




腾讯混元AI Infra开源核心技术 推理吞吐性能提升30%

腾讯开源高性能大模型推理算子库HPC-Ops,针对主流推理卡算子性能不足,通过硬件深度适配与指令级优化,显著提升核心算子效率。实测使混元模型推理吞吐提升30%,关键算子性能最高提升2 22倍。它提供简洁API,支持主流推理框架与多精度量化,降低了高性能CUDA开发门槛。
大模型推理的效率优化,已成为AI应用开发与部署的关键挑战。面对线上服务中硬件成本、算力资源与性能需求的复杂平衡,技术团队亟需更高效的底层解决方案。近日,腾讯混元AI Infra团队正式开源了高性能LLM推理核心算子库HPC-Ops,旨在从算力底层突破瓶颈,为大模型推理提供生产级的高性能加速支持。
HPC-Ops是一个基于CUDA与CuTe从零构建的生产级核心算子库。其设计目标清晰:通过高度抽象的工程架构、对硬件微架构的深度适配以及指令级极致优化,将关键算子的执行效率逼近硬件理论峰值,从而显著提升大模型推理的整体吞吐与能效。根据官方实测数据,在真实业务负载下,基于HPC-Ops优化后,混元模型的推理QPM(每分钟查询数)提升达30%,DeepSeek模型的QPM也实现了17%的增长。
为何需要专门针对推理场景开发新的算子库?这源于当前业界普遍存在的实践痛点。
目前,主流的大模型算子库(例如FlashInfer、DeepGEMM)的优化重点,大多集中于NVIDIA H800等高端训练卡。然而,受成本控制、供应链等因素影响,实际线上推理服务大量采用的却是H20等推理专用卡。现有先进算子库在这些主流推理卡上,往往难以充分发挥硬件潜能。同时,业务侧对高吞吐、低延迟以及Blockwise FP8等复杂量化策略的需求日益强烈,对底层算子的兼容性与性能提出了更高要求。
具体而言,现有方案主要面临两大核心挑战:
- 二次开发与适配成本高:主流算子库设计复杂,核心Kernel封装层次深,在其基础上进行定制化修改和硬件适配的工程门槛很高。这对于广大AI工程师与研究者而言并不友好。而大模型前沿加速技术,如新型量化算法、投机采样(Speculative Decoding)等,都高度依赖与之匹配的高效算子实现。回顾历史,早期的4bit、8bit量化算法虽理论优势明显,却因缺乏配套的低精度高效算子,在相当长时间内实际部署效果甚至成为“负优化”。
- 目标硬件架构不匹配:现有库多针对H800乃至更超前的Blackwell架构进行深度优化。然而,不同硬件在计算单元、内存带宽、缓存层次上的差异,决定了Kernel的优化策略必须差异化设计。这导致现有算子库在国内主流推理卡上的性能表现,经常达不到预期效果。
正是基于这些实际痛点,腾讯混元团队自主研发了HPC-Ops。它集成了FusedMoE、Attention、机内/机间通信、Norm、Sampler以及各类小算子融合等核心模块。其核心技术理念可归纳为以下三点:
第一,实现任务特性与硬件能力的精准匹配。 对于受限于内存访问带宽的算子,性能关键在于数据加载效率。HPC-Ops针对国内主流推理显卡,通过精细调整指令发射顺序进行数据预取优化,确保数据搬运单元持续高负载运行。同时,针对不同问题规模进行更细致的指令流对齐,消除冗余低效指令。例如,在解码阶段Attention(Decode Attention)和小批次GroupGEMM场景中,通过交换计算矩阵A与B的顺序,使其对齐硬件架构的wgmma指令要求,从而让访存带宽利用率达到硬件峰值能力的80%以上。
第二,实施精细化的任务调度与数据布局重排。 针对每个算子的计算问题,重新设计任务划分与调度策略,在保证每个流多处理器(SM)负载均衡的同时,兼顾数据在缓存中的连续性。采用持久化内核(persistent kernel)模式,隐藏内核启动与收尾的开销。此外,通过创新的数据重排技术减少额外数据操作和显存占用。例如,在FP8精度的Attention Kernel中,采用了交织(Interleave)重排技术,有效解决了指令匹配问题,减少了线程间的数据交换(shuffle)操作,从而获得了超越业界标杆的性能表现。
第三,让开发者聚焦于算法与计算逻辑创新。 GPU编程的复杂性常源于底层数据操作的繁琐。为了调用高效硬件指令,通常需要对数据进行多次重解释与格式变换,这极大增加了开发者的心智负担。HPC-Ops基于CuTe扩展开发了向量(vec)抽象层,统一负责高效的数据搬运,并利用布局(Layout)代数抽象隔离复杂的分块(Tiling)与计算逻辑,使得开发者能更专注于核心算法创新,显著降低了高性能CUDA内核的开发和维护门槛。
核心性能基准测试结果
通过上述系统性优化,HPC-Ops在关键算子模块上实现了显著的性能突破。测试基于混元、DeepSeek等常见模型规格,并与当前主流算子库的实现进行了全面对比:
GroupGEMM:与DeepGEMM (v2.2.0)对比,在Batch≤64的低延迟推理场景下优势明显,较DeepGEMM最佳性能最高提升1.88倍,并通过流水线掩盖技术使Blockwise量化与PerTensor量化的性能几乎持平;在大Batch高吞吐场景下,仍能保持约1.1倍的性能领先。该算子同时兼容紧密内存排布与Token不连续输入,显著减少了临时显存占用。
FusedMoE:该模块完整封装了前序数据重排、GroupGEMM及后续Reduce加权平均的全流程。在序列长度为16倍数的均衡规格下,对比vLLM (v0.11.0)与TensorRT-LLM (v1.1.0)的实现,在张量并行(TP)场景下相比TensorRT-LLM最大性能提升达1.49倍;在专家并行(EP)模拟均衡负载场景下最大提升1.09倍。针对不同输入长度采取的差异化数据重排策略,确保了模块在各种规格下均能获得最优性能。
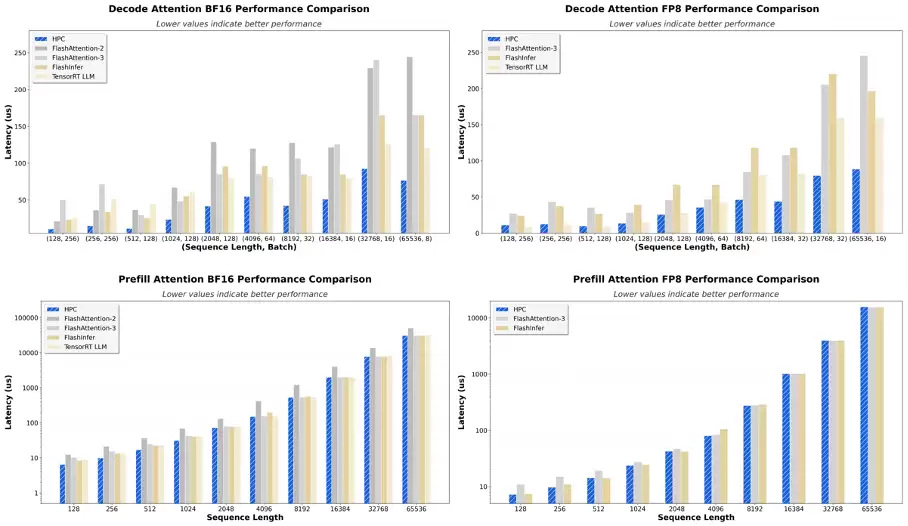
Attention:针对预填充(Prefill)阶段,测试了128~64K的输入长度范围。在batch较小时,BF16精度下相比当前最优实现性能提升1.3倍;在大batch时性能与当前最优水平基本持平。针对解码(Decode)阶段,根据线上服务等级目标(SLO)约束设计测试用例,在BF16精度下性能提升范围达1.35倍~2.22倍;在FP8精度下,当序列长度较小时与最优水平相当,当序列长度较大时相比最优实现提升1.09倍~2.0倍。
算子库核心能力与未来演进规划
作为专为大模型推理设计的高性能算子库,HPC-Ops通过对Attention、FusedMoE、GroupGEMM等核心算子的深度优化,实现了最高2.22倍的性能加速,并已在腾讯内部大规模生产环境中得到充分验证。它提供了简洁易用的API接口,能够无缝对接vLLM、SGLang等主流推理框架,并原生支持BF16、FP8等多种精度量化方案。尤为重要的是,它以CuTe、CUTLASS等先进抽象为基础,提供了仅需数百行代码即可构建高性能算子的实践范例,极大降低了高性能CUDA内核的开发难度。
展望未来,HPC-Ops将持续聚焦大模型推理的性能前沿。一方面,将重点研发稀疏Attention(Sparse Attention)算子,针对性解决长上下文模型面临的内存与计算瓶颈;另一方面,将拓展更丰富的量化策略支持,覆盖4bit/8bit混合精度等更多方案,以进一步平衡推理速度与模型精度。此外,算子库还将布局计算-通信协同优化的融合内核,通过将多GPU间的计算逻辑与通信流程深度融合,大幅降低分布式推理场景下的通信开销,为千亿乃至万亿参数超大模型的高效、稳定部署提供坚实的底层算力支撑。
目前,HPC-Ops项目已在GitHub全面开源。腾讯混元Infra团队也表示,诚挚欢迎业界的技术专家与实践者提交高价值的代码提交(PR),共同参与算子边缘场景优化、教程与案例完善等工作,携手推进大模型推理效率的技术边界。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:腾讯混元AI Infra开源核心技术 推理吞吐性能提升30%要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看