




上海爱马仕模型调用量首超龙虾跻身全球前五



全球大模型社区的竞争格局近期出现显著变化。5月9日至12日,开源AI智能体框架Hermes Agent(业内昵称“爱马仕”),在OpenRouter平台的智能体调用量排行榜上连续三天超越此前长期领先的OpenClaw(俗称“龙虾”),引发广泛关注。
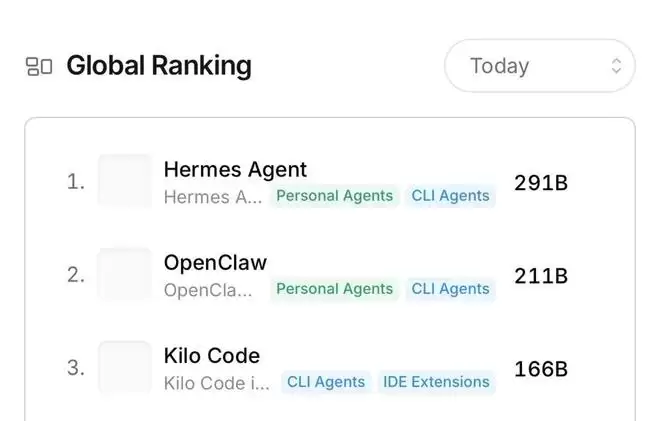
这场“爱马仕”与“龙虾”的榜首之争,标志着新一轮“养马热”的兴起。数据显示,“爱马仕”的累计词元消耗量已突破6.72万亿,增长势头迅猛。当前,OpenRouter智能体调用量前三名分别是“爱马仕”、“龙虾”和Kilo Code(基洛代码)。更值得关注的是,支撑这三个热门智能体的基座模型榜单中,来自上海的大模型表现尤为突出。
具体而言,在“爱马仕”调用量榜单前五名中,上海基座模型占据两席,分别来自MiniMax和阶跃星辰;在“龙虾”的榜单上,这两家上海模型也曾先后登顶;而在专业编程智能体Kilo Code的调用榜单中,前三名更是被上海基座模型包揽:阶跃星辰Step 3.5 Flash、稀宇科技MiniMax M2.5、蚂蚁百灵Ling-2.6-1T。这一现象清晰地表明,在追求极致“词元效率”的当下,大模型的竞争焦点正从单纯的参数规模,转向高兼容性与协同作战能力。
“养马”先机:当智能体具备自学能力
“爱马仕”为何能异军突起?本质上,它与“龙虾”同属开源AI智能体框架,支持本地或云端部署,允许用户自由选择大模型和工具来完成任务。但其核心优势在于具备“自学”能力——完成复杂任务后,它能自动提炼出可复用的“技能”,并在后续任务中智能调用、持续优化,如同一个不断积累经验的AI助手,越用越聪明。
正是洞察到这种潜力,MiniMax和阶跃星辰在“爱马仕”初露锋芒时便率先接入支持,推出了MaxHermes等相关产品,抢占了“养马”的先发优势。如今,这两家公司的模型依然稳居全球调用榜前列,且增长态势强劲。对于这种早期布局,阶跃星辰首席技术官朱亦博表示,这更像是对智能体时代趋势的精准预判。要最大化发挥“爱马仕”这类智能体的效能,离不开一个响应迅速、成本可控且足够聪明的“大脑”。以阶跃星辰最新的Step 3.5 Flash模型为例,其在推理速度、工具调用和长链条任务处理上做了针对性强化,力求在成本与效能间找到最佳平衡点。MiniMax的产品策略也与此高度一致,其产品负责人指出,长时间稳定运行、高频工具调用和复杂指令遵循是智能体的共同基础需求,也自然成为模型持续优化的核心方向。
“霸榜”前三:专业化与生态化的双重胜利
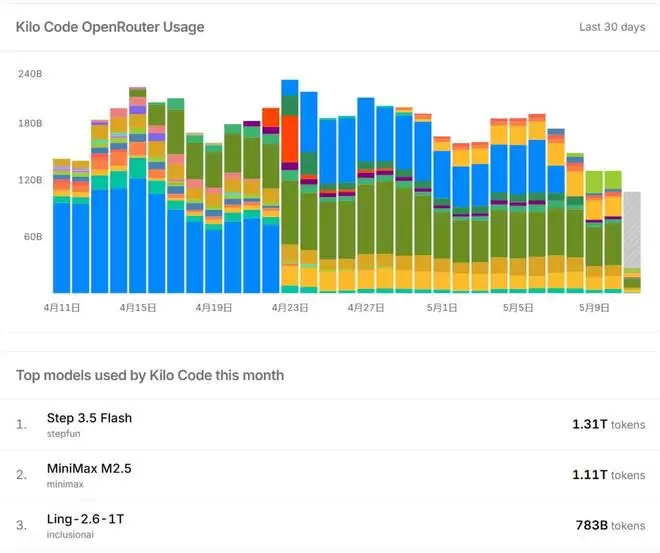
除了在通用智能体赛道表现亮眼,上海大模型在垂直专业领域同样展现出强大实力。排名第三的Kilo Code是一个专为代码生成而设计的智能体,目标极其聚焦。在其调用量榜单上,上海模型包揽前三,堪称“霸榜”。这种成功并非偶然。蚂蚁百灵大模型技术专家指出,开发者的诉求非常实际:代码生成是否准确、工具调用是否稳定、复杂任务能否顺利执行、成本是否划算。为满足这些需求,百灵大模型在指令执行、工具适配、长上下文处理等工程能力上进行了系统化优化。
更重要的是其差异化路线。据悉,百灵大模型在训练时并未盲目追求“大而全”,而是集中资源专攻编码赛道。这种专注使其在多项国际权威代码榜单中达到了开源第一梯队的水平,构成了开发者信任与使用的基础。上海市人工智能协会秘书长钟俊浩从宏观视角补充道,上海大模型能在OpenRouter等全球社区脱颖而出,除了性价比优势,国际化的工程能力和积极的开源策略功不可没。良好的云服务兼容性,加上开源带来的丰富开发者生态,将模型选择权交还给开发者,反而激发了更高的使用意愿和活跃度。
持续“进化”:从单体智能迈向群体协作
AI智能体正从简单的“内容生成”迈向复杂的“行动执行”,这对底层模型的性能提出了更高要求。一个明显趋势是,多智能体协作日益普遍,不同模型常被同时调用。因此,兼容性已成为影响大模型调用量的关键指标之一。目前,MiniMax、阶跃星辰等上海模型都高度兼容主流国际框架,极大降低了开发者的接入门槛。
北京智源人工智能研究院的倪贤豪指出了智能体发展的下一阶段特征:从“单体智能”走向“群体智能”。其核心逻辑在于,即便单个智能体的准确率有限,但只要足够多的智能体能够高效协作、错误互异,整个集成系统的综合准确率就能实现质的飞跃。
从OpenRouter的榜单变化不难看出,“效率”正成为上海大模型的核心竞争力。这种效率体现在多个维度:例如,MiniMax M2.7模型具备自我“进化”能力,能调用多种工具完成复杂任务,并原生支持主流智能体框架。阶跃星辰的Step Image Edit 2图像模型,仅以35亿参数实现了媲美200亿参数模型的性能,图片生成仅需0.5至2秒。蚂蚁百灵Ling-2.6-1T则在一次评测中,仅用1600万输出词元就完成了同类模型需要5000万以上词元才能完成的任务,词元效率优势突出。
当然,挑战依然存在。如何在智能体时代让每一分词元都物尽其用,保证结果交付既高效又可靠,是模型需要持续优化的方向。正如蚂蚁数科技术专家谢辛所言,降低词元消耗仍是关键。阶跃星辰朱亦博也透露,下一步将重点强化模型的工具调用与长程任务执行精度,并推出完整的模型矩阵,以适配更多元化的终端与应用场景,在智能体验与性价比之间找到更优解。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

国内首批智能体国标发布,AI应用从验证迈向规模化
国内首批智能体国家标准正式发布,这一消息在人工智能领域引发广泛关注。简单来说,这份标准为智能体技术确立了 "定义 ",明确了分类体系、技术指标与测试方法,相当于为整个行业制定了统一规范。这意味着什么?这意味着智能体技术将告别 "野蛮生长 ",迎来标准化发展,加速其在工业制造、智慧服务、智能家居等场景的落地应

微星40周年限量游戏本开售 5090+96GB 55999元起
值得关注的是,微星在成立40周年之际,特别推出了限量典藏版机型——泰坦18 Ultra龙魂典藏版2026款游戏本,已于昨日零点正式开售,官方定价为55999元。此外,部分地区还可叠加国家补贴,实际到手价可低至54499元。 作为40周年专属纪念款,其外观设计自然独具匠心。机身正面采用金属蚀刻与阳极氧

墨刀原型强调交互高保真真机演示,产品流程从草图到协作评审
原型工具究竟在解决什么问题?这个问题其实很值得探讨。不少人听到“原型设计”,第一反应往往是绘制几张静态页面、添加几个页面跳转链接,但实际的产品流程远比这复杂。墨刀在“墨刀原型”的官方说明中,将重心放在原型设计、交互、高保真和真机演示这几个核心能力上。换句话说,它并不满足于让团队只输出页面静态图,而是

保时捷Taycan最后两款旅行车宣告停产
保时捷正式为两款纯电旅行车系列画上终止符。据海外汽车媒体motor1报道,Taycan Sport Turismo与Taycan Cross Turismo已经停止生产。随着2027款全新纯电Taycan的推出,这两款衍生车型将从产品阵容中完全移除。保时捷官方确认,此次停产的根本原因非常明确——实际

墨刀白板助力市场洞察需求梳理,多工具看板服务产品评审共创
首先提出一个关键判断:在产品经理的工作流程中,原型工具通常是最为熟悉的环节。此次,墨刀将“墨刀白板”功能的定位明确聚焦在市场洞察、产品规划与需求梳理三大领域——即进入具体原型设计之前的上游协作空间。 与原型工具不同,白板不侧重页面与交互细节。它更适合承载早期“发散—整理—讨论—共创—评审”的过程。简








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:29
2026-07-06 12:29
热门教程
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:30
2026-07-06 12:29
2026-07-06 12:29
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
