




AI产业链革命新阶段谁能主导Context内存战争王座

最近在开发一个Multi-Agent(多智能体)投研系统时,遇到了一个颇为棘手的问题:一份真正复杂的研报,生成过程经常要耗费数小时,甚至一整夜。当Tokens消耗量攀升至数万级别后,响应时间会急剧增加,复杂的分析任务甚至可能卡顿一小时以上。 尤其是在多Agent协同、工具链调用、长上下文推理和结构化
最近在开发一个Multi-Agent(多智能体)投研系统时,遇到了一个颇为棘手的问题:一份真正复杂的研报,生成过程经常要耗费数小时,甚至一整夜。当Tokens消耗量攀升至数万级别后,响应时间会急剧增加,复杂的分析任务甚至可能卡顿一小时以上。
尤其是在多Agent协同、工具链调用、长上下文推理和结构化对抗分析这些场景同时发生时,延迟会变得格外显著。
起初,问题似乎指向了“算力不足”。然而,在检查资源使用情况时,发现LLM服务的请求配额并未打满,也没有出现连接错误。问题的根源,可能已经超出了GPU本身的计算范畴,指向了AI处理超长上下文时引发的系统级阻塞。
更准确地说,瓶颈在于“内存”,或者说,是大模型卡在了“数据搬运(Data Movement)”这一环节。
而近期资本市场与AI基础设施领域的一些变化,其实已经提前预示了这一点。
一、AI产业正在进入一个关键的新阶段
过去两年,整个行业都在疯狂追逐GPU算力。但现在,一线工程师们察觉到了一个微妙的变化:在许多AI系统中,GPU的算力尚未满载,内存却已率先告急。于是,上下文(Context)管理成为了系统工程中至关重要的一环。
这背后揭示了一个历史性的趋势:AI的核心瓶颈正在发生转移,从以计算为中心(Compute-centric)转向以内存与数据移动为中心(Memory-centric)。
如果说2023-2025年的主线是“GPU算力革命”,那么2026-2028年很可能将步入“内存架构革命(Memory Architecture Revolution)”。
而这场革命最核心的关键词之一,便是:CXL(Compute Express Link)。
二、为什么AI突然开始“极度缺内存”?
2026年5月,华尔街被存储芯片板块的疯狂涨势彻底震撼。
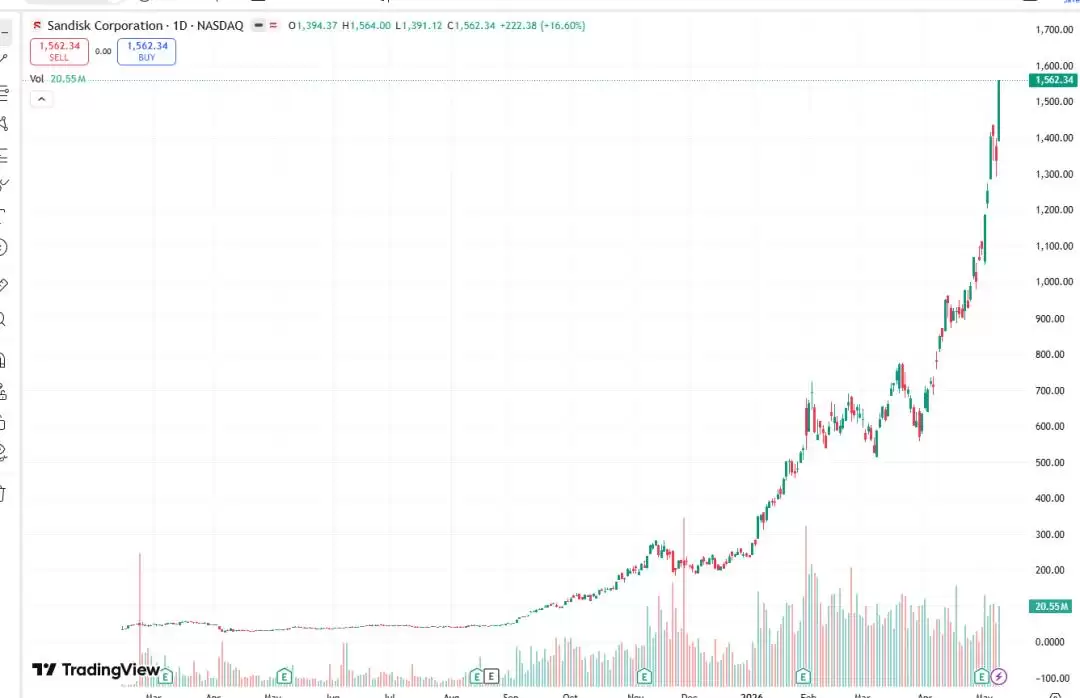
美光科技(MU):过去12个月股价飙升700%,市值一举突破8400亿美元;西部数据(WDC):一年内暴涨900%;闪迪(SNDK):更是上演了上市以来涨幅超3300%的造富神话,单日暴涨16%直接突破1560美元。
无数踏空的投资者在深夜懊悔:为何又一次错过了利润可能更为丰厚的内存浪潮?
答案或许在于,思维仍停留在“AI = 算力 = GPU”的旧有共识里。
这波存储股的爆发,只是向市场揭开了残酷真相的一角:AI系统真正面临的致命瓶颈,早已不是算力,而是“内存墙(Memory Wall)”。
许多人看到NVIDIA新一代GPU的192GB HBM时,会产生一种错觉:“如此庞大的容量,为何还不够用?”
关键在于:AI推理阶段如黑洞般吞噬内存的,往往并非模型参数本身,而是KV Cache。
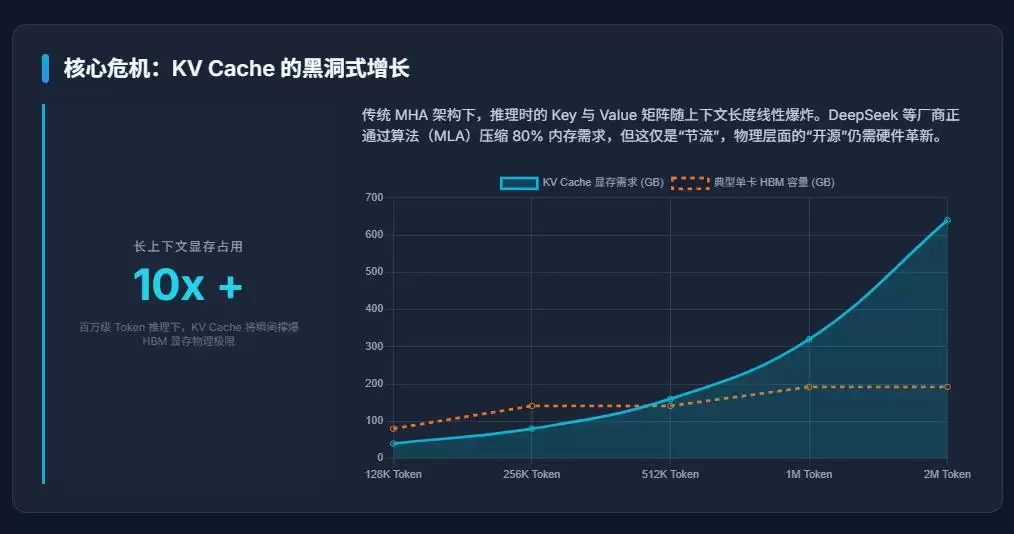
这是当前二级市场最容易忽略的核心问题。
什么是KV Cache?简而言之,大模型在推理生成每一个Token时,都需要保存对应的Key和Value向量,用于后续的自注意力(Attention)计算。上下文越长,需要缓存的KV就越多。
而当前AI行业正同步发生的趋势——长上下文、多智能体、持续会话、实时推理、高并发——所有这些都会导致KV Cache呈爆炸式增长。
一个700亿参数级别的模型,在处理百万Token级别的上下文,并叠加高并发请求时,KV Cache很容易瞬间膨胀至数百GB,甚至TB级别。
问题随之而来:你不可能将所有数据都塞进昂贵且有限的HBM里。
三、HBM的致命短板:太快,也太贵
近期内存股涨价的核心驱动力是HBM(高带宽内存)。HBM性能确实卓越,但它更像是城市里的“顶级学区房”。
它存在几个关键短板:
- 成本极高
- 功耗巨大
- 容量扩展极其困难
- 严重受制于CoWoS等先进封装的产能
顶级学区房固然好,但不可能让所有数据都住进去,否则AI公司的推理成本将直接失控。
于是,AI系统被迫进入“分层内存时代”。未来的AI内存架构,大概率会呈现如下形态:
- 第0层(HBM):超高速、超昂贵(存放最核心的即时计算数据)
- 第1层(DDR5 / CXL Memory):大容量、高性价比
- 第2层(NVMe / SSD):容量更大、速度更慢
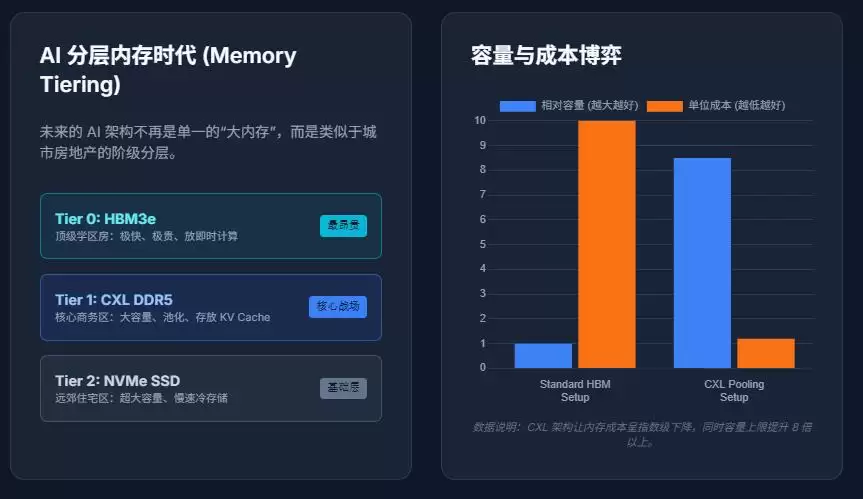
这意味着,未来AI系统的核心考验,将不再是单纯的“能否买到GPU”,而是:“哪些数据必须放在最快的内存里?”以及“如何最大限度地降低数据在各层内存间搬运的成本和延迟?”
四、NVIDIA:从FLOPS转向Data Movement
过去几年,整个AI行业都在比拼FLOPS(每秒浮点运算次数)和GPU数量。
但现在,如果仔细观察英伟达近期的动向,会发现其越来越频繁地强调:
- 上下文内存(Context Memory)
- 共享内存(Shared Memory)
- 机架级架构(Rack-scale Architecture)
在GTC 2026上,NVIDIA已经明确提出了POD-wide context memory(即整个机架/POD级别的共享上下文内存)概念。
英伟达的Grace-Blackwell (GB200)架构,本质上是将CPU和GPU通过超高带宽的NVLink-C2C紧密耦合。其Grace CPU天生就是为了高效管理HBM和共享内存池而设计的。它不再单独售卖CPU,而是提供一整套“CPU+GPU+内存互连”的全栈解决方案。
这标志着,AI基础设施的焦点已经开始从以GPU为中心转向以上下文为中心。行业终于意识到:算力再强大,如果数据搬不动、搬不快,也是徒劳。
五、CXL到底改变了什么?解决“搁浅内存”与“NVLink垄断”
过去几十年的服务器架构是高度绑定的:CPU绑定自己的DRAM,GPU绑定自己的HBM。各自为战,资源难以灵活借用。
这导致了一种严重的资源浪费现象:GPU-A的HBM可能已被KV Cache撑满,而邻近GPU-B的内存却处于闲置状态。由于无法动态共享,这些闲置的内存变成了极其昂贵的“搁浅内存(Stranded Memory)”。
那么,前面提到的英伟达NVLink-C2C不是已经解决互联问题了吗?为什么还需要CXL?
这是一个非常好的问题。答案是:两者定位根本不同。
NVLink是英伟达为自己修建的“私家高铁”。速度极快,但你必须购买其全套方案,将所有计算牢牢锁定在英伟达的封闭生态内。它解决的是大模型暴力计算的“算力上限”问题。
而CXL(Compute Express Link),则是AI时代的“通用货运网络”。它是由Intel、AMD、Google、Meta等全行业巨头共同推动的开放标准。其核心使命并非帮助某一家公司提升算力峰值,而是解决全行业共同的噩梦——内存墙。它解决的是AI商业化落地的“成本下限”问题。
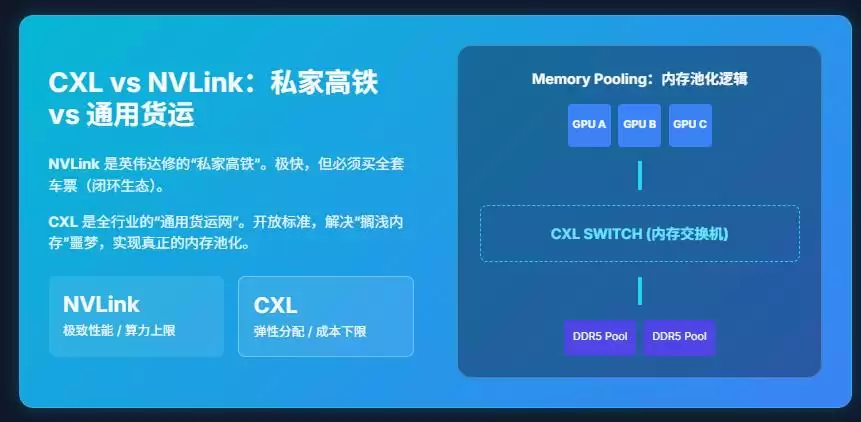
CXL带来了一个关键概念:内存池化(Memory Pooling)。
过去,每台服务器像一栋拥有独立水塔的别墅;未来,通过CXL,整个数据中心将变成一个共享的供水网络。无论你使用的是哪家的CPU或GPU,都可以动态接入并共享一个庞大的外部内存池。谁需要数据,资源就流向谁。
最终,云端算力的内存可以像水电一样灵活支取,按需分配。
六、有了DeepSeek v4这种算法压缩,还需要CXL吗?
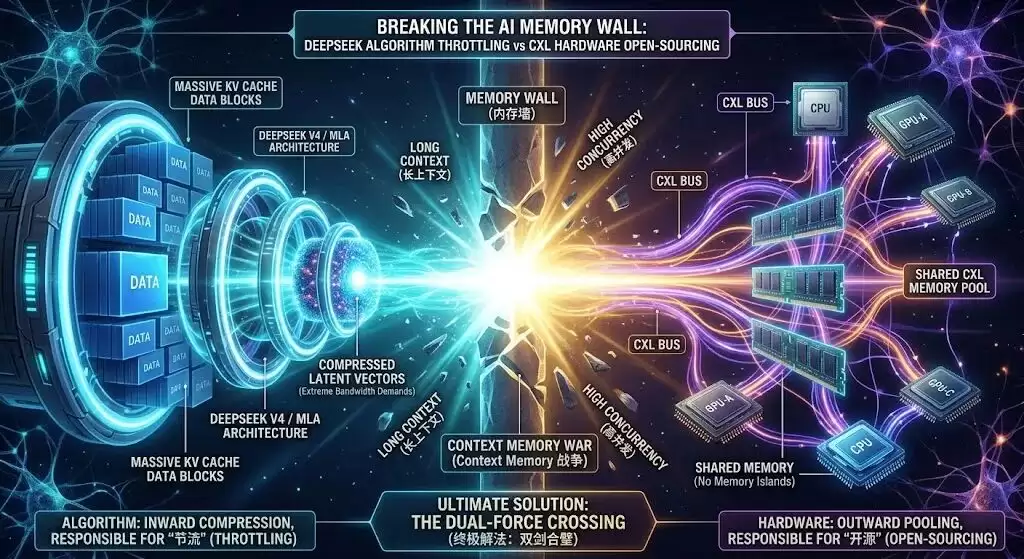
看到这里,许多技术背景的朋友可能会提出一个尖锐的问题:
“前段时间DeepSeek v4发布,不是通过其首创的MLA(多头潜在注意力)架构,将KV Cache的显存占用硬生生降低了80%到90%吗?”
既然算法能在物理层面将内存压缩到如此之小,为什么还需要极其复杂的CXL硬件池化?
这是一个极佳的思考。但真相是:DeepSeek的算法压缩与CXL的硬件池化,绝非互斥关系,而是攻克AI“内存墙”的两条完美交叉的路径。
第一,DeepSeek本质上是“用极致的计算和带宽,换取内存空间”。MLA架构将庞大的KV矩阵压缩成极小的潜在向量(Latent Vector)。但在计算时,模型必须极高频率地“解压缩”还原。这依然对显存带宽(Bandwidth)和互联速度提出了恐怖的要求。算法压缩到了极限,实际上是对数据传输带宽的极度压榨。
第二,物理极限与系统级死锁。即便DeepSeek将KV Cache砍掉了90%,当处理数百万Token的超长文本、且面对数万并发请求时,剩下的那10%依然可能撑爆单机HBM的容量天花板。更致命的是:GPU-A节省下来的闲置内存,依然无法直接给旁边的GPU-B使用。
因此,未来的终局形态很可能是:算法(向内压缩)负责“节流”;CXL(向外池化)负责“开源”。
这两者的“双剑合璧”,才是彻底跨越“上下文内存战争”的终极解决方案。
七、反直觉:CPU正在迎来“结构性复兴”
看到这里,可能会产生一个错觉:AI时代,传统的CPU是否彻底沦为配角?
恰恰相反。在CXL硬件池化和DeepSeek v4高效算法的双重催化下,CPU的重要性正在被史诗级重估。
如果说GPU是AI时代的“暴力肌肉”,那么在这个庞大的CXL共享内存网络中,CPU正在重新夺回其“神经中枢”的王座。
原因很简单:
第一,谁来充当海量内存池的“超级交警”?在CXL时代,所有GPU和海量外部内存连接成一片网络。GPU A的闲置内存如何动态借给GPU B?热数据何时切入HBM?这种极其复杂的内存编排调度(Memory Orchestration)和多租户一致性管理,GPU本身并不擅长。它必须依赖拥有高I/O带宽和复杂调度逻辑的“重型CPU”来执行。
第二,算法压缩倒逼KV Cache下放。既然DeepSeek将KV Cache的体积大幅压缩,我们为何非要将它们全部挤在昂贵的GPU HBM里?完全可以将这些海量的上下文记忆,存放在由CPU掌控的庞大DDR5/CXL内存池中。GPU专注于埋头计算,CPU则负责高速调取和维护这些上下文。
AI的下半场,对CPU的要求并未降低,而是发生了深刻的“职能升级”。那些拥有强大调度架构的高级CPU,其价值将面临重构。
目前的趋势显示:ARM架构正在全面挑战x86的传统地位。
功耗是死xue:AI机柜的功耗已逼近物理极限(单柜120kW以上)。x86复杂指令集在能效比上天生处于劣势,而ARM架构在处理高频、并行的I/O调度任务时,能节省巨额电费。
定制化是绝杀:云巨头(AWS, Google, Microsoft)如今都在自研CPU。基于ARM的IP授权,他们可以像搭积木一样,定制出最适合CXL链路和DeepSeek算法需求的私有CPU(如Gra viton系列)。
未来的王者,或许不再是那个“算力最强”的,而是那个“最懂得调度内存”的。
八、寻找真正的Alpha:产业链里的“四大关键节点”
当AI基础设施的重心发生偏移,真正的利润池,将开始向“数据搬运(Memory Movement)”领域疯狂迁移。
不必再仅仅盯着GPU和CUDA。在即将到来的CXL内存池化时代,以下四个环节,才是未来三年更具潜力的“卖水人”:
1. Retimer(高速信号修复芯片):最先爆发的物理刚需
随着PCIe 5.0/6.0和CXL传输速度的翻倍,高速信号在物理主板上极易衰减失真。Retimer就像是内存长途运输线上的“加油站与信号放大器”。在未来的机架级AI服务器中,它是绕不开的物理标配。
核心标的:Astera Labs (ALAB)、Credo Technology (CRDO)
2. CXL Switch(价值咽喉):AI时代的“内存交换机”
未来,GPU不再固定“焊死”在特定内存上,而是通过CXL Switch动态连接整个内存织物。谁能实现超低延迟、高一致性的内存交换,谁就扼住了AI数据网络的咽喉。这是整个硬件链条中溢价最高、壁垒最深的环节之一。
核心标的:博通 (A VGO)、Marvell (MRVL)。
3. 被重估的CPU层:统筹全局的“总指挥部”
传统认知中,CPU在AI时代被边缘化了。但事实是,在CXL时代,CPU成了统御庞大内存池的“总调度交警”。现在的投资Alpha,不再只看CPU的单核算力,更要看其I/O通道数、低功耗表现以及内存调度效率。
- 蓝图统治者:Arm Holdings (ARM)。云巨头抛弃x86自研芯片(如AWS Gra viton),均需向ARM支付架构授权费。
- 定制化推手:世芯电子 (3661.TW)、Marvell、博通。他们是帮助巨头们代工设计AI芯片的幕后关键角色。
- x86的坚守者:AMD (AMD)。凭借极高的I/O通道数和激进的CXL拥抱策略,其EPYC处理器依然是公有云市场的硬通货。
- 反直觉的赢家:Intel (INTC)。即便在核心设计上面临挑战,凭借其独家的EMIB先进封装技术(通过IFS代工服务),它依然是云巨头制造芯片时难以绕开的重要合作伙伴。
4. Memory Controller & Orchestration:真正的软件护城河
将海量内存连接起来只是第一步。真正困难的是“如何高效调度这些共享内存”。这涉及到极度复杂的操作系统支持、工作负载迁移和多租户隔离。这不仅是硬件问题,更是软件生态问题。
核心标的:Rambus (RMBS)。
生态玩家:那些能够研发出类似Meta TMO(透明内存卸载)底层软件栈的科技巨头。谁能做好内存编排,谁就能建立起媲美英伟达CUDA级别的“内存软件护城河”。

结语
30年前,互联网解决的是:“计算机之间的数据共享”;
20年前,云计算解决的是:“计算资源的弹性分配”;
5年前,大模型解决的是:“海量参数的注意力分配”;
1年前,智算中心解决的是:“万卡集群的算力洪流分配”;
而今天,我们正在攻克AI皇冠上的最后一颗钉子:“AI芯片之间的全域内存共享”。
当你还在为某个AI Agent运行缓慢而抱怨算力不足时,当你还在紧盯英伟达的股价猜测其天花板时,另一场更底层、利润结构可能更丰厚的系统级架构变革,或许已然拉开序幕。
AI的下一阶段,也许不再只是“算力战争”,而是“上下文内存战争”。
本文内容不构成任何投资建议。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

先导智能交付海外首条全极耳圆柱电芯产线助推欧洲豪车电气化转型
先导智能成功交付海外首条全极耳圆柱电芯产线,用于欧洲顶尖豪华车品牌德国诺德林根电池工厂。产线搭载自研智能系统,实现单电芯100%在线溯源,AI视觉检测识别潜在风险,焊接不良率和运营成本均降低30%。

八位堂Xbox机械键盘新版新增RGB背光
八位堂推出Retro87机械键盘Xbox版,采用初代Xbox透明绿外壳,首次加入RGB背光,提供八种模式。键盘为87键布局,搭载凯华JellyfishX开关,内置2000mAh电池,续航达200小时。同步发布RetroR8鼠标,配备PAW3395传感器和充电底座。键盘现已在亚马逊开启预售,售价119 99美元,2025年1月16日发货。

天硕V60 256GB SD卡 高速稳定的卓越品质 开启存储新境界
天硕V60256GBSD卡具备256GB容量,读取260MB s、写入150MB s,支持4K60P视频录制。采用长江存储闪存与自研主控,达到IP68三防等级,兼容主流相机,集成纠错编码与磨损均衡技术,为专业影像创作提供可靠存储方案。

i扫地机器人全球热销 高端市场占有率30%
杉川机器人全球高端扫地机器人市场占有率达30%,获广东省制造业单项冠军。公司全球出货超千万台,拥有多项专利。其净水循环与空气制水技术实现终生不用加清水、倒污水,突破传统使用瓶颈。

荣耀笔记本X Plus系列全新配色定档12月2日
荣耀笔记本XPlus系列将于12月2日发布,推出浅海蓝新配色,搭配银色品牌标识,主打轻薄机身。该系列首发搭载酷睿第二代英特尔酷睿5处理器,续航提升。荣耀CEO预告明年将全面布局PC领域。同期荣耀300系列也将发布。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















