




推理能力超越博士生 OpenAI o1模型详解

OpenAIo1系列模型在科学、编程和数学等复杂推理任务中表现卓越,多项基准测试成绩远超GPT-4o,达到博士生水平;同时安全性能显著提升,并推出低成本o1-mini版本。
在 AI 的世界里,OpenAI 又一次把自己推到了新的高度。这次,随着 o1 系列模型的正式亮相,AI 的推理能力被拉上了一个全新的台阶。如果你平时关注科学、编程或数学这些复杂问题领域,那这个系列模型,很可能就是你一直在等的“秘密武器”。
今天的文章,咱们就一起来深入看看这个技术突破到底牛在哪儿,以及它怎么重新定义了 AI 的思考方式。
OpenAI o1:深度推理的革命性 AI 模型
o1 系列真正的魅力,在于它模拟人类思考过程的那种“深度推理”能力。
这到底是什么意思?很简单,它不是一个急着给你答案的机器,而更像一个耐心的思考者——拿到问题后,它会反复推敲、不断试错,直到找到最优解。就像你面对一道超难的数学题,反复尝试不同解法,直到突然想通——o1 的工作方式,就是这个逻辑。
实际测试结果相当惊艳。在 2024 年国际数学奥林匹克资格考试中,GPT-4o 的正确率只有 13%,而 o1 模型直接飙到了 83%。在 Codeforces 编程竞赛中,o1 的表现也达到了人类选手的 89 百分位,远远甩开了之前的模型。换句话说,在数学和编程这些硬核领域,o1 展现出了近乎博士生级别的水准。
o1在具有挑战性的推理基准测试中大大优于GPT-4o。实心条表示pass@1准确率,阴影区域表示使用64个样本的多数投票(共识)性能。
性能对比:数据不会撒谎
用数据说话可能更直观——来看看 o1 在几项核心基准测试中的表现:
- AIME(2024):GPT-4o 13.4% → o1 83.3%
- CodeForces:GPT-4o 11% → o1 89%
- GPQA Diamond:GPT-4o 50.6% → o1 77.3%
- 物理:GPT-4o 59.5% → o1 92.8%
- 数学:GPT-4o 60.3% → o1 94.8%
这些数字背后透露出的信息很明确:o1 不只是在某个单项上领先,而是在科学、编程和数学这些高难度推理任务中,始终保持了极高的精准度。
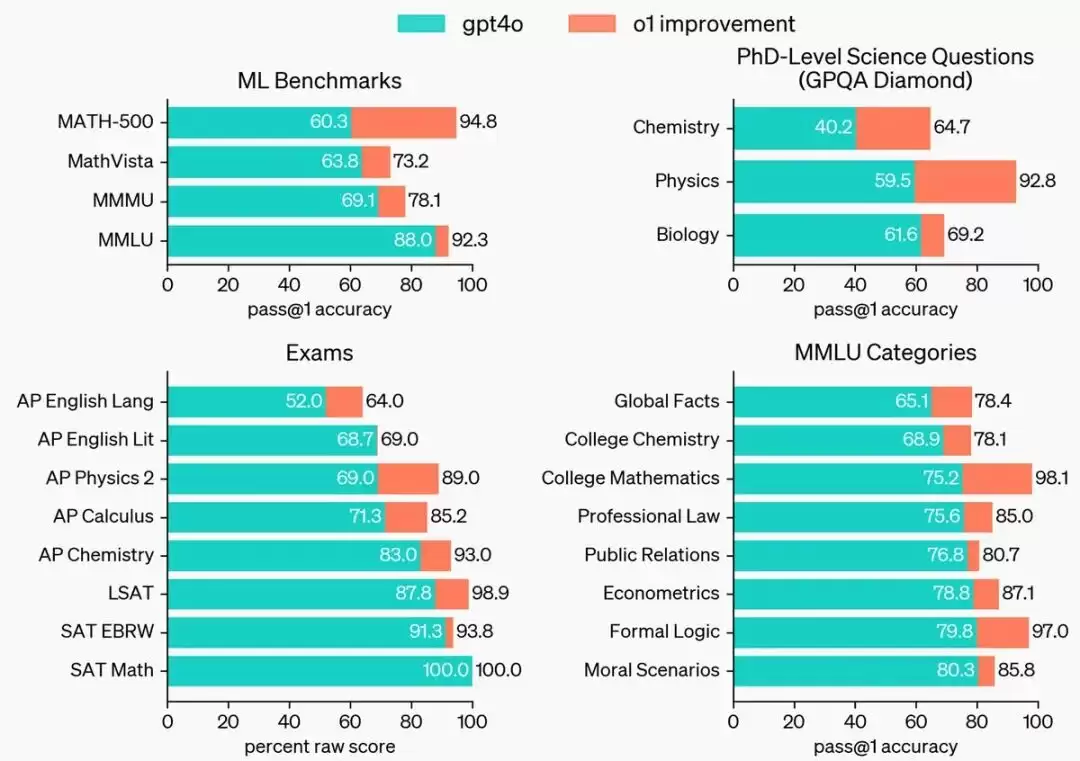
o1在广泛的基准测试上优于GPT-4o,包括54/57个MMLU子类别。这里展示了其中的七个作为示例。
安全性:推理能力与安全性的双重保障
看到这儿你可能会想:推理能力变强了,安不安全?这恰恰是 OpenAI 在设计 o1 时重点考虑的问题。
为了确保模型在复杂推理中始终守住安全底线,OpenAI 引入了一套全新的安全训练方法。这让 o1 不仅能理解更复杂的上下文,还能严格遵循安全和合规的指引。
举个例子:在“越狱测试”中——也就是用户试图绕过安全规则的极限测试——GPT-4o 的得分只有 22,而 o1-preview 直接飙升到了 84。换句话说,面对恶意输入,o1 的表现要稳健得多。
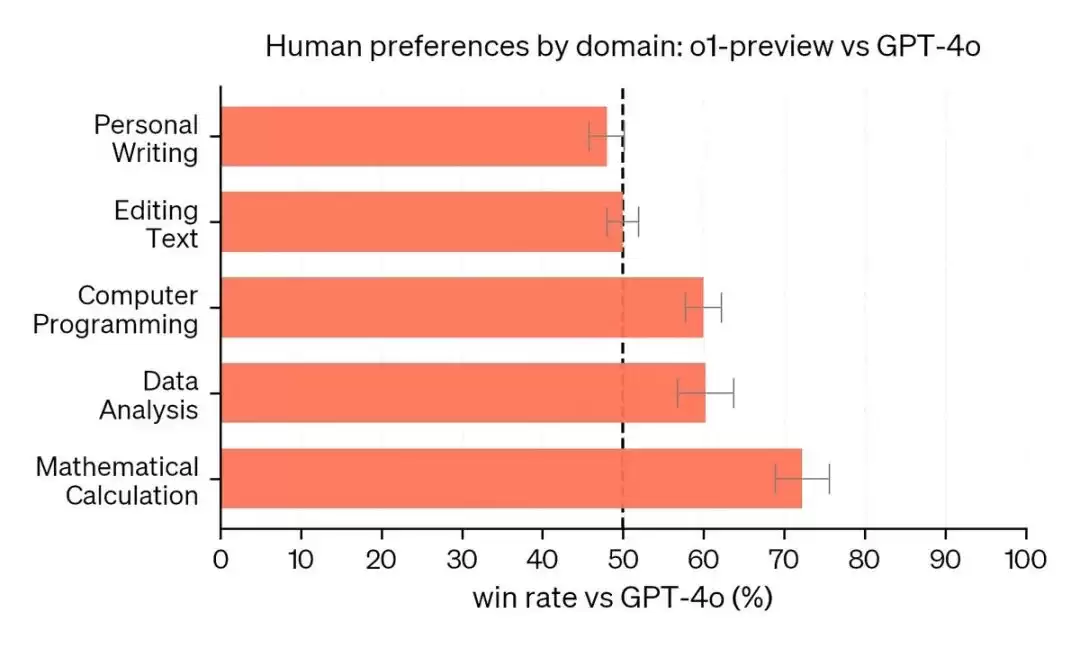
在人们更看重推理能力的领域,o1-preview表现得更出色。
安全性数据对比:稳健的守护者
- 标准有害提示下的安全完成率:GPT-4o 99.0% → o1 99.5%
- 越狱测试:GPT-4o 22 → o1 84
- 暴力或犯罪骚扰:GPT-4o 84.5% → o1 90%
- 非法性内容:GPT-4o 48.3% → o1 94.9%
- 自我伤害建议:GPT-4o 76.9% → o1 92.3%
结论很清楚:o1 不仅聪明,还懂得如何在复杂环境中保护自己和用户。它不只是个强大的助手,更是一个值得信赖的伙伴。
OpenAI o1-mini:高效推理的经济之选
当然,不是所有场景都需要最强算力。如果你追求更快的速度和更低的成本,o1-mini 可能是更实际的选择。
它的推理能力相比 o1-preview 有一定削弱,但在编程任务中依然表现出色,关键是运行成本比 o1-preview 低了 80%。这意味着你可以用更少的资源,完成高效的工作。
适用场景:科学、编程与数学领域的突破
那么,o1 模型到底能用在哪?无论你是研究人员、开发者还是科学家,它都能提供实打实的支持。
- 研究人员可以用它分析细胞测序数据
- 物理学家可以用它生成复杂的量子光学公式
- 开发者则能用它构建多步骤的工作流
应用场景几乎是无穷无尽的。
使用指南:如何开始你的 o1 之旅
如果你已经跃跃欲试,具体怎么上手?目前,ChatGPT Plus 和 Team 用户可以直接在 ChatGPT 界面手动选择 o1-preview 或 o1-mini 模型。早期阶段,每周分别限制为 30 条和 50 条消息。
对于 ChatGPT Enterprise 和 Edu 用户,这两款模型将在下周开放使用。开发者也可以通过 API 直接调用。
展望未来:更多惊喜即将到来
值得强调的是,o1 系列目前还处于预览阶段,但这仅仅是个开始。OpenAI 计划为这些模型陆续增加浏览、文件上传和图片上传等功能,让它们在未来更好地满足实际需求。
与此同时,GPT 系列模型的开发也会持续并行推进,给用户更多样化的选择。
结语:AI 的未来,由你掌控
OpenAI o1 系列模型不只是 AI 推理能力的又一次飞跃,它更像是打开了一扇通往新可能性的大门。无论是科学、编程还是数学领域,o1 都有可能成为不可或缺的得力助手。
未来的 AI 世界已经在悄然变化,而你,正是这场变革的见证者和参与者。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:推理能力超越博士生 OpenAI o1模型详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看