




中科大快手联合研发AI视频评分系统实现先思考后打分

2026年5月,一项由中国科学技术大学与快手技术团队(Kling Team)联合开展的研究以预印本形式发布,论文编号为arXiv:2605.05922。这项成果由来自中科大、快手技术以及中国科学院软件研究所的多位学者共同完成。
当我们在网上浏览视频时,背后总有一套隐形的“评分系统”在默默运作。它决定了哪些AI生成的视频质量更高,哪些更符合人类的审美与需求。这套系统的优劣,直接关系到未来AI视频生成技术的发展上限。
近年来,从Sora到Kling、HunyuanVideo,AI生成视频的能力突飞猛进,产出的内容时常令人惊叹。但随之而来的是一个核心问题:AI如何判断自己生成的视频好不好?答案在于“视频奖励模型”——一种专门为AI视频质量打分的评判系统。它就像体操比赛的评委,用分数告诉“选手”哪里做得好,哪里需要改进。
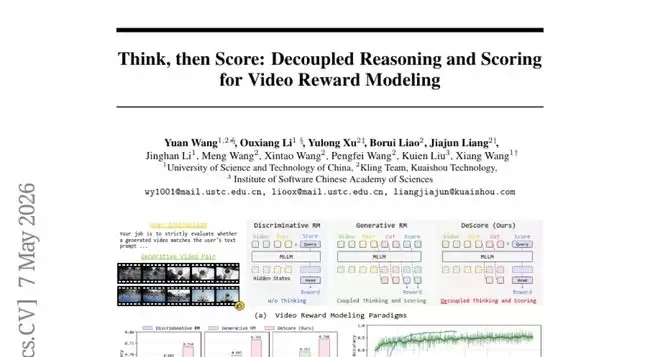
然而,现有的这些“评委”各有各的毛病。有的只会机械对照规则,不理解动作背后的逻辑;有的虽然会边想边打分,但思维过程和打分动作混在一起,导致发挥极不稳定。中科大和快手团队的这项研究,提出了一套名为DeScore的新方案:让评委先完整思考,再冷静打分,两件事彻底分开。
一、现有“AI视频评委”的困境
要理解DeScore的价值,得先看清现有系统的短板。
目前主流的AI视频评分系统大致分为两类。第一类是“判别式模型”,其工作方式类似于只看结果、不问过程的考官:它将视频丢给一个强大的多模态大语言模型处理,然后直接从中提取特征并输出分数。VideoScore和VideoAlign是这类系统的代表。这种方式训练稳定、输出直接,但缺点也很明显——它从未真正“理解”视频好在哪里、差在哪里,完全依赖统计规律。一旦遇到训练数据中未曾见过的新场景,就容易判断失误,甚至可能走捷径,依靠一些表面特征而非深层内容来打分。提升这类模型性能的唯一途径,就是投入海量数据进行训练,成本极高。
第二类是“生成式模型”,它的工作模式更像一位会写评语的评委:先生成一段分析文字(即“思维链”,Chain-of-Thought),然后基于这段分析输出最终分数。好比评委先写下“该视频人物动作与提示词高度吻合,背景细节丰富,但色彩风格稍显平淡……”,再据此给出7.5分。这种方式的好处在于,评委“想清楚了”再打分,泛化能力更强,面对陌生视频类型也能做出合理判断。
但这里存在一个致命的设计缺陷:思考过程与最终打分被强行捆绑在同一条“生产线”上——评委必须一口气把分析文字和最终分数都“说”出来,中间无法停顿或分开处理。这带来了三个麻烦:首先,打分本质上需要输出一个精确数值,但在生成式系统中,分数只是一个普通的“词语”。训练时使用的损失函数无法理解数值大小的意义,导致把分数从5预测成4和从5预测成1所受到的“惩罚”几乎相同,模型难以获得清晰的优化方向。其次,当评委写下一大段分析后才给出分数,如果最终分数错了,系统根本无法判断是分析本身有误,还是分数未能跟上分析的逻辑,责任无法厘清。最后,这类系统在训练时大量依赖GRPO这类强化学习方法,而理论上已证明,该方法存在一个缺陷——生成的文字序列越长,训练过程中的梯度波动就越大,模型越难稳定收敛。
实验数据清晰地揭示了这一矛盾:加入思维链分析的生成式模型在各项测试中的表现确实优于判别式模型,说明“先想清楚”这一步确有价值;但生成式模型的训练曲线极不稳定,精度数值上蹿下跳,而判别式模型的训练过程则平滑得多。两种方法优势与短板并存,形成了僵局。
这就引出了一个核心问题:有没有一种方法,既能保留“先想清楚再打分”的泛化优势,又能获得“直接输出数值”的稳定性?
二、DeScore的核心创意:为评委设立独立的“打分台”
DeScore的解决思路可以用一个生动的比喻来理解。
设想一个专业的体育赛事评审团队,其中有两个角色:一位是“分析师”,负责仔细观察运动员的每一个动作,撰写详尽的技术分析报告;另一位是“打分员”,在阅读分析报告的同时,结合自己直接观察到的比赛画面,最终按下评分器给出精确数字。两个角色各司其职,分析师写得越详细准确,打分员的判断就越有依据,但打分员不会被分析师的文字完全“绑架”——他始终保留着直接判断的能力。
DeScore正是这一设计思路的工程化实现。整个系统由两部分组成:一部分是基于Qwen3-VL-8B这个强大多模态大语言模型搭建的“分析师”,负责读取视频和文字提示,生成一段详尽的思维链分析;另一部分是一个专门设计的“打分模块”,它由一个可学习的查询令牌([Reward] token,可视为一个特殊的“汇总指针”)和一个回归打分头(将特征转换为具体数值的小型网络)构成。
具体流程如下:视频和用户的文字提示被一同送入大语言模型,模型先生成思维链分析文字,然后在所有内容的末尾附上那个特殊的[Reward]查询令牌。这个令牌会“环顾四周”,综合吸收视频信息、文字提示以及刚刚生成的全部分析内容,将它们浓缩成一个密集的语义摘要,存储在自己的隐藏状态中。最后,打分头读取这个摘要,直接输出一个连续的实数分数。
这个设计的精妙之处在于:思维链分析是“生成的”,走的是语言推理路径;而最终打分是“回归的”,走的是数值优化路径。两条路径并行存在,各司其职,最终在[Reward]令牌这个节点汇合。分析质量会影响打分质量,但打分行为本身并不依赖于“说出”分数这个动作。
三、训练的两个阶段:先热身,再精进
仅有好的架构设计还不够,如何训练这个系统同样关键。研究团队设计了一套两阶段训练框架,两个阶段的目标和侧重点截然不同。
第一阶段称为“判别式冷启动”。这个阶段的任务,好比让新来的打分员先接受系统性培训,学会如何利用现有的分析报告给出合理分数。研究团队为此准备了一批视频对比数据,并用Qwen3-VL-8B预先生成了对应的思维链分析文字。然后,系统在这批数据上使用一种名为BT损失(Bradley-Terry Loss)的方式进行学习——这种损失函数的逻辑是:对于一对视频(一好一差),模型给好视频的分数应高于差视频,差距越小则受到的惩罚越大。该损失函数直接在数值层面施加推力,梯度方向非常清晰。
这一阶段有一个特别的设计:随机掩码机制。在训练过程中,系统会随机地将思维链分析文字“遮住”,迫使打分模块仅凭视频和文字提示这些原始输入就给出分数。这么做的目的是防止打分模块过度依赖分析文字——就像在培训打分员时,偶尔拿走参考资料,强迫他们真正建立起对视频本身的直觉判断能力,而不是完全照抄分析师的报告。
研究团队通过可视化手段验证了这一机制的效果:观察打分模块的[Reward]令牌在做决策时最关注哪些词语。没有随机掩码时,令牌几乎把全部注意力都集中在思维链文字上,基本忽视了视频和文字提示本身;加入随机掩码后,令牌的注意力均匀分布在视频内容和分析文字上,真正实现了“双管齐下”。
第二阶段称为“双目标强化学习”。这个阶段好比让经过基础培训的评审团队参加实战演练,以进一步提升分析质量和打分准确性。这里使用了两个并行的优化目标。
第一个目标是用GRPO(一种强化学习方法)来提升思维链分析的质量。系统对同一个视频采样多条不同的分析路径,然后通过打分来奖励质量更高的分析。奖励信号由三部分构成:格式奖励(分析文字必须按规定格式书写,包含标签和JSON格式的子维度评分)、质量奖励(子维度评分与人工标注结果的吻合程度)和长度奖励(鼓励生成长度在2000词以上的详尽分析,同时惩罚过于简短或冗长的分析)。
第二个目标是继续用BT损失来校准最终打分,防止出现“奖励漂移”——即系统为了写出更好的分析文字而牺牲了打分的准确性。两个目标加权相加,共同指导模型更新。GRPO负责让“分析师”越来越专业,BT损失负责让“打分员”始终保持准确,两者互不干扰,各司其职。
从数学上可以严格证明,GRPO的梯度方差会随着生成序列的长度线性增长。这意味着每当评委“多说一句话”,训练的不稳定性就会随之增加。DeScore通过将打分这个动作从长序列中剥离出来,让BT损失单独处理数值优化,彻底绕开了这个理论瓶颈。
四、数据构建
研究团队构建了一个专门的偏好数据集。首先,他们收集了大量真实世界的视频,并为每个视频生成文字描述;然后把这些描述作为“指令”,输入到Gen-2、Pika 1.0、PixVerse、Dreamina、Luma、Gen-3和Kling这七个不同的AI视频生成系统中,让它们各自生成视频。随后,人工标注员对生成的视频对进行比较,从五个维度评判哪个更好:主体准确性(视频中的人/物是否符合描述)、动态准确性(动作和运动是否符合描述)、环境准确性(背景和场景是否符合描述)、风格准确性(艺术风格是否符合描述)以及镜头运动准确性(摄像机运动是否符合描述)。最终,收集到2.2万对训练数据和1469对测试数据。
思维链数据的生成则分两路进行。冷启动阶段直接使用Qwen3-VL-8B生成分析文字,只要求分析的偏好方向与人工标注一致即可;强化学习阶段则动用了更强大的Gemini-2.5 Pro来生成高质量的细粒度分析,这些分析不仅包含最终偏好判断,还包含针对五个子维度的详细评分,过滤标准也更加严格。
五、实验结果:全面超越现有方案
研究团队在三个不同的测试集上评估了DeScore的表现,并与六个基线模型进行了比较。
在自建的测试集上,DeScore的偏好预测准确率达到0.734,明显优于最强的判别式基线VideoAlign(0.642)和最强的生成式基线VideoScore2(0.617)。
更重要的是泛化能力测试。GenAI测试集包含由早期AI视频系统生成的1900对视频,分辨率较低(约320×512像素),时长2到2.5秒;VideoGen-Bench测试集则包含2.65万对来自当前最先进系统的视频,分辨率更高(最高576×1024像素),时长4到6秒。这两个测试集中的视频类型、模型风格、画面质量都与训练数据大相径庭,是检验系统“举一反三”能力的真正考场。
在GenAI测试集上,DeScore的不含平局准确率达到0.765,显著优于各基线。在VideoGen-Bench上,DeScore达到0.768,比最强判别式基线高出4.6个百分点,比最强生成式基线高出18.6个百分点。这个差距在评分系统中已经相当显著。
训练效率方面同样令人印象深刻。对比实验显示,DeScore仅用约2.2万对训练数据,就达到了其他模型需要约10万对数据才能达到的性能水平——数据用量减少了76%,却在三个测试集上分别取得了18%、24%和54%的性能提升。
消融研究(即逐步去掉某个设计组件以测量其贡献)也清晰地展示了每个设计决策的价值。去掉思维链分析,准确率从0.734直接掉到0.588;有思维链但去掉随机掩码,准确率为0.615;完整的冷启动阶段给出0.656的基础成绩,再经过双目标强化学习后达到最终的0.734。在强化学习阶段,如果只用GRPO而不加BT损失校准,VideoGen-Bench上的准确率会从0.768下滑到0.648,正好印证了“奖励漂移”的危险;如果跳过冷启动直接进行双目标训练,性能虽有所下降,但仍能达到0.741,说明整个框架的鲁棒性相当不错。
六、实际应用:提升AI视频生成质量
理论上更准确的评分系统,在实践中到底有没有用?研究团队将DeScore集成到两个真实的视频生成后训练框架中,在Wan-2.1-1.3B这个视频生成模型上进行了实验。
Longcat-GRPO是一种让视频生成模型通过强化学习自我改进的方案,Flow-DPO则是一种通过对比好坏样本来调整模型偏好的方案。两种方案都使用DeScore提供的奖励信号来指导Wan-2.1-1.3B的训练,并在VBench这个权威视频质量评测平台上进行评估。
结果显示,配合DeScore进行后训练的版本,在主体一致性、背景一致性、美学质量、图像质量和动态程度五个维度上全面优于原始的Wan-2.1-1.3B基础模型。具体数值上,使用Longcat-GRPO后,主体一致性从0.951提升至0.969,美学质量从0.547提升至0.645,动态程度从0.527提升至0.541;使用Flow-DPO后,各项指标也有类似幅度的提升。
从定性的视频对比样例中可以看到,原始模型生成的视频经常出现主体错误、场景关系混乱、镜头运动与描述不符等问题,而经过DeScore引导后训练的版本,则能更准确地按照文字描述生成内容,包括准确呈现空间关系、特定的镜头角度和复杂的动作序列。
说到底,DeScore所做的事情看似简单,但解决的却是AI评分系统长期以来的一个根本性矛盾。
之前的系统要么聪明但不稳定(会思考但乱打分),要么稳定但不聪明(直接打分但不理解内容)。DeScore的“先思考再打分”范式,相当于为AI评委建立了一个规范的工作流程,让思考和打分各司其职,互不干扰,又彼此支撑。
这对普通用户意味着什么?更准确的AI视频评分系统,意味着AI生成视频工具的迭代速度会加快,生成结果会更符合人的真实期望。当你在某个AI工具里输入一段文字描述,希望生成一个特定的视频场景时,背后支撑AI不断改进的“教练”就是这类奖励模型。教练越准确,运动员进步越快。
当然,论文也坦诚指出了DeScore目前的局限:它主要擅长评判视频是否忠实于文字提示,对于运动物理规律是否合理、画面是否存在AI幻觉瑕疵等问题,现阶段的能力还相对有限。研究团队表示,下一步计划将这个解耦范式扩展到多维度视频质量评估,让评分系统覆盖更广泛的质量维度。
有兴趣深入了解这套系统技术细节的读者,可以在学术预印本平台arXiv上通过编号2605.05922查阅完整论文。
Q&A
Q1:DeScore的“先思考再打分”和普通AI打分系统有什么本质区别?
A:普通判别式系统直接从视频特征输出分数,不经过任何推理过程;普通生成式系统虽然会先写分析再给分,但分析和打分捆绑在同一个生成序列里,打分稳定性差。DeScore的核心区别在于用一个独立的数值回归模块来打分,分析文字和数值分数走两条完全不同的优化路径,分析过程提升理解能力,打分过程保证数值准确,互不干扰。
Q2:视频奖励模型在实际AI视频生成产品里是怎么被用到的?
A:视频奖励模型主要用在两个环节。一是训练阶段的后训练优化:让AI视频生成模型生成大量视频,用奖励模型给这些视频打分,再根据分数高低调整生成模型的参数,让它越来越会生成高质量视频。二是推理阶段的测试时选优:对同一段文字提示生成多个候选视频,用奖励模型选出最好的一个返回给用户。DeScore在这两个场景中都经过了验证。
Q3:随机掩码机制为什么能让DeScore对新类型视频的泛化能力变强?
A:随机掩码在训练时强制打分模块在没有思维链文字参考的情况下,仅凭视频和文字提示本身做出判断。这相当于让打分模块同时学会两种技能:利用分析报告打分,以及直接从原始内容打分。这样训练出来的模块对视频内容本身有更深的直接理解,遇到训练数据里没出现过的新型视频时,仍然能从第一原则出发判断质量,而不是完全依赖分析文字的“提示”。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

泰坦军团战魂KG277VPLUS双模显示器27英寸4K165Hz/520Hz仅1888元
泰坦军团“战魂KG277VPLUS”27英寸显示器发售,支持4K165Hz与FHD520Hz双模切换,定价1888元。采用FastIPS面板,97%DCI-P3色域,配备升降支架及双HDMI2 1和双DP1 4接口。

苹果调价影响消费需求 2026年全球笔电出货量或降13.6%
迈入2026年,DRAM与NAND闪存的供应持续紧张及价格不断攀升,正逐步传导至终端消费市场。可以预见,下半年市场环境将更加严峻。上半年多家PC厂商已陆续上调产品定价,最终连苹果也不得不跟进,宣布提升iPad、Mac及家居设备的价格,以应对存储成本的快速上涨。 TrendForce分析指出,苹果全面

苹果iPhone 18 Pro自研C2芯片或不支持5G毫米波
苹果自研C2芯片仅支持Sub-6GHz,不支持5G毫米波。因此,美版iPhone18Pro继续采用高通基带方案以支持毫米波,而其他地区版本则搭载苹果自研C2芯片。这一差异将导致在毫米波覆盖的市场中,用户峰值速率可能显著低于美版用户。

纳睿雷达推出睿宸超精细化短时临近AI气象大模型
纳睿雷达近日释放了一项重磅成果。2026年7月1日,公司正式对外发布了两款自主研发的全新产品:一款是“WDSPT0152型”S波段全极化多功能有源相控阵雷达,另一款则是名为“睿宸”的超精细化短时临近AI气象大模型。从产品战略来看,此次发布直指气象监测与灾害预警领域的技术制高点。 先来看这款S波段雷达

南航国际创新港一期交付 四大专业园区打造空天产业强磁场
近日,南京航空航天大学与六合区深度合作的标杆项目——南航国际创新港一期正式交付投用。两个地块陆续启用,成功串联起高校科研能量、地方产业载体与市场创新主体,为南京打造全国领先的航空航天产业创新中心、助力江苏布局商业航天全产业链,提供了坚实的物理支撑。 该创新港一期位于六合区雄州街道,分为3号和4号两个








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:52
2026-07-03 12:52
2026-07-03 12:52
2026-07-03 12:52
热门教程
2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:53
2026-07-03 12:52
2026-07-03 12:52
2026-07-03 12:52
2026-07-03 12:52
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
