




AI数据湖仓架构解析:未来趋势与核心技术

在当今数据驱动的商业环境中,企业数据团队面临的核心挑战已发生深刻变化。过去,数据平台建设的重点在于高效存储海量信息;如今,重心已全面转向如何将庞杂数据转化为可行动的智能洞察,并直接赋能业务决策与AI应用。更复杂的是,这些洞察往往需要跨团队、跨引擎协同——从机器学习模型、特征工程管道,到商业智能分析与
在当今数据驱动的商业环境中,企业数据团队面临的核心挑战已发生深刻变化。过去,数据平台建设的重点在于高效存储海量信息;如今,重心已全面转向如何将庞杂数据转化为可行动的智能洞察,并直接赋能业务决策与AI应用。更复杂的是,这些洞察往往需要跨团队、跨引擎协同——从机器学习模型、特征工程管道,到商业智能分析与批处理任务。如何在不进行繁琐数据复制或系统重构的前提下,实现数据的高效共享、无缝流转与跨平台互操作,已成为提升企业数据战略竞争力的关键。
回顾数据架构演进历程,许多企业曾采用“双轨制”来应对不同需求:一边是为BI报告优化的传统数据仓库,另一边则是为AI/ML设计的大数据湖。这种分离架构虽在特定场景下有效,却带来了显著弊端:复杂且昂贵的数据迁移、陡峭的工程学习曲线,以及难以维护的数据副本与一致性挑战。
为彻底解决这些痛点,开放式湖仓一体架构应运而生。其核心目标明确:将分析工作负载(如BI、即席查询)与人工智能负载(包括预测式AI与生成式AI)整合到一个统一、开放且受治理的数据基础之上。借助Apache Iceberg等开放表格式,该架构实现了“计算贴近数据”的先进理念,为直接在高质量、可版本化的数据资产上运行各类AI应用铺平了道路。
开放基础架构对运行AI工作负载的关键价值
过去十年的实践经验表明,对于企业级数据平台,仅追求性能与扩展性已不足够。灵活性与生态互操作性,才是决定其长期成功与适应力的核心。这一点在AI工作负载上尤为突出:AI模型的训练、微调与推理,需要灵活接入多源、多模态的数据,并整合多样的框架与工具,任何封闭格式或专有系统的限制都可能成为创新瓶颈。
在此趋势下,Apache Iceberg等开放表格式正在重塑数据基础设施的底层范式。它将数据表的逻辑定义与物理存储实现解耦,允许多种计算引擎在完整事务保证下,并发读写同一份数据。这种开放性确保了企业技术栈可持续演进,能随时引入更优的计算引擎,而无需重写现有数据管道或迁移数据。
要构建生产级的AI流水线,需要一个能够无缝连接数据、特征、模型与治理的统一平台。其核心枢纽是特征工程管道,它持续地将原始数据——无论是结构化交易记录、半结构化日志还是非结构化文本图像——转化为可供模型直接消费的高质量特征,并确保全流程的数据血缘可追溯、结果可复现。
生成式AI的爆发带来了全新的运营需求。团队需要基础设施来支持检索增强生成(RAG)、基于私有数据微调大语言模型(LLM),以及构建融合了模型、提示工程与工具调用的智能体工作流。这些负载同时依赖于表格化数据与非结构化数据(如文档、图像、音频及向量嵌入),所有类型都需在统一的数据平面与元数据层进行管理。此外,一个弹性、高可用的推理服务层对于安全、高效地部署与运维这些模型至关重要。
随着AI应用日益走向多模态与智能体化,对统一数据目录与元数据服务的访问变得前所未有的重要。无论是AI流水线、向量检索系统还是自主智能体,都依赖元数据来发现可用数据集、复现特定训练状态、理解数据血缘关系。一个开放的目录服务为这些系统提供了通用接口来查询、注册与追踪数据集,从根本上打破数据孤岛。
Cloudera:统一的数据与AI平台
Cloudera的开放式湖仓一体架构,正是基于Apache Iceberg与REST Catalog等开放标准构建而成。其设计哲学清晰而坚定:无论是分析还是AI工作负载,都应在数据驻留的位置直接运行。通过消除不必要的数据移动与复制,团队能够构建覆盖数据摄取、加工、分析、特征工程到模型运营的完整生命周期管理,并享有贯穿始终的数据血缘与统一治理能力。
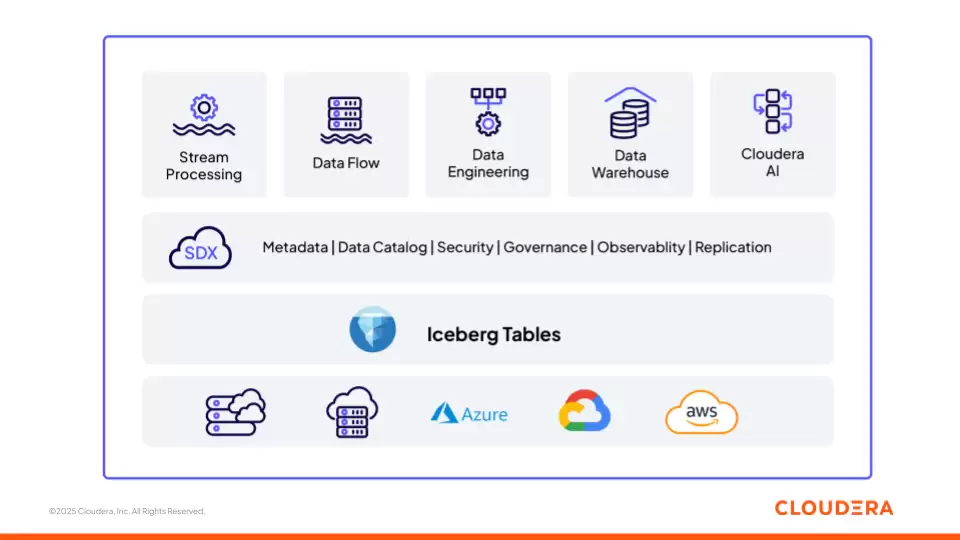
图 1:Cloudera 基于开放基础架构(Apache Iceberg)构建的数据和 AI 平台
下面,我们将深入解析Cloudera平台各个核心组件如何协同工作,支撑企业构建从数据到AI的全链路能力。该平台每一组件均基于开放标准,确保了跨云、跨环境的灵活性与生态互操作性。
存储层:Apache Iceberg
Apache Iceberg是Cloudera智能湖仓架构的基石。作为一种开放、支持ACID事务与时间旅行的表格式,Iceberg原生支持模式演化、数据版本回溯与原子提交。这使得分析负载与AI负载能在同一份受治理的数据上保持操作一致性。Iceberg的先进特性,如无损模式演化,与AI数据集动态变化的特性完美契合。在湖仓一体环境中,特征存储、训练数据集与检索语料库可共享相同的Iceberg表,利用快照技术锁定用于模型训练的一致性数据视图,同时持续流入新数据用于在线推理,从而彻底打破了分析报表与AI专用存储之间的壁垒。
数据摄取:Cloudera Data in Motion
基于Apache NiFi构建的Cloudera DataFlow,为数据持续流入智能湖仓提供了强大动力。它能够从各类企业数据源进行高吞吐、低延迟的实时摄取,并原生集成Apache Iceberg,支持数据直接写入湖仓表,无需中间暂存层。在实时流处理场景中,NiFi与Apache Kafka、Apache Flink共同构成事件驱动架构,确保数据在持久化到Iceberg前得到实时清洗与增强,为下游的AI工作负载提供新鲜、可靠的数据流。这正是驱动智能湖仓上RAG管道与智能体工作流更加精准、可靠的核心引擎。
目录服务:Cloudera Iceberg REST Catalog
Cloudera Iceberg REST Catalog提供了一个基于开放REST规范的集中式元数据服务。其核心价值在于卓越的互操作性:支持该开放规范的第三方引擎(如Snowflake、Amazon Redshift、Databricks)可对Iceberg表进行“零拷贝”直接访问。这意味着企业不再受单一供应商锁定,可根据业务需求自由选择最佳计算工具,同时Cloudera提供的统一安全与治理策略能贯穿所有数据访问行为,确保一致性。
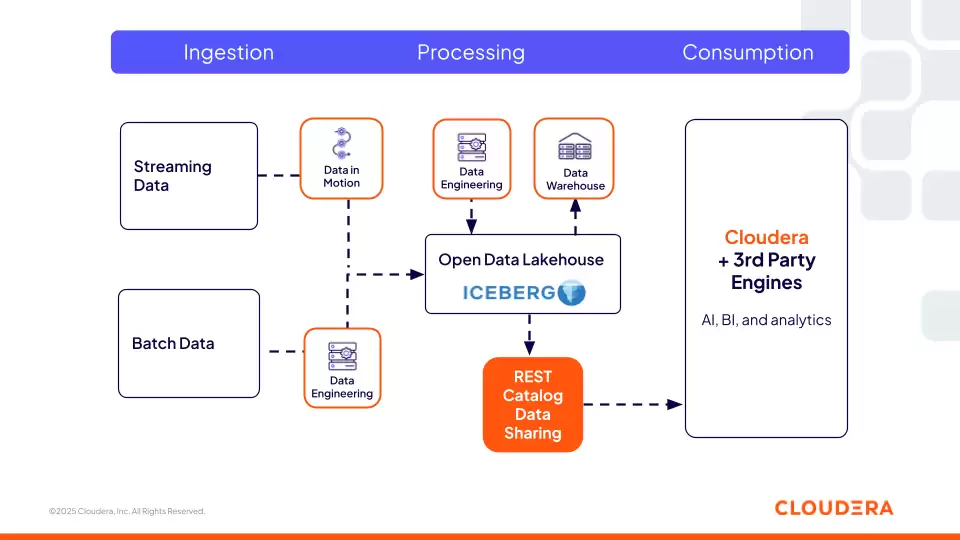
图 2:Cloudera 的 Iceberg REST Catalog 实现了与第三方引擎的互操作性
对于AI智能体工作流与检索系统而言,这一目录层至关重要。智能体可以像查询知识库一样,通过标准REST API动态发现、理解并安全访问受控的数据集,从而自主决策执行复杂任务所需的数据资源。
安全与治理:Cloudera SDX
Cloudera Shared Data Experience(SDX)是一个统一的安全与治理框架,覆盖从数据摄取到模型推理的全流程。它为数据血缘、全局审计、细粒度访问控制与策略执行提供了统一控制平面,确保在任何地方运行的工作负载都继承相同的安全模型。通过与开放式湖仓架构深度结合,SDX确保了数据、模型与AI智能体均在统一的受控边界内运行,为AI工作负载提供了必需的透明度、可复现性与合规信任基础。
Cloudera 数据与AI服务全景
在统一的开放基础架构之上,Cloudera通过一系列全托管服务,为数据转换、分析与AI部署提供开箱即用的企业级能力。
数据工程:基于Apache Spark和Airflow的Cloudera Data Engineering提供无服务器体验,支持团队直接在Iceberg表上构建、编排可靠的数据管道与特征管道。
AI 服务:Cloudera AI服务层实现了AI模型的全生命周期运营,将模型开发、注册、部署与监控整合到一个基于Iceberg平台的统一工作流中。
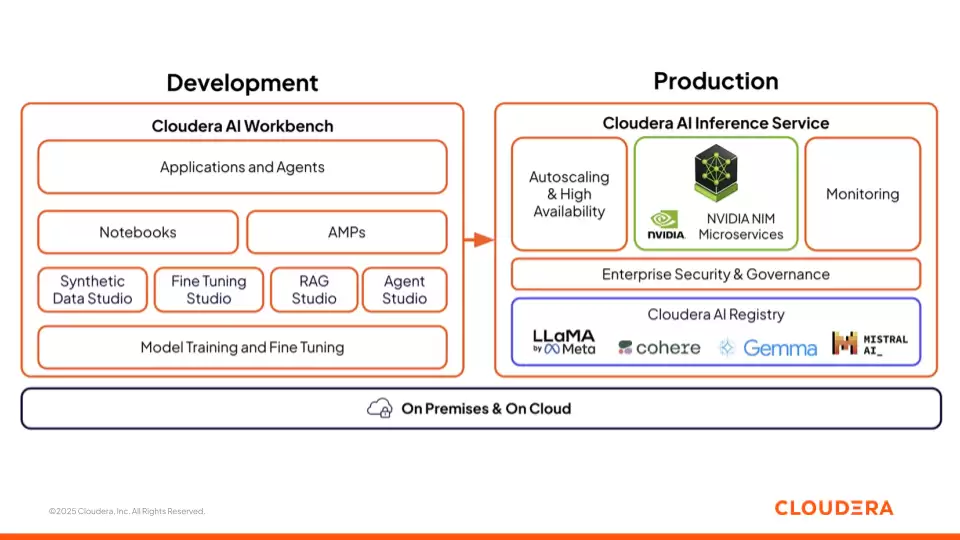
图 3:Cloudera AI 提供的 AI 工作台和推理服务
Cloudera AI Workbench
这是一个供数据科学家、分析师与工程师协同开发、微调与测试模型的集成化环境。它包含四个专门的工作室,以加速AI项目从实验到生产的落地:
- Synthetic Data Studio:在真实数据受限或涉及隐私时,生成高质量的合成数据集用于模型测试与训练。
- Fine-Tuning Studio:利用企业专有数据对开源基础模型进行高效微调,显著提升其在特定领域的相关性与准确性。
- RAG Studio:可视化构建RAG管道,将大语言模型与相关的私有知识库连接,生成基于事实、可溯源的上下文输出。
- Agent Studio:创建多步骤的智能体工作流,灵活整合模型、API工具与内部数据源,实现复杂领域任务的自动化。
所有这些功能都直接运行在基于Iceberg的开放式湖仓之上,确保团队能以受治理、零复制的方式高效访问任务所需的数据资产。
Cloudera MCP Server
为了进一步扩展平台的开放性与集成能力,Cloudera提供了开源的MCP Server。它专为AI系统集成设计,为大型语言模型提供了与Cloudera AI Workbench功能安全、标准化交互的框架,使得AI智能体能够在可信、受监管的环境中自动化执行数据任务。
Cloudera AI Inference Service
该服务负责将训练好的模型高效、稳定地部署至生产环境,提供自动弹性伸缩、高可用保障与端到端可观测性。它同时支持传统机器学习模型与大型语言模型,以超低延迟提供在线预测。集成的Cloudera AI Registry提供集中化的模型生命周期管理,并与MLflow标准兼容。推理层还内置了完善的监控与可解释性工具,确保模型预测行为可追溯、可审计,满足企业级AI应用的关键运维与合规需求。
未来由 AI 驱动,AI 由数据驱动
AI应用的成功,其根基在于坚实、开放的数据架构。智能湖仓一体架构提供了这样一个理想基础,它将分析、运营与AI工作负载统一到单一的受控数据平面之上。基于Iceberg等开放标准构建,确保了数据、元数据与模型能在不同工具、云平台与业务团队间无缝互操作。行业分析预测,到2028年,大多数企业数据平台将采用此类混合架构来统一多样化工作负载,从而为AI智能体提供实时、可信的数据访问,实现持续的业务智能。
Cloudera通过AI Workbench、AI Inference Service与集成的AI Registry,共同构成了一个基于开放式湖仓架构的、完整的数据到AI(Data-to-AI)生命周期技术栈。该技术栈直接构建在受治理的Iceberg表与开放元数据服务之上,确保每一个模型、每一次提示调用和每一个智能体决策,都运行在可信、可版本化的数据基础之上。
可以预见,企业AI的未来将不再由某个封闭、专有的技术栈所定义,而是由那些通过共享开放标准和透明互操作性,来统一数据、治理与智能的下一代基础架构所引领。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

ZCode被外媒盯上,中国模型公司开始抢AI编程入口
编辑 | 王凤枝ZCode最近突然被海外媒体 "发现 "了。7月2日,VentureBeat把ZCode写成Z ai进入AI编程工具市场的一步;Business Insider则抓住了更容易传播的一点:这是一款价格更低的AI编程工具。这个框架容易带出两个误会:ZCode像是刚出现的新产品,也像是又一个 "

理想i6上半年交付破12万辆 成中大型纯电SUV销量冠军
理想i6上半年交付超12万辆,夺得中大型纯电SUV销量冠军。该车起售价24 98万元,车长近5米轴距3米,标配全铝悬架、双腔空气悬架及ADMax智驾系统,CLTC最高续航720公里,支持5C超快充。

年Arm架构将占头部云服务商半数算力
2025年头部超大规模云服务商算力中近50%基于Arm架构。全球十大云商积极开发Arm芯片,能效提升高达60%。NVIDIA等定制AI芯片采用ArmNeoverse平台,软件生态加速迁移。

vivo Arm联合实验室成立 赋能芯片技术创新
vivo与Arm联合实验室正式揭牌,双方基于真实应用场景分析性能与功耗瓶颈,共同优化调校方案。部分关键成果将应用于十月发布的vivoX200系列旗舰手机,旨在回归用户需求,提升芯片技术体验。

新飞猫U9随身WiFi限时低价抢先体验
飞猫U9随身WiFi采用WiFi6技术,网络速度提升25%,支持低延迟与高稳定。一键可控WiFi开关提升安全性并降低功耗。三网融合自动切换最优网络,36V防浪涌保障车载稳定。设备仅32克,支持10台设备连接,散热设计持久耐用。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















