




代码指令调优:高质量数据获取实用方法

长期以来,业界的研究重点多集中在如何生成、发现及筛选高质量的通用指令微调数据上。然而,随着代码任务逐渐成为大语言模型应用的热点,一个自然且关键的问题浮出水面:我们应该怎样针对代码任务专门构建更优质的指令微调数据? 最近一篇极具参考价值的论文对此进行了清晰拆解。其核心思路是从指令复杂度、回复质量以及指
长期以来,业界的研究重点多集中在如何生成、发现及筛选高质量的通用指令微调数据上。然而,随着代码任务逐渐成为大语言模型应用的热点,一个自然且关键的问题浮出水面:我们应该怎样针对代码任务专门构建更优质的指令微调数据?
最近一篇极具参考价值的论文对此进行了清晰拆解。其核心思路是从指令复杂度、回复质量以及指令多样性三个维度,对数据样本进行全面“体检”,从而筛选出最优质的样本。同时,该论文还揭示了一个值得关注的现象:当前部分代码指令数据在 HumanEval 基准测试中存在严重的数据泄露问题。以下信息均源自论文原文及开源项目(Paper, Github, Data-HF),我们一起来深入分析。
数据筛选:三个维度,一把标尺
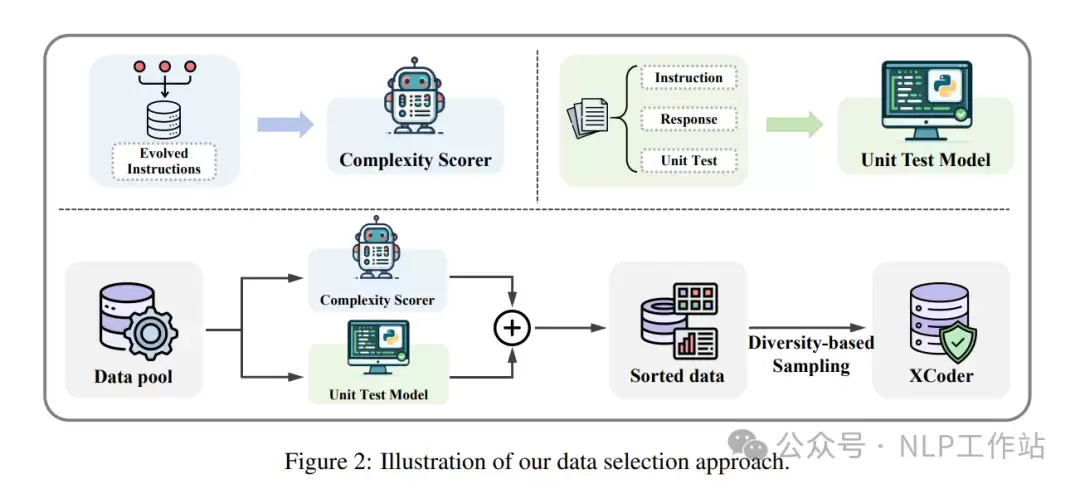
整个筛选流程相当于对一个海量数据池进行“择优录取”。具体操作上,先利用复杂度评分器和单元测试模型,为数据池中的每条数据分别打出复杂度分数和质量分数。接着,将这两个分数归一化后,通过线性组合得到综合评分。最后,依据综合评分排序,并引入多样性进行迭代采样,直至筛选出的数据集达到目标规模。完整的算法流程请参考下图。

- 复杂性评分器:如何实现?首先借助 self-instruct 方法构建一个小型种子数据集,随后借鉴 WizardCoder 的思路,对提示词进行多次深度进化,生成多轮数据。这里的轮次数量接被用作复杂性的度量指标,并用于训练最终的评分器。
- 单元测试模型:代码质量如何?运行测试是最直观的验证方式。此处,单元测试的数量被作为响应质量的衡量标准。具体做法是使用 6k 数据训练一个基于 LLaMA3-70B-Base 的模型来完成这一任务。测试时,模型为每个样本生成 12 个测试用例并执行,通过的用例数即为质量分数。
- 多样性采样:该步骤采用迭代方式执行。每次从数据池中选取一个样本,判断它能否提升当前数据集的数据多样性。若答案为是,则将其加入。多样性贡献度由样本与其在数据集中最近邻居之间的嵌入距离以及一个超参数共同决定。
效果分析:精挑细选,效果拔群
为了拼凑出最优的代码指令微调数据集,研究者收集了各类开源数据,总计 250 万条。数据池规模庞大,必须进行过滤。流程如下:先选取几个成熟的学术数据集,筛选出长度最长的 20 万条;再从中挑出复杂度评分最高的 20 万条;最后一步去重。最终,获得了 33.6 万条精炼数据。
在 LLaMA3-8B-Base 上进行的实验极具说服力。仅用 40K 数据,便已在 LiveCodeBench 和 BigCodeBench 上超越基线模型的效果;当数据量增加至 80K 时,各项指标持续攀升。

基于 LLaMA3-70B-Base 训练的 XCoder-70B 模型,一举成为当时效果最优的开源代码大模型。

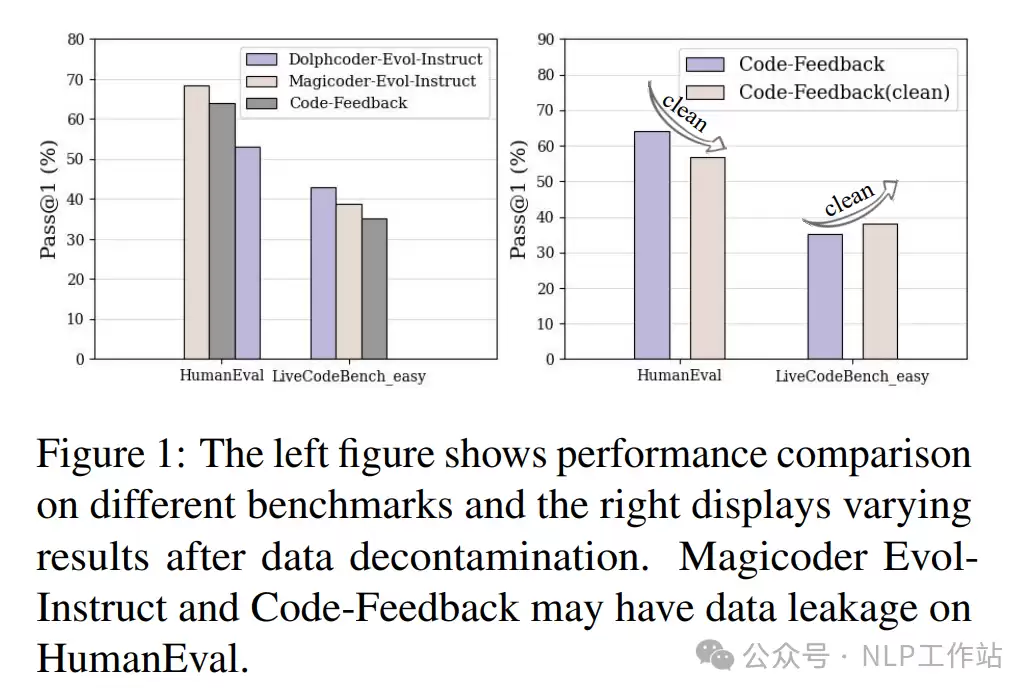
然而,有趣的是,它在 HumanEval 上并非最优。原因并不复杂:Magicoder-Evol-Instruct 和 Codefuse-Evol-Instruct 这两个数据集在 HumanEval 上存在数据泄露问题。
为解决这一问题,研究者还提出了一个名为 TLI(测试泄露指标)的新指标,用于量化训练集对测试集的泄露程度。其原理是对数据集生成 n-gram 片段,计算测试集样本的 n-gram 与训练集的重合比例,重合度越高,泄露风险越大。
后续的消融实验也证实,复杂性、响应质量和多样性这三个维度对最终数据质量的提升均起到了积极作用。一个更直观的结论是:在复杂性评估环节,复杂性评分器的效果远优于指令长度、困惑度,甚至超过了随机筛选。而在单元测试模型方面,他们自行训练的 Llama3-70B 模型表现甚至超越了 GPT-4。
最令人印象深刻的是,使用 XCoder 方法精选出的 10K 数据,其训练效果即可媲美随机选择的 160K 数据,效率提升了整整 16 倍。同时,文章还分析了 XCoder 的数据组成,重新评估了不同数据源的优缺点,这对后续的数据构建工作具有重要的参考价值。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:代码指令调优:高质量数据获取实用方法要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点LongRAG通过将检索单元从100词扩展至4K词,语料库规模从2200万降至60万,减轻检索器负担。长检索器与长阅读器协同工作,零训练下性能媲美全训练RAG模型,有效提升检索质量与全文问答能力。
系统评估检索增强生成(RAG)工作流各模块,包括查询分类、片段划分、嵌入模型、向量数据库、检索与重排序方法等,通过大量实验确定最佳实践,并提出性能最大化和平衡效率两种实施策略。研究还展示了多模态检索在视觉问答与生成中的显著效果。
北航沙磊教授团队提出ATM多智能体对抗系统,通过生成器与攻击者博弈提升检索增强生成(RAG)鲁棒性。自然问题分数提高31%,性能领先5%。该系统可增强模型安全性,降低虚假信息干扰,适用于各领域RAG系统。
ChatbotArena作为众包式大模型评估平台,因依赖主观偏好、数据不更新、用户群体偏技术化而面临偏见与透明性困境,评估标准模糊且难以反映真实需求,需更开放数据与多元用户才能改善。
- 日榜
- 周榜
- 月榜
热点快看