




Deepseek API价格表解析:大模型输入输出成本详解

使用DeepSeek V4 API撰写一份1000字的商业计划书,究竟需要多少成本? 答案是:不到3分钱,精确计算甚至低于3厘。 这并非夸张的比喻,而是基于实际计费规则得出的精确数字。然而,这里存在一个至关重要的前提——如果你不了解“缓存命中”这一核心机制,完成同样的任务,你的API开支可能高达他人
使用DeepSeek V4 API撰写一份1000字的商业计划书,究竟需要多少成本?
答案是:不到3分钱,精确计算甚至低于3厘。
这并非夸张的比喻,而是基于实际计费规则得出的精确数字。然而,这里存在一个至关重要的前提——如果你不了解“缓存命中”这一核心机制,完成同样的任务,你的API开支可能高达他人的50倍。
初次解读大模型API价格表:常见的认知误区
“输入1元/百万Token?输出2元/百万Token?这到底意味着什么成本?”
面对这样的计价单位,用户通常会产生两种直觉反应:一是认为“百万Token听起来数量巨大,应该非常便宜”;二是走向另一极端,觉得“百万Token才几块钱,可以随意使用”。
这两种理解都存在偏差。实际情况往往比直觉更加反常识——使用方法得当,成本堪比白菜价;使用方式不当,你的账单将在不知不觉中持续失血。
接下来,我们将以DeepSeek V4官方定价体系为例,彻底解析其计费逻辑与优化策略。
建立准确认知:Token与“字数”的换算关系
许多用户误以为计费直接按中文字数计算,实则不然。大模型API的统一计费单位是Token。
Token与字数的换算关系其实很清晰:
- 中文文本:1个汉字 ≈ 1.3个Token
- 英文文本:1个单词 ≈ 1.3个Token
逆向换算,100万Token(即计费单位“百万Token”)大约相当于77万个汉字。这个文本量级接近《三体》第一部全书的篇幅。
建立这杆衡量标尺后,再审视价格表,你就能形成具体的成本画面。
价格表中“输入/输出”的分类,可以简单理解为:
- 输入(Input):指你提交给模型的所有内容,包括当前提问、历史对话记录、系统指令(Prompt)等,均计入输入Token
- 输出(Output):指模型根据你的输入所生成的全部回复内容,独立计算输出Token
深度解析:一张真实的DeepSeek V4价格表
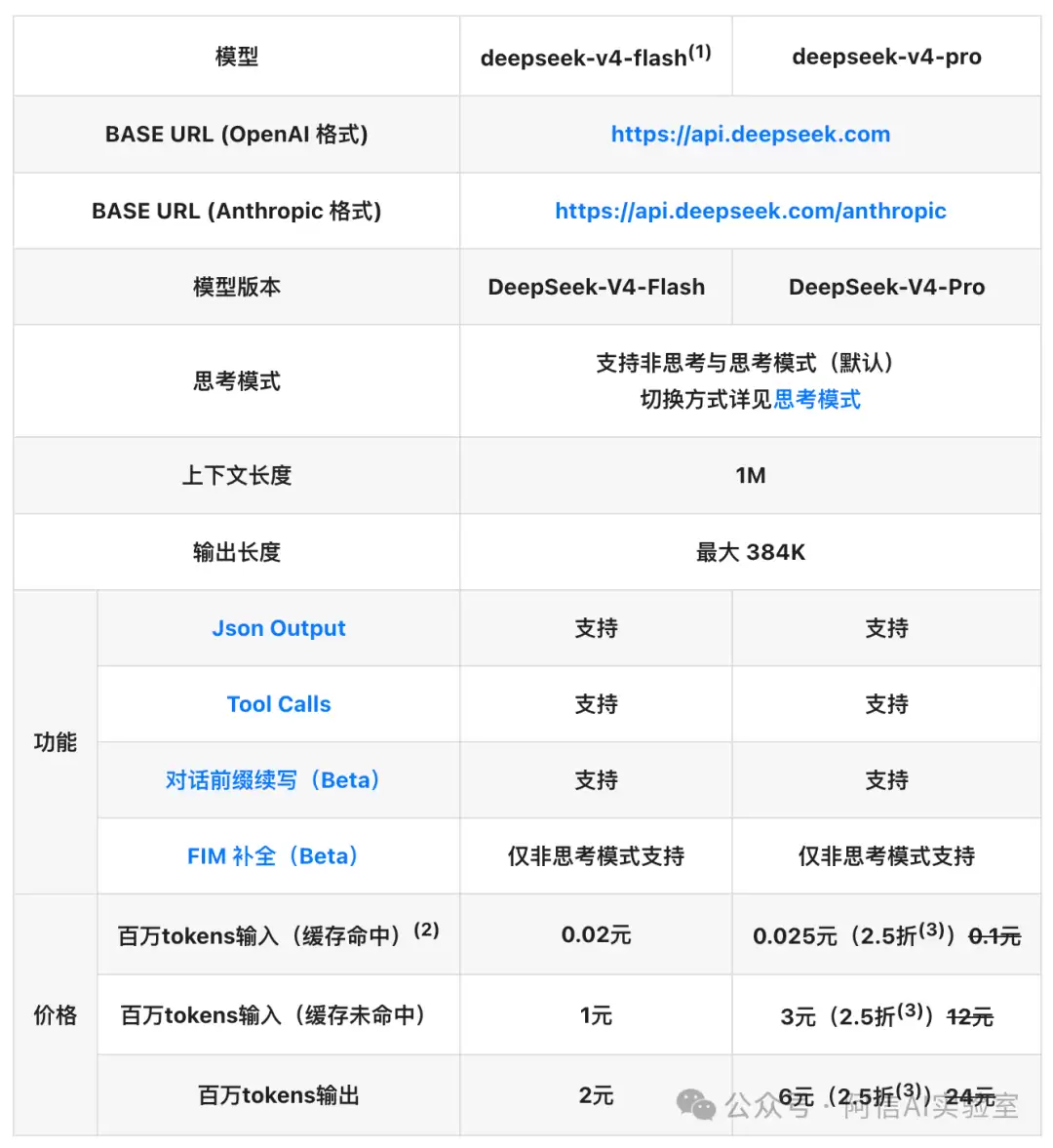
以deepseek-v4-flash版本为例,其价格表包含三行关键数据:
| 费用类型 | 单价(元/百万Token) | 通俗解释 |
|---|---|---|
| 输入(缓存命中) | 0.02元 | 系统识别该段内容,直接调用缓存结果,成本极低 |
| 输入(缓存未命中) | 1元 | 系统需重新处理该内容,成本是缓存价的50倍 |
| 输出 | 2元 | 模型生成全新回答,固定价格,不享受缓存优惠 |
此处隐藏着一个绝大多数用户未曾察觉的成本秘密:第二行与第一行之间的巨大价差。
那么,什么是“缓存命中”?
简而言之,当你的系统提示词、对话上下文与之前的某次请求高度相似或完全相同时,DeepSeek不会重复进行底层计算,而是直接复用已处理的中间结果,这使得输入成本立即降至原来的1/50。
对于长对话交互、多轮调用、固定系统提示词的业务场景,这一机制意味着实实在在的成本节约。
而deepseek-v4-pro版本的价差更为显著——其缓存未命中的输入单价为12元/百万Token,输出单价为24元/百万Token,分别是Flash版本的12倍。
模型能力越强大,缓存优化带来的经济效益就越显著。
实战测算:两种典型场景的成本分析
场景一:撰写一份1000字的商业方案
假设你提交给模型的提示词约200Token(相当于150字)。模型生成一篇1000字的方案,约1300Token。
若为首次请求,缓存未命中。使用deepseek-v4-flash计算:
- 输入费用:200 ÷ 1,000,000 × 1元 = 0.0002元
- 输出费用:1300 ÷ 1,000,000 × 2元 = 0.0026元
总成本:0.0028元。确实不到3厘钱。
场景二:基于固定系统提示词的长对话交互
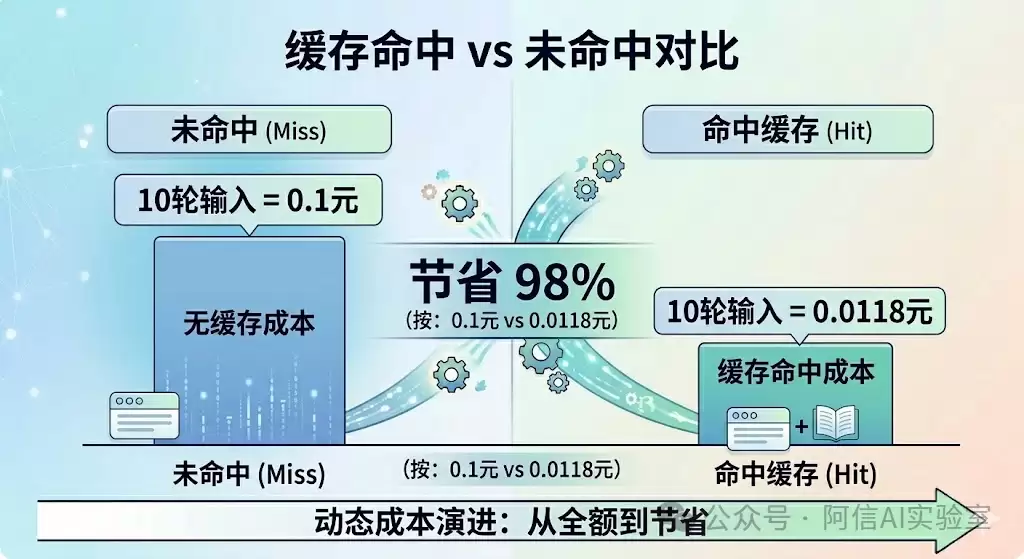
假设你有一套10,000 Token的系统提示词(约7700字),与模型进行10轮对话:
- 第1轮,输入10,000 Token,缓存未命中:
10,000 / 1,000,000 × 1 = 0.01元 - 第2-10轮,同一段提示词命中缓存:
10,000 / 1,000,000 × 0.02 = 0.0002元/次 - 假设每轮输出500 Token,总输出成本:10 × 500 × 2 / 1,000,000 = 0.01元
10轮对话总成本:0.01 + 9 × 0.0002 + 0.01 = 0.0218元。约两分钱。
若无缓存机制,仅输入部分成本就将达到0.1元。
缓存机制为你节省了高达98%的输入成本。
核心要点:四个必须掌握的API成本优化结论
1. 输出成本通常是主要开支
输入端有缓存机制作为成本缓冲,而输出端没有。撰写长文、生成代码等任务的主要花费集中在输出Token上。
2. 缓存是大模型计费体系中最大的“隐形折扣”
这并非需要手动领取的优惠,而是系统自动触发的优化机制。当系统提示词和对话上下文重复时,缓存自动生效。许多开发者使用半年后仍不了解此功能。
3. Flash与Pro版本的价格差异体现了“性价比与性能”的权衡
Flash版输入(未命中)1元,Pro版原价12元,相差12倍。并非所有任务都需要Pro版的顶级性能,大多数日常场景Flash版本已绰绰有余。
4. 通用成本计算公式(建议收藏)
总费用 = (输入Token数 ÷ 1,000,000 × 输入单价) + (输出Token数 ÷ 1,000,000 × 输出单价)
其中输入单价取决于请求是否命中缓存。
最终总结:大模型API的成本既没有你想象的那么昂贵,也没有你想象的那么廉价。昂贵与廉价之间的区别,取决于你对这张价格表的理解深度。
3厘钱生成一篇方案是事实。两分钱完成十轮对话也是事实。
实现这一切的前提是——你真正理解“缓存命中”这一行的意义。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Deepseek API价格表解析:大模型输入输出成本详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看