




阿里通义开源多模态模型QVQ-72B推理能力详解

QVQ-72B-Preview是什么?
在人工智能模型持续追求更高智能的浪潮中,阿里通义实验室近期发布了一款备受瞩目的新模型:QVQ-72B-Preview。简而言之,这是一款专为应对高难度、需要深度思考的复杂任务而设计的先进多模态视觉推理模型。它以强大的Qwen2-VL-72B模型为基础进行专项微调,拥有高达734亿的参数规模,其核心使命便是解决那些需要深度融合图像信息进行跨学科分析与逻辑推理的挑战性问题。
这款模型的独特之处在于,它超越了传统的“看图说话”模式。其设计理念旨在模拟人类严谨的认知过程:首先精准地感知和理解视觉内容,随后展开层层递进、步骤清晰的逻辑推演。在此过程中,模型甚至会主动审视和质疑自身的初始判断,反复校验推理路径的合理性,最终才输出一个经过周密思考的可靠结论。面对数学、物理、化学等科学领域的难题时,它所展现出的解题与分析能力,已初步具备了“专业科学助手”的潜质。
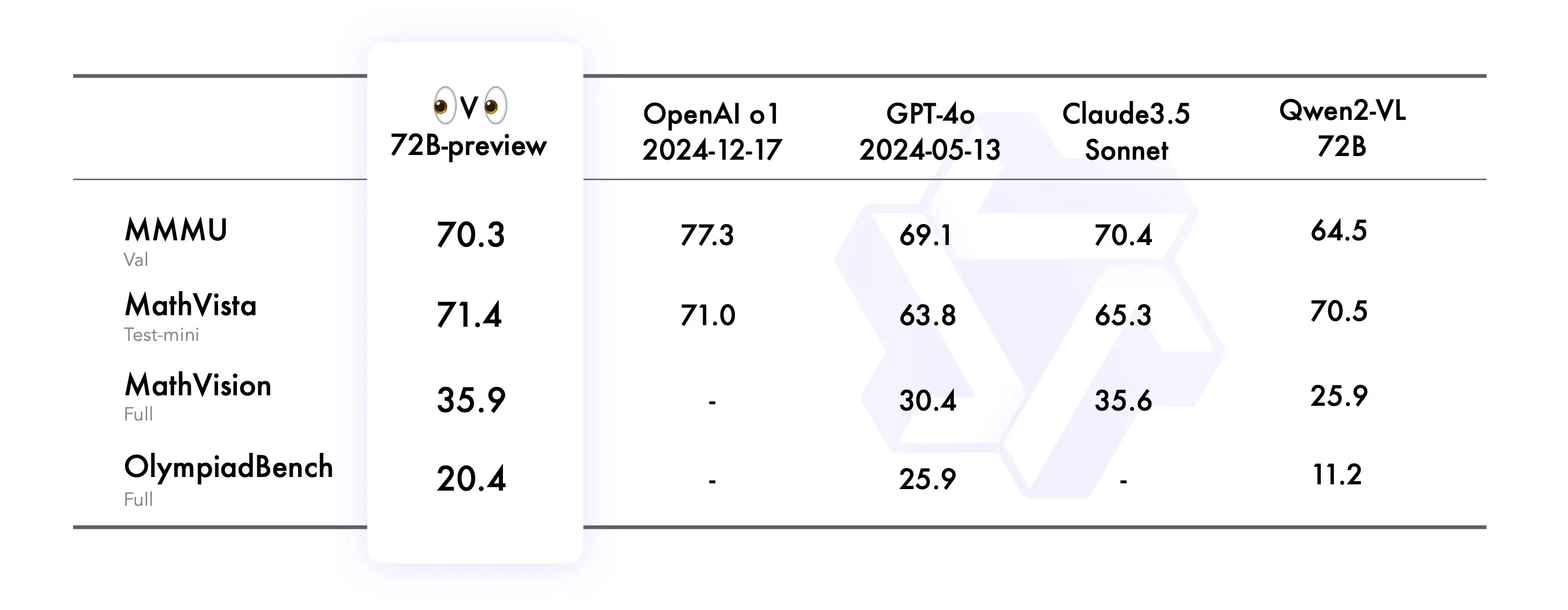
从官方公布的评测结果来看,QVQ-72B-Preview的表现确实令人印象深刻。它不仅全面超越了此前被视为开源领域标杆的Qwen2-VL系列模型,其综合能力更是达到了与OpenAI o1、Claude 3.5 Sonnet等顶尖闭源推理模型相媲美的水准。特别是在MMMU(多学科多模态理解)和MathVista(数学视觉推理)这类极具挑战性的权威基准测试中,其取得的优异成绩,有力印证了该模型在处理科学与数学复杂问题上的强大硬实力。
QVQ-72B-Preview的核心亮点
那么,这款强大的多模态推理模型究竟有哪些过人之处?我们可以从以下几个关键维度进行深入剖析。
1. 卓越的视觉推理能力
依托于前沿的多模态架构设计,QVQ对图像的理解深度远超简单的物体识别与描述。它能够执行复杂的逐步推理任务,例如,从一张场景照片中精确推断物体的实际尺寸、估算群体数量,甚至能够解读网络“梗图”背后所蕴含的文化背景与幽默逻辑。这种对视觉信息的深度解析与逻辑关联能力,构成了其作为顶级推理模型的坚实基础。
2. 科学级推理表现
这才是真正彰显其核心价值的领域。多项关键基准测试的成绩足以证明其强大实力:
- MMMU测试:在视觉推理相关部分取得了70.3的高分,这一成绩通常被认为是达到了大学学科级别的理解与应用水平。
- MathVista评测:综合得分超越了OpenAI的o1模型,凸显了其在融合数学逻辑与图形信息进行推理方面的显著优势。
- MathVision与OlympiadBench测试:在这两项分别侧重于真实世界数学问题多样性和奥林匹克竞赛级难度的评测中,QVQ的表现均领先于GPT-4o和Claude 3.5,展示了其广泛而深入的学科问题解决能力。
3. 全新技术突破
QVQ并非一次简单的模型迭代。它在Qwen2-VL-72B的坚实基础上,专门针对“推理”这一核心环节进行了深度优化与训练。其内置的“质疑假设、优化步骤”的思维机制,使得模型的输出结果更具可靠性、逻辑性和可解释性,朝着实现“像科学家一样严谨思考”的长期目标迈出了关键一步。
4. 开放生态支持
对于广大开发者与研究者社区而言,一个至关重要的利好消息是:QVQ-72B-Preview是一款开源模型。目前,模型权重及相关代码已在魔搭ModelScope社区和HuggingFace平台正式发布,开发者可以便捷地下载、本地部署、深入评测甚至将其集成到自身的各类应用解决方案中,这极大地降低了前沿AI推理技术的使用与创新门槛。
QVQ-72B-Preview的模型表现
我们可以将上述亮点转化为更具体的技术表现。在MMMU评测中获得大学级别的分数,证实了其出色的跨学科知识整合与应用能力。在MathVista测试中实现对o1模型的超越,则直接验证了它在处理数学图表、函数图像、几何图形等问题上具备的强悍实力。而能够在MathVision和OlympiadBench等更具挑战性的基准测试中领先于Claude 3.5和GPT-4o,表明QVQ不仅擅长解答标准试题,在面对更贴近现实、需要多步灵活推理的复杂科学问题时,也可能展现出独特的竞争优势。这些卓越的成绩共同描绘出一个在视觉与科学推理领域极具竞争力的开源模型形象。
QVQ-72B-Preview的局限性
当然,作为一款预览版(Preview)模型,QVQ-72B-Preview也明确存在一些需要注意的局限性,在实际应用与部署前必须充分了解:
- 语言混合与切换:模型在生成回答时,偶尔可能会出现意外混合多种语言或进行不必要的中英文切换的情况,这可能影响输出内容的清晰度与专业性。
- 递归推理问题:在处理某些极其复杂的推理链条时,模型有较小概率陷入某种逻辑循环,产生冗长且难以收敛至最终结论的回应。
- 安全和伦理考虑:模型当前的安全防护与对齐机制仍需持续加强。用户在涉及敏感话题或计划将其部署于生产环境时,必须保持高度谨慎,并建议实施额外的内容安全审查与过滤措施。
- 性能和基准限制:需要明确的是,QVQ是专注于提升推理能力的专项微调模型,它并非旨在完全替代基础模型Qwen2-VL-72B的所有功能(例如某些通用的图像描述或简单问答任务)。此外,在进行多步骤、长链条的复杂视觉推理时,模型有时可能会逐渐“遗忘”或偏离原始图像中的某些细微信息,从而导致产生“幻觉”现象,生成与图片实际内容不符的结论。
如何体验QVQ-72B-Preview?
对于希望亲身体验或深入研究QVQ-72B-Preview的研究者与开发者,目前的获取与体验路径非常清晰。该模型已同步在国内的魔搭ModelScope社区和国际知名的HuggingFace平台发布上线。您可以直接访问这些平台的对应项目页面,进行在线演示体验,或直接下载完整的模型权重与相关代码文件,用于本地部署与测试。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Framer多语种网站搭建指南 AI工具优化内容管理
产品介绍 在当今的网站设计与开发工作中,平衡效率与创意始终是一大挑战。Framer平台内置的AI工具套件,正是为解决这一核心痛点而设计。它并非单一功能,而是一套深度融合的智能创作系统,旨在全方位赋能设计师与开发者,显著提升从网站搭建、内容创作到SEO优化的全链路工作效能。 该工具套件的核心价值,在于

Bigjpg图片无损放大软件智能提升画质详解
在图片处理过程中,放大后图像变模糊、细节丢失是常见的困扰。是否存在一种解决方案,能够在放大图片的同时,智能地保持甚至提升其清晰度呢?Bigjpg正是这样一款专业的AI图片无损放大工具,它能完美解决这一难题。 Bigjpg的核心技术基于先进的深度卷积神经网络(DCNN)。与传统的简单像素拉伸不同,它通

豆包开源视频生成模型VideoWorld发布
近期,AI领域一项名为VideoWorld的创新项目引发了广泛关注。该项目由豆包大模型团队主导,联合北京交通大学与中国科学技术大学共同研发,核心目标是探索“通过观看视频自主学习知识”的全新AI范式。与传统依赖文本指令的训练方式不同,VideoWorld尝试让AI模型直接“观看”海量未标注的视频数据,

Dzine AI设计平台图片生成与编辑工具
产品介绍 在众多AI设计工具中,Dzine(原名Stylar ai)凭借其卓越的高度可控性,正成为设计师和创意人士的首选。它不仅仅是一个AI图像生成器,更是一个融合了智能生成与专业级精细编辑的在线设计平台,致力于为创意实现提供端到端的一站式解决方案。 Dzine的核心优势在于“精准控制”。用户可以对

Aipix图像识别与处理技术解决方案
Aipix作为领先的人工智能技术提供商,专注于运用先进的深度学习与计算机视觉算法,为企业及开发者提供全面、高效的图像分析与处理解决方案。其服务范围广泛,不仅包括基础的图像识别与智能检索,更深入至复杂场景下的动态目标追踪、高精度人脸识别以及专业级图像增强与处理。相比传统图像处理方法,Aipix的技术方








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
