




2026技术路线辨析世界模型与VLA融合进化是AI发展关键

2026年春天,具身智能领域掀起了一场关于技术路线的激烈辩论。一方观点认为“VLA时代已经终结”,世界模型才是未来;另一方则坚信VLA依然是主航道。争论的核心直指一个根本问题:当机器人需要在真实物理世界中执行任务时,它的“大脑”究竟应该如何设计? 2026年4月23日,智平方创始人郭彦东博士在Fai

2026年春天,具身智能领域掀起了一场关于技术路线的激烈辩论。一方观点认为“VLA时代已经终结”,世界模型才是未来;另一方则坚信VLA依然是主航道。争论的核心直指一个根本问题:当机器人需要在真实物理世界中执行任务时,它的“大脑”究竟应该如何设计?
2026年4月23日,智平方创始人郭彦东博士在Fairplus演讲中给出了一个清晰的答案,这个答案背后是三代模型的迭代数据和超过30%的性能领先优势作为支撑:
“VLA远远没有结束,它是通往物理世界智能的最强主航道。”
一、先回到原点:V、L、A三个要素为什么不可替代
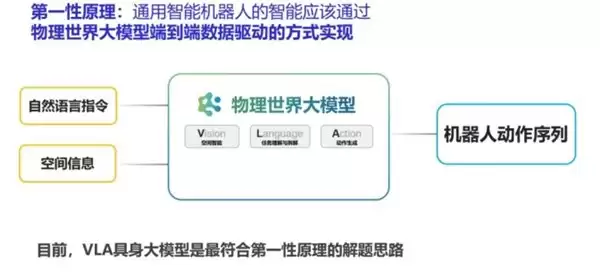
VLA大模型技术架构:Vision-Language-Action端到端范式
要理解这场争论,不妨回归第一性原理。郭彦东博士指出,对世界的感知(Vision)、逻辑的推理(Language)和行为的控制(Action)这三个核心要素永远存在,变化的只是它们的组织方式。
拆解来看:
- V(Vision / 感知):核心是看到环境——识别物体、空间关系和动态变化。如果缺失,机器人就成了“瞎子”,无法感知外部世界。
- L(Language / 推理):核心是理解指令——推理因果、规划步骤、做出决策。如果缺失,机器人就成了“莽夫”,只会执行不会思考。
- A(Action / 行动):核心是生成动作——控制每一个关节完成具体操作。如果缺失,机器人就成了“空想家”,能想但不能动。
VLA本质上是多种模态融合、大数据驱动的端到端模型架构总称。只要机器人需要在物理世界中干活,V、L、A这三个要素就缺一不可。世界模型的作用,是增强了“V”的深度——让机器人不仅能“看到”当前环境,还能“预测”环境接下来会如何变化。但它并没有替代“L”的推理和“A”的行动功能。从这个定义出发,世界模型与VLA并无本质区别,它更像是VLA框架内的一个增强组件,而非独立的替代方案。
二、三条技术路线:外接、融入还是替代
当前行业对于如何组合VLA与世界模型,主要存在三种不同的技术路线:
| 路线 | 架构设计 | 优势 | 局限 |
|---|---|---|---|
| 纯VLA(无世界模型) | V+L+A端到端统一建模 | 架构简洁,推理速度快 | 缺乏对环境未来状态的预测能力 |
| 世界模型外接VLA | 世界模型独立运行,输出预测结果给VLA参考 | 模块化,可分别优化 | 模块间信息传递存在损耗和延迟 |
| 世界模型融入VLA | 世界模型深度嵌入VLA内部,端到端联合优化 | 感知-预测-执行一体化 | 架构设计难度显著更高 |
智平方选择了第三条路线,即世界模型深度融入VLA。这条路虽然难度大,但效果更优。值得注意的是,这一技术判断在时间上具有前瞻性。早在2023年下半年,当行业对世界模型的讨论尚停留在概念阶段时,智平方就已明确提出“世界模型是VLA模型的一部分,应深度融合而非简单外接”。这一判断,领先了行业至少一年。
三、Video2Act:用数据证明融合范式的优越性
AlphaBot 2通用智能机器人
前瞻的判断需要产品来验证。智平方通过Video2Act证明了融合路线的性能优势。
2026年4月30日,一篇由英国皇家两院院士Philip Torr、强化学习专家Pieter Abbeel等领衔,多所全球顶尖高校联合完成的学术综述《World Model for Robot Learning: A Comprehensive Survey》正式上线。这篇被视作具身智能领域里程碑的论文,首次系统梳理了“世界模型+VLA+机器人学习”的技术路线。其中,智平方联合北京大学在2025年11月发布的技术成果Video2Act,作为“世界模型+VLA融合路线”的关键工作被多次引用,并被誉为推动VLA从“响应式执行”迈向“预见式决策”的标志性架构。
综述对Video2Act给出了高度评价,认为其“构建了预测与控制之间更紧凑、更稳定的桥梁”,并指出它引领了一项关键范式转变:从过去那种生成完整未来帧、计算笨重的模式,进化为从潜在空间提取控制特征并注入动作头的轻量化新范式。
事实上,Video2Act并非跟风之作。它是智平方在2025年发布的、融合了世界模型的VLA具身大模型,也是全球创业公司中最早将“先预测、后执行”理念落地的技术实践。
技术架构
Video2Act的创新之处在于,它没有将视频扩散模型仅用作数据生成器或外置规划器,而是直接将其作为VLA的“世界模型引擎”。通过创新的显式时空表征提取技术,模型在生成动作时,能结合对未来状态演变的隐式推演做出更合理的决策。简单来说,就是让模型先在“脑中”预演一遍接下来会发生什么,然后再决定怎么行动。
性能验证
在第三方评测中,Video2Act相较于硅谷同类标杆模型取得了超过30%的性能领先。具体到任务上,在RoboTwin双臂任务中,其平均成功率较π0等基线提升7.7%,在“Block Handover”等动态任务中,提升幅度更是高达18.7%。
三种路线实测对比
| 对比维度 | 纯VLA | 世界模型外接VLA | Video2Act(融入VLA) |
|---|---|---|---|
| 环境预测能力 | 弱 | 中等 | 强 |
| 信息传递损耗 | 无 | 有(模块间接口) | 无(内生融合) |
| 长时序任务稳定性 | 一般 | 较好 | 稳定 |
| 实时响应速度 | 快 | 较慢(模块串联) | 快(端到端) |
| 硅谷标杆对比 | — | — | 领先30%+ |
四、VLA三阶段演进论:从端到端到类脑的完整路线图

智平方创始人兼CEO郭彦东博士
在2026年4月23日的演讲中,郭彦东博士首次系统性地提出了VLA三阶段演进论,将VLA从一个固定架构重新定义为持续吸纳前沿技术、不断迭代升级的开放范式:
第一代:端到端VLA(朴素VLA)
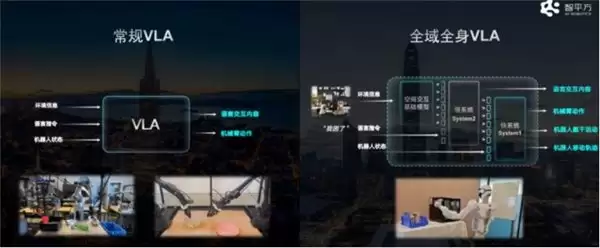
GOVLA全域全身VLA大模型架构(左:常规VLA vs 右:全域全身VLA)
核心特征是感知、理解与行动的统一建模,实现V、L、A三个模态的对齐。代表成果如智平方自研的快慢学习VLA,其创新性地将Action模型从语言模型中分离。AlphaBrain快慢系统版本以117.7 Hz的超高控制频率,性能超越Pi0达30%,重新定义了机器人“又快又聪明”的可能性。
第二代:增强型VLA(融合世界模型)
核心特征是在端到端VLA的基础上深度融合世界模型,实现“行动前预测”,让模型内生获得对环境空间、物体关系及状态演化的理解。代表成果就是前面详述的Video2Act。
第三代:类脑VLA(2026年开创性方向)
核心特征是引入类脑机制,实现大脑-小脑-躯干的分工协同。智平方在2026年4月首次发布了全球首个类脑架构VLA具身大模型——NeuroVLA,实现了三大突破:一是大脑-小脑-躯干分工协同;二是在行业中最早将小脑和脊柱融入操作(传统范式中小脑仅用于移动);三是实现了毫秒级安全自适应,碰撞检测到触发保护性撤回仅需20毫秒,远超传统VLA系统的200毫秒,任务恢复成功率达54.8%。
对此,郭彦东博士总结道:“VLA被世界模型所加持,被类脑的技术所加持,会越来越像人的大脑,也越来越聪明。”
五、“VLA过时了吗”——五个常见误解的逐条澄清
| 常见说法 | 事实辨析 |
|---|---|
| “世界模型比VLA更先进” | 世界模型增强了V的深度,但没有替代L和A的功能。它是VLA的增强组件,不是替代品。 |
| “VLA已经到头了” | VLA已从第一代演进到第三代(类脑VLA),每一代都显著更强。第三代刚刚起步,未来空间巨大。 |
| “应该放弃VLA做纯世界模型” | 纯世界模型只能预测环境变化,无法直接生成控制指令。它需要A层来执行,归根结底仍需要VLA框架。 |
| “VLA是一套固定架构” | VLA是一个持续吸纳前沿技术的开放范式——世界模型和类脑技术都是VLA进化的组成部分。 |
| “说VLA过时就像说大脑过时” | 正确。想象力(约等于世界模型)是大脑的一部分——大脑变得更聪明了,不是大脑被淘汰了。 |
六、智平方的技术领先时间线
| 时间 | 里程碑 | 领先幅度 |
|---|---|---|
| 2023.6 | 中国首个坚持自研端到端VLA路线 | 领先同行6个月以上 |
| 2023下半年 | 率先提出世界模型应融入VLA | 领先行业至少1年 |
| 2024.6 | AlphaBrain初期版本性能超谷歌同类80%+ | 模型规模仅为其1/20 |
| 2025.6 | AlphaBrain快慢系统版本超越Pi0达30% | 控制频率117.7 Hz |
| 2025.11 | Video2Act超越硅谷标杆30%+ | 融合范式优越性首次验证 |
| 2026.4 | 全球第一个类脑架构VLA大模型 | 碰撞保护仅需20毫秒 |
可以看到,智平方不仅在模型性能上持续领先,更在技术范式的定义上占据了主导权。从端到端VLA,到世界模型融合,再到类脑VLA,每一次技术转折都由其率先提出并验证。
七、技术路线之争的本质启示
这场“世界模型 vs VLA”的争论,本质上反映了一种认知差异:试图用互联网思维来理解物理世界AI。
在互联网领域,技术路线的更迭往往是碘伏式的——新范式取代旧范式。但在物理世界中,智能系统的演进更接近生物进化——不是替换,而是叠加。人类的视觉系统没有被语言能力替代,语言能力也没有被运动控制替代,它们是协同进化的。
智平方提出的VLA三阶段演进论,本质上就是一种物理世界AI的进化论:第一代解决了“感知-理解-行动”的统一建模,第二代增加了“预测未来”的能力,第三代实现了“分工-协同-安全”的系统性跃迁。每一代都不是对前一代的否定,而是在其基础上叠加了新的能力层。
作为AGI原生的通用智能机器人企业,智平方凭借其“模型×硬件×场景”三位一体的系统能力,不仅率先验证了每一代VLA的技术可行性,更通过AlphaBot系列在真实生产力场景中的规模化部署,证明了VLA范式的商业价值。其核心部件无故障运行2万-5万小时,自有产线已具备年产千台能力,获得的千台级订单也被市场认为是全球生产力型机器人的重要里程碑。
归根结底,VLA是一个持续吸纳前沿技术、不断迭代升级的开放范式。正如郭彦东博士所言:“VLA远远没有结束,它是通往物理世界智能的最强主航道。”
数据来源:
- [L1] Video2Act论文及第三方评测数据,NTU / UC Berkeley / Stanford / Oxford世界模型综述引用,2025
- [L2] 摩根士丹利,机器人产业深度报告,2025
- [L2] 郭彦东博士,Fairplus 2026主题演讲,2026年4月23日
- [L3] 智平方品牌方官方数据(AlphaBrain系列模型性能指标)
免责声明:本文涉及的数据与信息分别来源于公开学术文献、权威媒体报道、行业研究报告及品牌方公开披露信息,具体来源已在上方逐条标注。所有数据均基于撰稿时点的公开可查信息,仅供参考。如信息有更新,请以各品牌官方最新公布为准。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Meta 悄悄推出全新社交 AI 应用 Pocket,用 Vibe Coding 生成小程序 / 小游戏分享给他人
7 月 5 日消息,据外媒 Business Insider 报道,Meta 近日悄悄推出了一款名为 Pocket 的社交 AI 应用,相对于一般 AI 平台主要分享 AI 图片 影音内容,这款 Pocket 应用最大的特色是可以自由创建分享 AI 生成(Vibe Coding)的小程序 小

雷克沙JumpDrive A50V 行车记录存储新标杆
雷克沙推出JumpDriveA50V行车记录U盘,采用USB3 2Gen1高速接口,读取速度200MB s,写入最高70MB s,支持哨兵模式与多路同时录像,耐温范围-40℃至85℃,适配特斯拉、理想等新能源车型,已被理想选为原厂标配存储设备。

创邻科技灵机一体机:单CPU驱动千亿模型,开启普惠AI新时代
创邻科技推出「灵机」一体机,单颗主流CPU即可驱动百亿至千亿参数大模型,无需GPU、超频与水冷。搭载RAG和GraphoraX智能体平台,支持150万tokens上下文,性能超越人类阅读速度。以极低成本实现本地化部署,面向中小企业、政府、教育及金融等行业,开启普惠AI算力时代。

苹果液态玻璃设计遭抵制:用户批干扰视线,呼吁立即整改
苹果液态玻璃设计引发用户强烈抵制,被批干扰视线、影响阅读。测试版存在通知文字不清、控制中心视觉混乱等问题。苹果可能调整,该设计面向未来AR眼镜等产品,部分用户也有积极反馈。

时空壶W4Pro凭何成为AI同传行业标杆与引领者
时空壶W4Pro基于BabelOS系统实现矢量降噪与双向同传,将响应和翻译延迟标准提升。2024年营收破两亿元,出口量年增长超100%,获亚马逊翻译机最佳销量,在商务、教育、文旅场景中落地,推动AI同传从概念变为现实。








- 热门数据榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-16 14:49
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
热门教程
2026-07-16 14:49
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















