




OpenAI o1深度解析:揭秘草莓项目真相

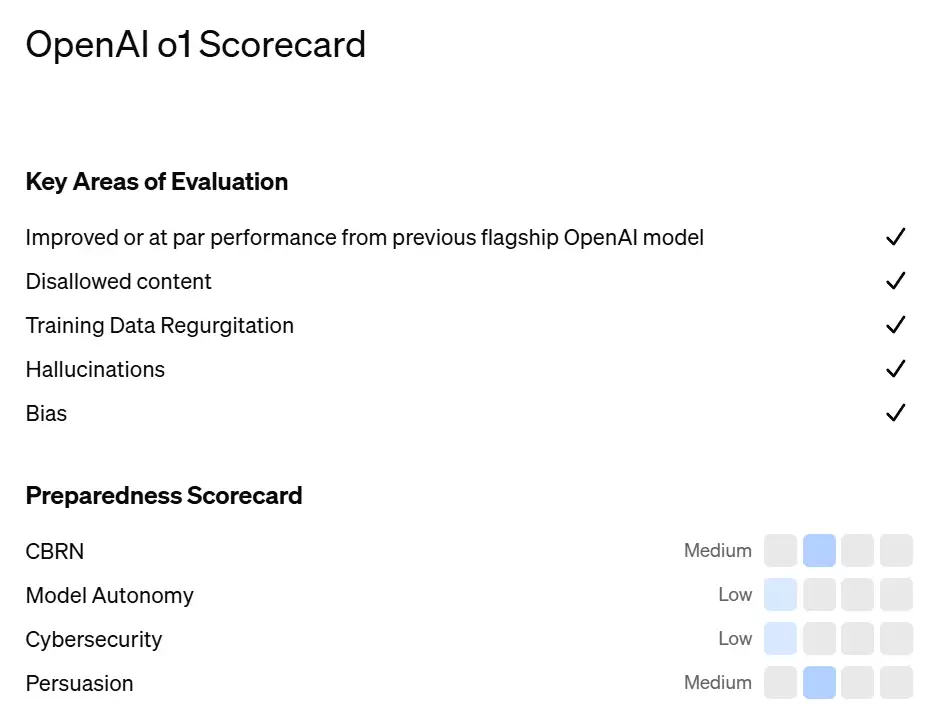
OpenAI发布o1系列模型,通过强化学习使模型在回复前进行更长时间思考,模仿人类复杂推理过程。其在GPQADiamond、AIME数学竞赛和Codeforces编程竞赛中表现远超GPT-4o,推理能力达博士级水平,但非全方面碾压,且存在一定幻觉问题。
北京时间凌晨一点左右,OpenAI 正式发布 o1 系列模型——正是此前业界传闻许久的“草莓”模型。消息来得十分突然,技术爱好者们第一时间收到推送,瞬间睡意全无。此次一口气推出两款模型、十几个演示视频以及 43 页技术论文,直接让人熬夜开干。还没睡的伙伴,集合!组队研究!
o1 系列的核心亮点在于:它在生成回答前会花更多时间进行深入思考,模仿人类拆解复杂问题的推理方式,而且思考时间越长,在推理任务上的表现就越出色。这一机制标志着 o1 朝着无限推理模型迈出了关键一步,也将 AI 在复杂推理任务上的能力提升到了全新高度。正因如此,OpenAI 将计数器重置为 1,把这个新系列命名为“OpenAI o1”。与之前各种“期货”不同,这次直接上线,毫不拖延。
简介与评估
简单来说,OpenAI o1 系列模型在复杂推理性能上的提升,与传统大语言模型依靠预训练规模扩展的路径完全不同——它通过强化学习的方式,让模型持续优化自身的思考过程,包括尝试不同策略、识别并纠正错误等。正是这一全新的训练范式,赋予了 o1 模型博士级别的推理能力。而且从技术报告来看,这一模式具备进一步扩展的潜力。
下面具体来看,o1 在这一新训练模式下展现出的惊人性能。观察下图可以发现,o1 在各类机器学习基准测试中全面超越 GPT-4o(注:pass@1 指一次通过率):
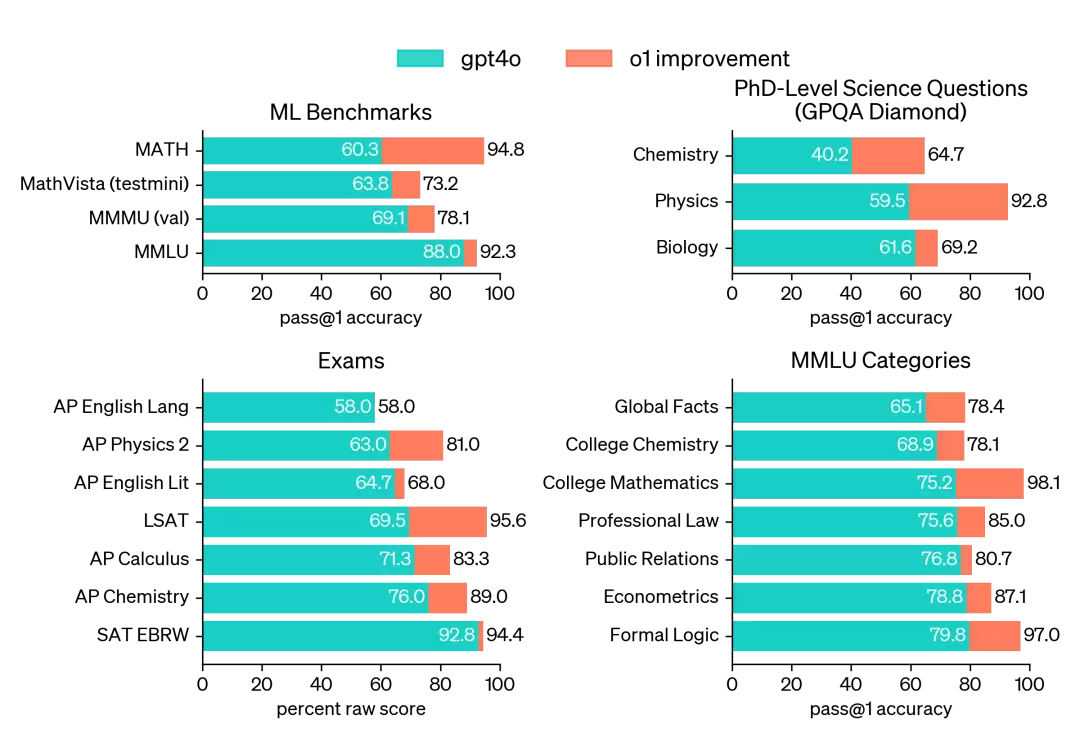
在 GPQA Diamond* 上,o1 甚至成为首个击败人类专家的模型。虽然不能直接断言 o1 能力全面超过人类专家,但足以证明其“博士级”的推理思考能力。GPQA Diamond:一个高难度的智力基准,测试化学、物理和生物学方面的专业知识。实线表示一次通过的准确率,阴影区域显示 64 个样本的平均性能。
在文科类评估中,o1 相比 4o 提升不算太大,但逻辑推理方面,o1 明显优于 4o。值得关注的是,为了展示 o1 的逻辑推理能力,OpenAI 选择了 AIME 作为测试基准——这是美国数学竞赛中仅次于奥林匹克数学竞赛的高难度项目,题目极其灵活。o1 在这一基准上的表现:在单样本提示下,平均得分 74%;在 64 个样本的共识中达到 83%;最令人惊讶的是,使用 1000 样本时得分高达 93%,足以进入美国前 500 名。
至于编程能力,OpenAI 以 o1 为基础,经过持续训练优化后的模型,最终在模拟 Codeforces 编程竞赛中得分 1807,超过 93% 的人类参赛者,而 GPT-4o 仅获得 808 分。
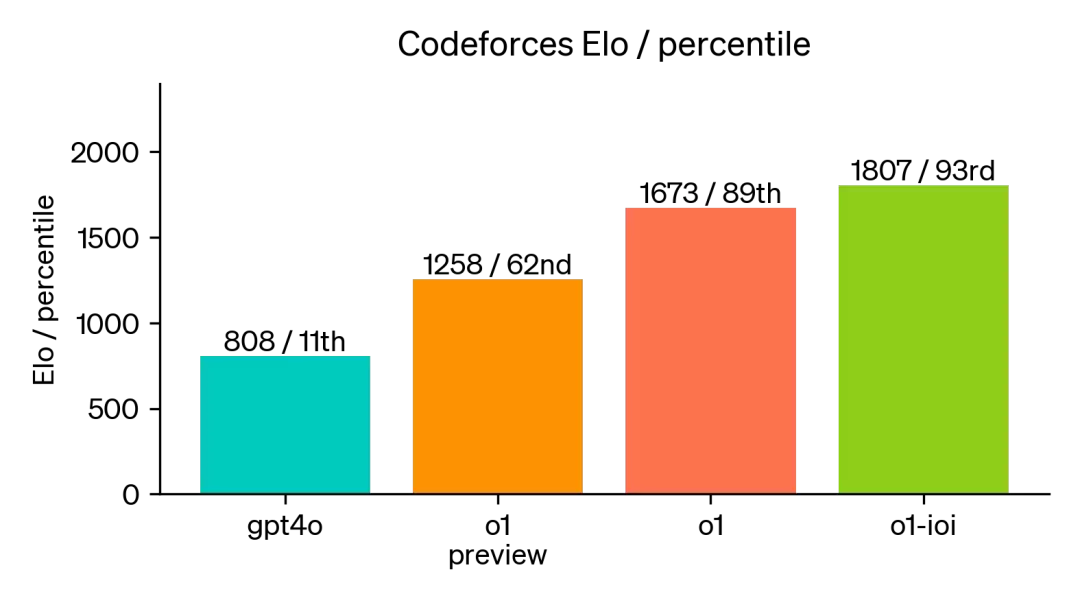
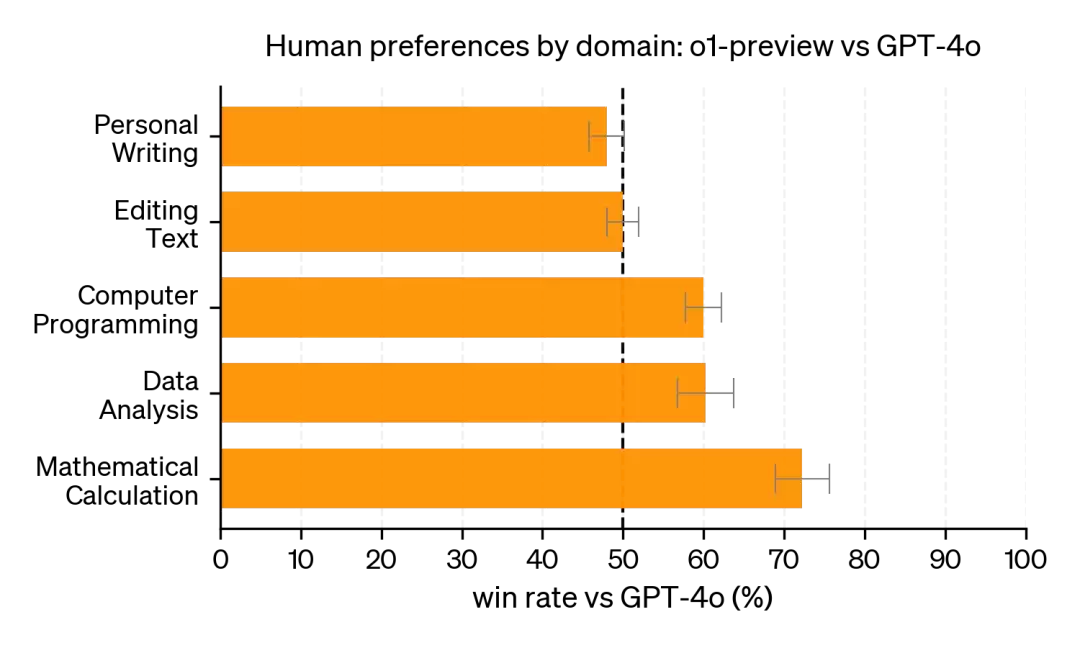
在人类偏好评估方面,除了复杂推理场景外,o1-preview 相比 4o 也占据明显优势。不过在推理需求不高的场景下,用户仍然更倾向于选择 4o 模型。
安全方面,整体表现相比 4o 保持改进或持平。
CoT(思维链)
除了推理能力的显著提升,思维链的引入让 o1 相比 4o 实现了能力的飞跃。o1 在尝试解决问题时,会先进行一系列思维链推导——其中包括识别并纠正错误、拆解与规划问题、尝试不同策略。这不正是人类解决复杂问题的典型方式吗?
官方提供了 Code、Math、Science 等场景下的真实案例,并展示了 CoT 的完整过程。其中数学方面的案例尤其值得关注,因为以往的大语言模型在数学回答中常常存在大量论断不严谨、过程不完整的问题,在不调用外部计算器的情况下,计算也经常出错。
原理
在 OpenAI 官网上有一张图,简单解释如下:
- 用户输入问题后,o1 相比之前 GPT 系列模型多使用一个叫做“推理标记”的机制。可以理解为它学会了像人一样选择在何时进行思考,并输出当前的想法,但这些“推理标记”中的思考内容并不会直接展示给用户。这也是为什么有体验者反馈模型等待时间较长——因为思考过程并不会显式呈现。
- 在新一轮对话中(用户第二次输入),上一轮“思考”的内容会被全部清空,重新开始全新的“思考”。
- 依此类推,当对话达到 128k Tokens 的上限时,模型会给出一个“删减版”答案,避免用户白等却碰到上下文限制。
这一做法让人联想到当年它的内部代号曾叫 Q*,而 Star 的由来与 StaR 系列论文密切相关。其中《Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking》的方法与 OpenAI 在 o1 中的实现有许多相似之处。Life can only be understood backward, but it must be lived forward - Søren Kierkegaard(Quiet-STaR 在论文摘要中引用了这句话,颇具深意)
官方演示视频
OpenAI 一口气发布了十几个演示视频,技术爱好者们无不惊叹。以下是一些精选案例:
1. 数 strawberry 中 r 的个数。
2. 制作可在 HTML 上运行的贪吃蛇小游戏。
3. 将存在错误和不顺畅的韩语正确翻译为英文。
4. 破解逻辑谜题。
5. 解答数学题。
总结(o1 很强,但不必盲目吹捧)
从 OpenAI 的文章来看,无论用户反馈还是实际评估,o1 更多是弥补了此前大模型在推理能力上的短板,而非全方位碾压所有模型——术业有专攻,选择适合的才是最好的。
OpenAI 目前仅采用了简单的 self-play 训练,思维模式仍然难以完全解析,很难说 o1 已经形成了最优的思维模式(引用自 MetaGPT 作者吴承霖)。按照评估数据,o1-preview 的幻觉频率低于 GPT-4o,o1-mini 的幻觉频率低于 GPT-4o-mini。但也有一些反馈指出 o1-preview 和 o1-mini 似乎比 GPT-4o 和 GPT-4o-mini 更容易产生幻觉。全面理解幻觉现象仍需更多研究,特别是在评估未覆盖的领域(如化学)。According to these evaluations, o1-preview hallucinates less frequently than GPT-4o, and o1-mini hallucinates less frequently than GPT-4o-mini. However, we ha ve received anecdotal feedback that o1-preview and o1-mini tend to hallucinate more than GPT-4o and GPT-4o-mini. More work is needed to understand hallucinations holistically, particularly in domains not covered by our evaluations (e.g., chemistry). Additionally, red teamers ha ve noted that o1-preview is more convincing in certain domains than GPT-4o given that it generates more detailed answers. This potentially increases the risk of people trusting and relying more on hallucinated generation.
o1 作为 Agent 的底层大语言模型,效果略逊于之前的模型。经过一定调整后,能力可以与当前 Claude-3.5-Sonnet 持平,达到业界最高水准。
除了能力本身,技术爱好者们也对 OpenAI 的技术路线做了一些探索和思考,简单分享如下:
1️⃣ OpenAI 大道至简。行业通用路径是通过 Agentic Workflow,在基座模型基础上用显式的符号逻辑完成 CoT。但 OpenAI 这次将所有能力隐式地训练到模型中,最大程度利用自回归模型的特点实现了端到端的 CoT。从某种意义上说,OpenAI 通过模型层的巨大提升,将许多依赖复杂工程框架的工作简化到只需一个 API。
2️⃣ OpenAI 在背后做了大量工作。虽然最终没有对外交付工程框架,但 OpenAI 内部一定有非常完整的数据管线,能够大规模生成高质量、低错误率的 CoT 数据。最终效果是:用一个复杂的工程框架训练出一个不依赖工程框架即可表现出色的模型。可以预见,o1 之后,构建数据管线将成为每个模型和应用公司的标配工作。
3️⃣ 通用的领域能力提升方法即将出现。自 AlphaGo 以来,用机器超越人类的速度就在大幅加快。但无论是下围棋还是打游戏,强化学习此前一直被认为难以扩展。OpenAI 没有披露 o1 的训练细节,但相信很快我们就能总结出泛化性强的模型能力提升路径。可以预见,只要给出明确的任务主题(无论是写代码、角色扮演还是做设计),都能快速完成 SOTA 迭代。
4️⃣ o1 很强,但目前与大部分人关系不大。人们总是高估眼前的新进展。客观来说,o1 的科研价值(展现和证明可能性)远大于当下的实用价值。我们或许会更受益于借助 OpenAI o1 开发的新软件、研发的新药物、设计的新机械结构,而非 o1 本身。也许当我们回顾人类的科技进化史时,会发现 o1 是一次巨大的转折点——因为它提供了一种更有效的构建优秀模型、让特定领域智能无限扩展的最优范式。
最后,有细心的网友发现 Contributor 名单中有位名为 Jie Tang 的大佬,以为是清华智谱的唐杰老师。技术爱好者们 Think step by step 并调用 Web Search 求证后,发现只是同名巧合而已。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:OpenAI o1深度解析:揭秘草莓项目真相要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看