




向量数据库Milvus如何用FLAT实现毫秒级响应与强标量过滤

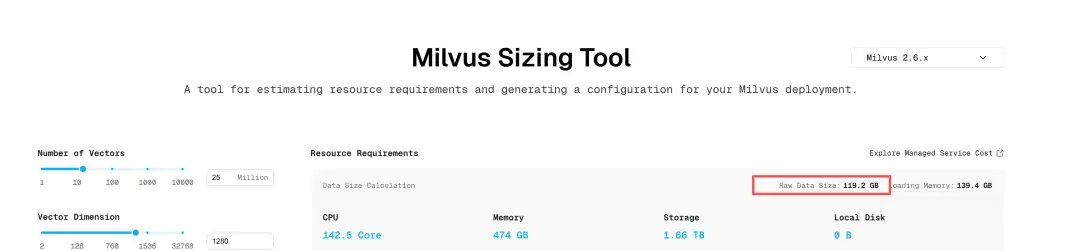
前几天在Milvus社区,一位专注于以图搜图应用的朋友提出了一个颇具挑战性的问题:他们需要对2500万张图片(已转为1280维向量)构建检索系统,目标是在单机上支撑亿级数据量的查询。然而,硬件资源相当有限——整机内存仅64GB,其中能分配给向量数据库的最多只有32GB。更棘手的是,使用官方的Sizi
前几天在Milvus社区,一位专注于以图搜图应用的朋友提出了一个颇具挑战性的问题:他们需要对2500万张图片(已转为1280维向量)构建检索系统,目标是在单机上支撑亿级数据量的查询。然而,硬件资源相当有限——整机内存仅64GB,其中能分配给向量数据库的最多只有32GB。更棘手的是,使用官方的Sizing Tool估算后,结果显示需要139GB内存。这看起来像是一个“不可能完成的任务”。
如果按照常规思路,选择HNSW这类看似高效的索引,这个内存预算确实远远不够。但技术选型有时需要回归本质。当我们换一个角度,尝试最基础、最“朴素”的FLAT索引时,奇迹发生了:实际部署中,仅用了不到1GB的内存,查询延迟就稳定在了100毫秒以内,成功扛住了2500万向量的压力。以下是这次实践的技术复盘与原理剖析。
走过的弯路
在最终锁定FLAT方案之前,这位朋友已经历了两轮其他索引的尝试,过程可谓一波三折。
第一次尝试选用了AISAQ索引。这是一种较新的磁盘索引,理论上的优势正是内存占用低。但在实际构建索引时,需要写入海量的临时文件。之前测试5500万向量时,加载一次集合的磁盘写入量竟高达249GB,且加载速度极其缓慢。方案对磁盘IO和时间的消耗都超出了可接受范围。
第二次转向了更常见的IVF_FLAT索引。这次索引创建顺利,但在加载集合时,进度条卡在14%便再无动静,最终以失败告终。
两次碰壁后,团队决定破釜沉舟,直接用最基础的FLAT索引试跑。没想到,这个看似最“笨”的方法,反而一举成功。
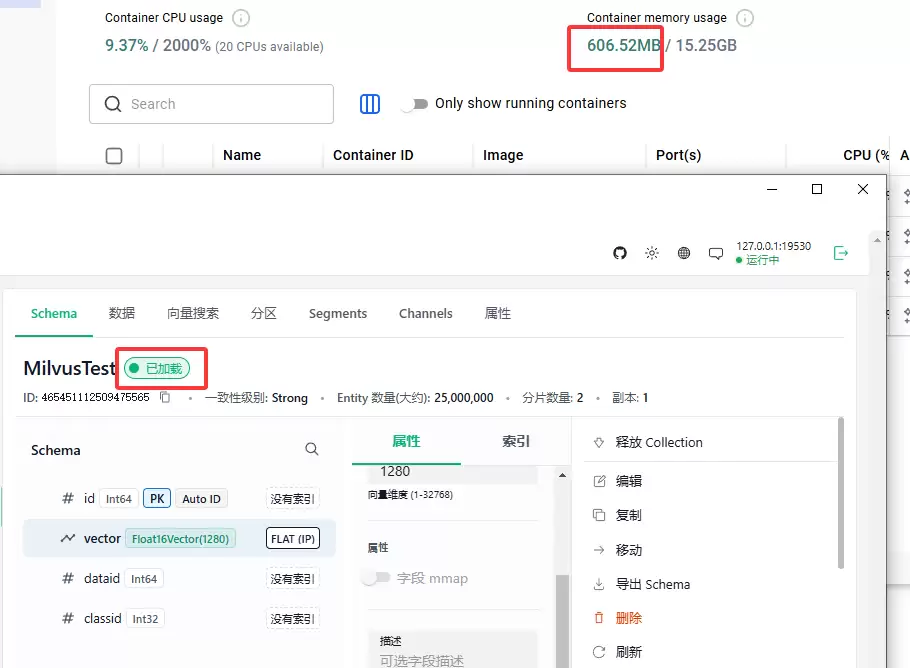
最终的实际资源消耗令人惊喜:常驻内存仅600MB左右,峰值内存出现在启动时,约为12.5GB,稳定后完全可控。查询性能方面,首次访问因预热需要约30秒,后续所有查询的延迟都稳稳地控制在100毫秒之内。
为什么FLAT能扛住2500万向量
FLAT是Milvus中最基础的索引类型——不建树、不构图、不聚类,查询时直接在原始向量上进行暴力计算。按常理推断,对2500万条数据做暴力搜索,无论内存还是延迟都应该是天文数字。但Milvus通过三层优化的叠加,让这个“笨办法”成了当前场景下的最优解。
优化一:FP16精度压缩,向量体积直接减半
第一重优化在于存储精度。将向量从FP32精度降至FP16:
- 单条向量:1280维 × 4字节 = 5120字节 → 1280维 × 2字节 = 2560字节
- 2500万条总量:约120GB → 约60GB
关键在于,FP16在绝大多数向量检索场景下,其精度损失微乎其微(Recall差异通常小于0.1%),但带来的收益是存储和内存占用直接对半砍。这是一笔非常划算的交易。
优化二:Mmap技术,内存不够磁盘来凑
即使用上FP16,60GB的数据量依然远超16GB的物理内存预算。第二把钥匙是内存映射文件技术。
FLAT索引没有额外的数据结构,所有数据就是原始向量本身。开启mmap后,向量数据不再需要全部加载到物理内存中,而是以内存映射文件的方式驻留在磁盘上。操作系统会按需将访问到的数据页动态加载进内存。这相当于用磁盘空间换取了宝贵的内存资源,实现了内存占用的大幅节省。
从Milvus 2.6版本开始,向量原始数据的mmap默认就是开启的。这位朋友使用的Milvus 2.6.14,实际上并未手动配置,集群级的默认配置已经悄然生效。
这里有个细节需要注意:Attu管理界面上显示的是Schema级别的mmap配置,它不会反映集群级的默认值。因此,在Attu上看到mmap显示为“关闭”时,实际上集群级可能已经启用了。
当然,任何技术都有权衡。内存省下来了,代价是磁盘需要多占用约60GB的空间。对于一台配备了SSD的现代服务器而言,这个代价完全可以接受。
优化三:标量过滤,真正的性能翻跟斗
FP16减半了数据量,mmap解决了内存瓶颈,那么最关键的延迟问题呢?2500万条数据的暴力搜索如何能做到毫秒级响应?答案藏在查询模式里。
这位朋友的每次查询都带有明确的标量过滤条件,其表达式类似于:dataid in [123] AND classid in [0, 2, 3]。
这个表达式会先在标量字段上进行筛选,将2500万条的庞大候选集,迅速缩小到几百甚至几万条。随后,FLAT的暴力搜索只需要在这个极小的子集上执行。对几万条向量进行暴力比较,在现代CPU上不过是毫秒间的事情。
同时,结合前述的mmap机制,系统只需要将符合过滤条件的少量向量数据页从磁盘加载到内存进行计算,使得内存消耗也能保持在极低水平。
这也解释了为什么FLAT在此场景下能战胜IVF_FLAT和HNSW:当标量过滤已经将候选集压缩到极小的范围时,额外的索引结构反而成了负担——它们占用内存、消耗构建时间,但对最终的检索速度贡献却微乎其微。
另外值得注意的一点是,这个场景中的过滤表达式相对简单。对于更复杂的过滤条件,例如使用LIKE操作符、IN包含超大列表,或者对JSON字段进行多层过滤时,过滤阶段本身可能成为瓶颈。在这种情况下,为标量字段创建合适的标量索引,将是降低过滤延时、进一步提升整体性能的关键。
不只是以图搜图
这个以图搜图的案例揭示了一个高效的核心模式:强标量过滤 + 实际搜索数据量远小于总量。符合这一模式的场景远不止于此:
- 多租户RAG系统:按
tenant_id过滤后,单个租户内的数据量通常仅为数千到数万条,FLAT游刃有余。 - 电商商品搜索:先按品类、品牌、价格区间等属性筛选,再在子集内进行相似商品或语义搜索。
- 日志与文档检索:按时间范围、来源、标签等条件过滤后,再进行语义相关性查找。
这类场景都可以借鉴上述的“FLAT + FP16 + Mmap”组合方案,在享受极低内存开销的同时,获得令人满意的检索性能。
最后,关于资源规划,有一个重要的认知需要澄清。在这位社区朋友的案例中,Sizing Tool按照“全量数据加载到内存”的保守模型进行估算,得出139GB的内存需求。这个数值旨在确保系统在最坏情况下也能运行,是一个安全值。
但在实际部署中,真实的内存需求受到多重因素影响:向量精度、索引类型、标量过滤的强度以及是否启用mmap等。因此,最可靠的资源规划方式,是基于自己真实的业务负载和数据特征进行实际测试和验证。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:向量数据库Milvus如何用FLAT实现毫秒级响应与强标量过滤要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点受全球生成式AI浪潮推高算力需求影响,DDR5内存价格持续飙升。德国零售市场数据显示,2026年6月DDR5整体价格指数已攀升至2025年7月同期水平的419%。其中,2×32GBDDR5-6000CL28套条从去年7月的约1600元人民币暴涨至近7800元。业内分析指出,上游存储厂商在2027
近期,全球多家大模型厂商,包括行业龙头OpenAI,纷纷宣布下调其核心计价单位Token的价格,以回应市场对AI应用成本过高的关切。分析指出,这不仅是简单的价格调整,更标志着AI行业竞争进入新阶段。在头部企业筹备上市的背景下,市场估值逻辑转向,能否以更低成本获取并留住用户成为关键。此次降价潮反映了行
据行业媒体报道,索尼旗下知名游戏工作室Bungie可能于今年夏季启动大规模裁员,受影响员工比例或高达50%,涉及人数约400人。此次裁员传闻主要源于工作室两大核心项目发展遇冷:《命运2》已停止更新且续作开发未获批准,而新作《马拉松》的市场表现与营收未达预期。目前工作室暂无全新主力研发项目接替,导致现
工业和信息化部近日更新了《道路机动车辆生产企业及产品公告》,一汽夏利、华晨自主、众泰、猎豹、力帆、华泰、北汽银翔(幻速)、老海马共八家老牌汽车企业被正式移出车企名录,其整车生产资质被冻结并永久失效。这意味着这些企业从法律和工业生产层面已不具备合法生产整车的资格,相关工厂将停工、生产线封存。例如,浙江
- 日榜
- 周榜
- 月榜
热点快看