家生活馆”引领新能源生活
在2026北京车展,欣旺达动力如何诠释“全场景”电池时代? 今年的北京国际汽车展览会,欣旺达动力(SEVB)的展台有点不一样。他们以“用心做好每一块电池,陪伴生活每一刻精彩”为主题,带来的不仅是一系列产品,更是一套覆盖从出行到生活的全场景能源解决方案。这无疑向行业和公众清晰地展示了,这家企业在新能源

2026年AI编程工具对比:谁最值得用?
全球主流AI编程工具横评:如何根据你的需求与水平做选择? 在AI编程工具这个赛道上,不同产品的定位和上手难度差异巨大。今天,我们就来盘一盘市面上几款主流的工具,你可以根据自身的预算和技术栈,找到最适合自己的那一款。 1 Claude Code (CC):能力顶尖,门槛也最高 提到AI编程,Clau

京津冀携手共进!智能网联新能源汽车生态港车展绽放新光彩
在正在顺义举办的第十九届北京国际汽车展览会上,京津冀智能网联新能源汽车科技生态港主题展区成为全场瞩目的焦点 这个面积达700平方米的展区,以六大功能区的联动展示,汇聚了百余家企业的创新成果,生动呈现了京津冀三地汽车产业链协同发展的丰硕成果。 整个展区以“链群同心、澎湃生机、携手共进、生态共创、未来同

2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
阶跃星辰发布StepAudio 2 5 ASR:推理提速400%,长音频处理迎来新突破 4月24日,阶跃星辰正式推出了新一代自动语音识别模型StepAudio 2 5 ASR。这款模型主要瞄准语音转写与长音频处理场景,在架构上玩了个新花样——引入了Multi-Token Prediction(多To

火山引擎北京车展推新一代汽车AI方案 豆包大模型赋能超700万智能汽车
在北京车展首日,火山引擎正式推出基于Agentic AI架构的新一代汽车AI解决方案 车展首日,一个重磅消息传来:火山引擎正式发布了基于Agentic AI架构的新一代汽车AI解决方案。这套方案包含两大核心模块——AI座舱套件方案与豆包座舱助手方案。其真正的突破性在于,它构建了行业首个全链路端到端的








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
