




ESMC、ESMFold2与ESM Atlas:蛋白质AI新挑战


在AlphaFold问世之后,蛋白质人工智能的叙事一度非常清晰:给定一条氨基酸序列,就能预测它折叠成的三维结构。这一难题已被大幅推进,AlphaFold Protein Structure Database 公开了超过2亿个蛋白质结构预测,成为众多研究流程的默认起点。
然而,一旦进入真实研发场景,事情很快就变得复杂。
在药物发现中,研究者往往更关心另一组问题:某个未知蛋白质可能具有什么功能;疾病靶点附近是否存在可用的结合口袋;能否设计出一个蛋白质或抗体片段,既能紧密结合、足够特异和稳定,又能在细胞实验中表现出预期功能。结构预测给出了关键坐标,但它并未自动回答这些问题。
Biohub此次发布的ESMC、ESMFold2和ESM Atlas,看点正在于此。它不是简单地把折叠模型做得更快,或把数据库堆得更大,而是试图将蛋白质序列模型、结构预测、结合物设计以及大规模可搜索图谱整合成一个连续系统。Biohub将其称为protein biology的world model:一个基于进化序列训练、用于表示、预测、设计和发现蛋白质的开放式科学引擎。
它到底在做什么
这套系统包含三个核心部件。
第一个是ESMC。它是一个蛋白质语言模型,输入为氨基酸序列,训练目标接近自然语言模型中的完形填空:遮住序列中的部分氨基酸,让模型根据上下文预测它们。不同之处在于,这里的上下文并非人类撰写的句子,而是进化过程中留下的蛋白质序列记录。Biohub公告称,ESMC训练了大约28亿条跨生命树的序列,专门学习蛋白质折叠、相互作用和功能背后的统计规律。
第二个是ESMFold2。它将ESMC学到的序列表征转化为原子分辨率的三维结构预测。支持从单条序列直接预测,也可以在困难靶点上加入多序列比对(MSA)来提高准确率。模型卡还说明,相比早期的ESMFold,ESMFold2能处理蛋白质、DNA、RNA、小分子和修饰氨基酸混合在一起的复合体系。
第三个是ESM Atlas。它将ESMC的内部表征扩展到68亿个蛋白质序列和11亿个预测结构上,研究者可以在大规模图谱中检索结构和功能邻域。Atlas还引入了稀疏自编码器(SAE),把ESMC的内部表征拆分为约1.6万个可解释特征,再通过自动化流程将这些特征关联到已知蛋白质数据库中的功能线索。
三个部件各司其职:ESMC负责读懂序列,ESMFold2负责将读懂的信息落实到结构和相互作用上,ESM Atlas则负责把表征转化为可搜索、可解释的蛋白质空间。
问题为什么会出在这里
蛋白质研究的困难,不仅仅在于实验速度慢。
一个蛋白质序列可能有结构、有功能、有相互作用对象,也可能只是在宏基因组测序中被发现过一次。许多蛋白质有序列但没有实验结构;有结构但没有清晰功能;有功能注释但缺乏细粒度机制。而测序规模仍在不断膨胀,未注释蛋白质空间的增长远快于实验表征的速度。
这正是蛋白质语言模型被反复尝试的原因。进化并非随机保留序列。能在自然界中保留下来的蛋白质,通常都满足一定的稳定性、折叠约束和功能约束。ESMC的逻辑是:如果模型能在数十亿条序列上学会预测被遮住的氨基酸,那么其内部很可能已经形成了对结构和功能约束的压缩表示。Biohub在ESMC介绍中强调,结构和功能信息可以在无监督序列训练中从内部表征里浮现出来,而模型训练时并不需要看到结构或功能标签。
这条路并非首次出现。ESM3已经展示了更强的生成能力:它同时处理蛋白质的序列、结构和功能,并成功生成了一个与已知荧光蛋白只有58%序列相似性的绿色荧光蛋白esmGFP,作者估计这个距离相当于超过5亿年的自然进化。这说明蛋白质语言模型不仅能给已有蛋白质打分,还能在远离已知序列的位置生成有功能的蛋白质。
此次ESMC、ESMFold2和ESM Atlas的组合,是将问题从单点生成推进到系统化使用:先把蛋白质空间表示出来,再预测结构与相互作用,最后让研究者能在大规模图谱中寻找功能线索。
方法是怎么组织起来的
ESMC的核心工作是表示学习。它将一条蛋白质序列转化为高维表征,这个表征并非简单的序列相似性,而是模型在预测氨基酸过程中压缩出来的结构和功能信号。Biohub早期ESMC说明中给出了三个模型规模:3亿、6亿和60亿参数,并且报告说结构信息会随着训练计算量和模型规模提升而持续增长。
要判断ESMC是否只是参数更大,就需要看它是否在结构相关任务上形成了更强的内部表征。
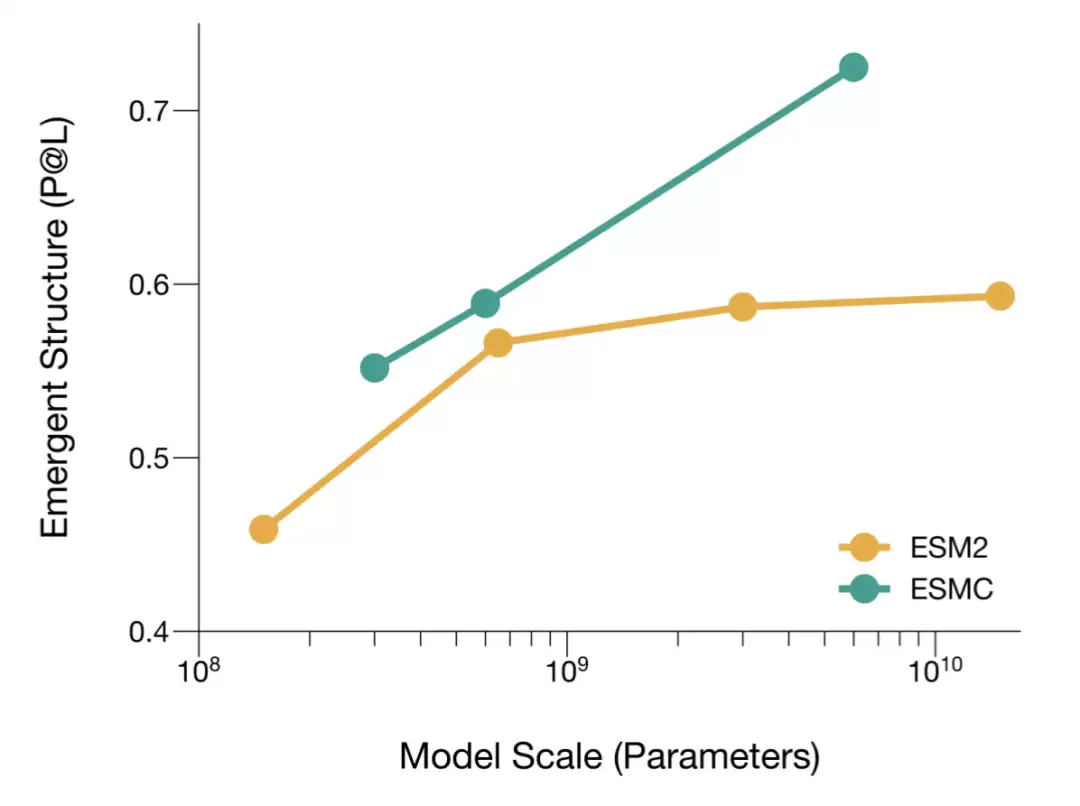 上图对比了ESMC与ESM2随模型参数规模变化时,内部表征中可读出的长程结构信息。P@L越高,表明模型表征中包含的残基接触关系越强。
上图对比了ESMC与ESM2随模型参数规模变化时,内部表征中可读出的长程结构信息。P@L越高,表明模型表征中包含的残基接触关系越强。
上图对比了ESMC与ESM2随模型参数规模变化时,内部表征中可读出的长程结构信息。P@L越高,表明模型表征中包含的残基接触关系越强。
ESMC的结构信息随规模扩大持续提升,而ESM2在更大规模下的增益则趋于平缓。关键在于,模型并没有直接输出结构,但序列模型内部已经编码了可以被简单读出的残基接触关系。Biohub的评估方法是用逻辑回归从表征中读出接触图,然后在CASP15或时间留出的PDB结构集合上计算P@L。
ESMFold2正是接上这一层表征。它使用ESMC 6B的语言模型嵌入,再结合结构预测架构,将序列或复合物输入转化为三维坐标。模型文档称,ESMFold2可以直接从氨基酸序列预测高分辨率、全原子三维结构,也可以在困难任务中加入MSA;它还有一个Fast版本,专门面向单序列快速推理。
ESM Atlas则将模型能力从单条序列扩展为一个可浏览的空间。Atlas不只是存储结构,它按照ESMC学到的关系来组织蛋白质,让研究者能够看到传统序列相似性或结构相似性检索不易暴露的功能邻域。Biohub公告特别提到,Atlas能够将一些基因编辑酶在生命树远端分支上的演化联系暴露出来,其中许多生物学内容此前从未被注释过。
旧方案为什么会卡在专业场景里
AlphaFold类模型已经改变了结构生物学的工作基线,但结构预测并不等同于蛋白质设计。AlphaFold2的经典架构依赖原始序列、同源序列形成的MSA以及可用模板;这对已知同源关系丰富的蛋白质非常有效,但当任务转向新设计蛋白质、蛋白质-蛋白质界面、抗体-抗原结合姿态以及高通量虚拟筛选时,瓶颈就会转移到速度、搜索空间和实验可验证性上。
另一方面,传统数据库检索常常依赖序列同源性、结构相似性或已有注释。面对未注释蛋白质、远缘同源关系和功能趋同关系,这些检索方式很容易漏掉信号。ESM Atlas的设计正是将模型内部表征作为新的组织轴,让蛋白质之间的关系不再仅由显式序列或已知结构决定。
这并不意味着旧方案不再有效。更准确地说,旧方案解决了结构预测中一大块确定性问题,而专业场景还需要处理选择、设计、排序、解释和验证。ESM此次发布的系统,正是将这些环节尽可能都纳入同一条计算管线。
新设计解决了什么
第一个变化是速度与规模。ESMFold2的单序列模式减少了对MSA构建的依赖,README中指出可以带来一个数量级的折叠加速;这种速度优势在处理68亿蛋白质序列和11亿结构预测时显得尤为关键。
第二个变化是面向相互作用。许多药物设计任务并非预测一个蛋白质自身如何折叠,而是预测两个分子能否以正确的姿态结合。Biohub报告称,ESMFold2在蛋白质-蛋白质复合物和抗体-抗原复合物预测基准上表现达到甚至超过了AlphaFold3等模型;当使用与AlphaFold相同的MSA信息时,ESMFold2在两个基准上是最强的预测器。当然,这一结论需限定在它报告的基准和评价设置内,不能直接外推到所有药物研发任务。
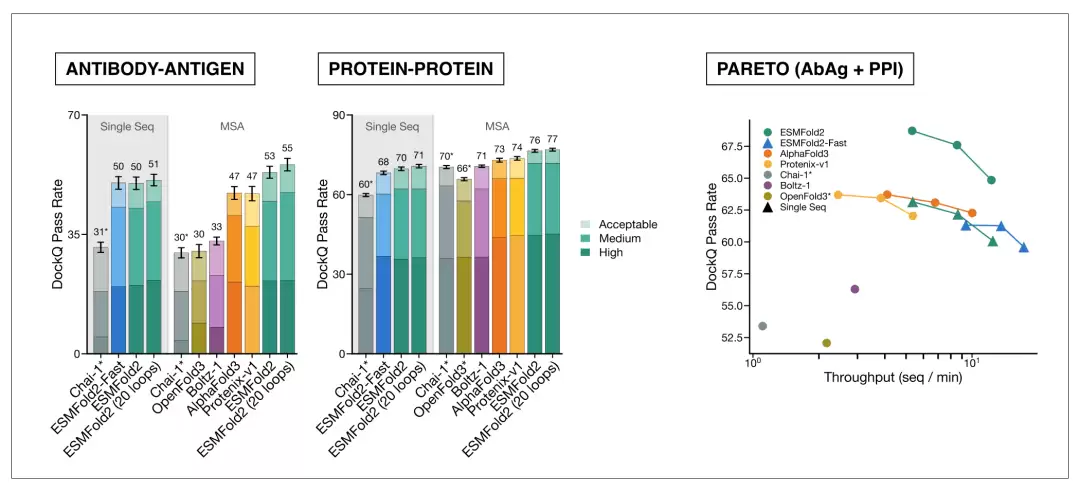 上图比较了ESMFold2与AlphaFold3、Boltz-1、Protenix-v1等模型在抗体-抗原和蛋白质-蛋白质复合物预测中的DockQ通过率,并展示了准确率与推理吞吐量之间的关系。
上图比较了ESMFold2与AlphaFold3、Boltz-1、Protenix-v1等模型在抗体-抗原和蛋白质-蛋白质复合物预测中的DockQ通过率,并展示了准确率与推理吞吐量之间的关系。
上图比较了ESMFold2与AlphaFold3、Boltz-1、Protenix-v1等模型在抗体-抗原和蛋白质-蛋白质复合物预测中的DockQ通过率,并展示了准确率与推理吞吐量之间的关系。
抗体-抗原复合物比一般蛋白质-蛋白质复合物更难预测,模型间的差距也更明显;同时,ESMFold2在增加推理预算时准确率还能继续提升,说明它的优势不仅来自一次前向预测,还来自对结构解空间的搜索和自置信度排序。
第三个变化是从预测走向设计。Biohub团队利用ESMFold2设计了针对EGFR、PDGFRβ、PD-L1、CTLA-4和CD45这五个癌症与免疫相关靶点的蛋白质结合物。官方报告给出的实验结果是:紧凑型minibinder的命中率在36%–88%,抗体来源的scFv格式命中率在15%–29%,并且都在实验中确认了结合。其中PD-L1的设计结合物在实验中恢复了T细胞信号,阻断了获批免疫检查点疗法所针对的同一通路。
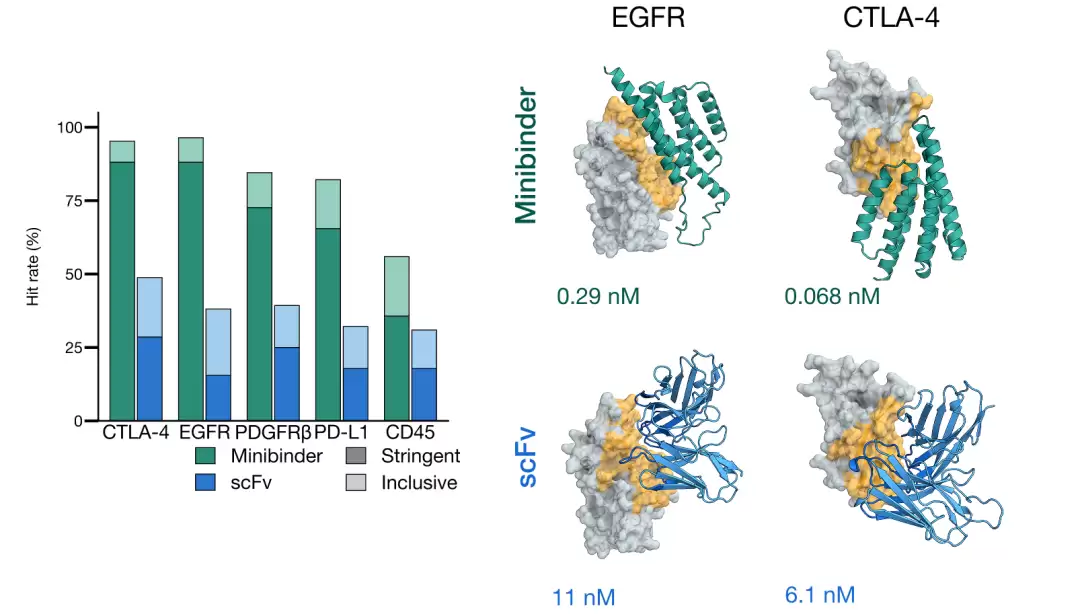 上图展示了ESMFold2设计的minibinder与scFv在多个癌症和免疫相关靶点上的实验命中率,并给出了部分代表性结合结构与亲和力结果。
上图展示了ESMFold2设计的minibinder与scFv在多个癌症和免疫相关靶点上的实验命中率,并给出了部分代表性结合结构与亲和力结果。
上图展示了ESMFold2设计的minibinder与scFv在多个癌症和免疫相关靶点上的实验命中率,并给出了部分代表性结合结构与亲和力结果。
计算设计已经能够将实验筛选的起点大幅前移。模型先在表征空间和结构空间中生成候选,再将更可能成功的设计送入实验验证。命中率的提升得益于计算预筛选,但最终结论仍需湿实验拍板。
结果到底说明了什么
ESMC的结果表明,蛋白质语言模型的规模化仍然能带来结构表征增益。任务是从模型内部表征中读出残基接触关系,数据来自CASP15或时间留出的PDB结构集合,比较对象是上一代ESM2。结果显示,ESMC在相近甚至更小的参数量上取得了更强的结构信号,60亿参数版本直接拉大了差距。机制上可以理解为:更多的训练数据、更有效的训练方法和更强的模型容量,使得序列预测任务中隐藏的远程约束更充分地进入了内部表征。
ESMFold2的结果表明,结构预测竞争的焦点正在从单体折叠转向复合物界面和推理时搜索。抗体-抗原结合姿态是更接近药物发现的问题,因为界面预测一旦出错,候选设计就直接作废。Biohub报告显示,ESMFold2在这类任务上相对于AlphaFold3、Boltz-1、Protenix-v1等模型有明显优势,尤其在允许更多推理预算时表现还能继续上升。边界也很明确:这毕竟是结构与姿态预测基准,不等同于体内有效性、免疫原性、成药性或临床成功。
Binder设计实验则说明,这套系统已经跨越了纯计算预测的门槛,进入了实验闭环。五个靶点覆盖癌症和免疫研究中的典型对象,比较对象不再是其他模型,而是实际的结合、特异性、稳定性和功能读出。36%–88%和15%–29%的命中率范围说明不同设计格式和靶点难度差异很大;PD-L1的T细胞信号恢复实验则表明,至少在这个局部任务上,模型设计的结合物不仅能够粘上靶点,还能干预相关的生物通路。
Atlas的结果更像基础设施。它将68亿蛋白质和11亿结构放入一个可检索图谱,再通过SAE特征提供解释入口。下面这张表适合放在文章中间,帮助读者将规模感具体化。
数据类型 | 规模 |
|---|---|
蛋白序列 | 68亿个蛋白 |
预测结构 | 10亿级结构;平台页列为1B,公告列为11亿 |
SAE特征 | 覆盖68亿蛋白的蛋白级和残基级特征向量 |
SAE聚类 | 750万个聚类 |
全量数据 | 377 TB |
Atlas将蛋白质人工智能从模型推理扩展为数据资源。研究者可以从一个疾病相关蛋白质、一个未知结构域或一个功能关键词出发,在模型组织出的邻域中寻找候选关系。它给出的仍然是计算假设,但假设生成的覆盖面和速度发生了质的变化。
END
这项工作的长期意义,不在于宣告蛋白质设计已被攻克,而是重新组织了一遍问题。
过去,许多流程是先找同源序列、查数据库、跑结构预测、人工筛选候选、再进入实验。ESM的新系统试图用模型表征贯穿所有这些环节:序列被嵌入同一个空间,结构由同一套表示驱动,未知蛋白质可以在Atlas中被检索,设计候选可以通过ESMFold2排序后进入实验。
这会让早期探索更像虚拟实验。研究者可以先在计算空间中提出更多假设,再把有限的实验资源集中到更有希望的候选上。Benchling对Biohub团队的访谈中也提到,ESMFold2的速度使得大规模虚拟筛选、de novo binder生成和交互组层面的结构探索变得实际可行。
但边界也需要同时写清楚。
ESMFold2模型卡明确指出,模型输出应被视为需要实验验证的假设,不能替代X射线晶体学、冷冻电镜或核磁共振等实验结构测定;它也不面向未经进一步验证的临床或治疗用途。模型还可能受到PDB、AlphaFold DB等训练数据偏倚的影响,对欠代表蛋白质类型、动态构象、多构象和无序区域的表现会下降。
开放也带来了责任问题。Biohub README称,团队在发布前对ESMC、ESMFold2、SAE、ESM Atlas和binder设计系统进行了生物安全与生物安保风险评估,并在平台上设置了针对受控病原体和毒素关键词及序列的限制;代码、权重、Atlas数据和binder设计系统则在风险评估后开放发布。
因此,更稳妥的判断是:ESM此次发布将蛋白质人工智能的任务从预测一条序列的结构,推进到组织蛋白质空间、预测相互作用、生成实验候选和解释未知功能。它不会直接替代实验,也不会绕过药物开发中的安全性、有效性和可制造性验证。但它确实让许多过去分散的步骤,第一次有机会在同一套开放模型和数据底座上连续运行。
这可能是结构预测之后,蛋白质人工智能走出更现实的一步。
参考文献
[1] Biohub. Biohub releases a world model of protein biology. 2026. https://biohub.org/news/world-model-of-protein-biology/
[2] Biohub GitHub. A world model of protein biology: ESMC, ESMFold2, & ESM Atlas. 2026. https://github.com/Biohub/esm
```
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

如何高效将多个表格数据合并汇总到一张表中
高效合并多个表格:Excel数据汇总的四大实用技巧 在日常办公中,我们常常需要面对这样的任务:几个分散在不同工作表中的表格,各自记录了不同的数据维度,但最终需要将它们整合到一起进行分析或制作报告。听起来有些繁琐,但Excel其实已经内置了多种成熟的解决方案。接下来,我将逐一拆解这四种方法,帮你找到最

免费AI智能写作生成器让你轻松解决创作难题
内容创作的模式,正被AI技术悄然重塑。如今,只需输入几个核心关键词,一篇结构完整的文章就能自动产出——这对内容创作者、市场营销人员和自媒体人而言,无疑是一大福音。写作过程往往耗时费力,而免费AI智能写作生成器的出现,恰好精准解决了这一难题。借助这些工具,创作者能够在更短的时间内产出更多优质内容,从而

A表格中快速提取B表格数据的高效方法
如何快速从A表格中提取B表格的数据提升工作效率的有效策略 在职场日常工作中,数据处理与分析几乎是每位从业者都要面对的必修课。尤其是当你需要从一个数据源(我们称之为A表格)中提取特定信息,用以填充另一个目标表格(即B表格)时,选对方法往往能让效率相差数倍。以下介绍的几种方法均经过实际工作验证,你可以根

如何高效选取Excel表格部分数据提升工作效率技巧
Excel表格部分数据选取全攻略:筛选、条件格式、公式与透视表 日常处理数据时,最令人困扰的往往不是数据本身,而是如何从一张包含成百上千行的大表中,迅速定位并提取出所需部分。无论是筛选特定记录,还是获取关键信息,若方法不当,仅靠鼠标拖拽就可能耗费大量时间。以下介绍的几种Excel数据选取技巧,均经过

中秋节放假通知模板 正式温暖关怀版
适合需求: 2023年中秋节放假通知模板 尊敬的公司全体员工: 中秋佳节即将来临,首先感谢大家近期在工作中的辛勤付出与坚守。每年中秋月圆之际,大家都期盼与家人团聚,共享温馨时刻。公司也衷心希望每一位员工都能在这个充满温情的传统节日里,与亲人欢聚一堂,共度美好时光。 依据公司统一安排,现将2023年中








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
