




清华姚权铭团队提出LMNet实现语言模型自主组网

大语言模型如今已成为AI系统的核心组件,无论是撰写文章、解答数学问题,还是编写代码,单个模型确实表现出色。然而,随着任务日益复杂,需要更精细的分工协作,一个根本性问题逐渐凸显:未来的智能系统,是否必须将单个模型越做越大?抑或,能否像人类社会的组织方式、神经系统的信号传递、或者计算机网络的协作模式那样
大语言模型如今已成为AI系统的核心组件,无论是撰写文章、解答数学问题,还是编写代码,单个模型确实表现出色。然而,随着任务日益复杂,需要更精细的分工协作,一个根本性问题逐渐凸显:未来的智能系统,是否必须将单个模型越做越大?抑或,能否像人类社会的组织方式、神经系统的信号传递、或者计算机网络的协作模式那样,通过将多个智能单元连接起来,让它们彼此沟通与协同,从而催生出更强大的整体能力?
围绕这一方向,清华大学姚权铭团队提出了一种全新的AI系统组织架构——Language Model Networks。相关论文已被ICML 2026接收,作者为Shiguang Wu、Yaqing Wang和Quanming Yao。他们设计了一套名为LMNet的框架,使语言模型之间能够通过稠密、可微、可训练的方式相互通信,这相当于从“单模型智能”迈向“模型网络智能”的一次系统性探索。

论文标题:Language Model Networks: Supervision-Efficient Learning through Dense Communication
论文链接:https://arxiv.org/abs/2505.12741
一、从“更大的模型”到“更会协作的系统”
过去几年,大模型研究的主旋律几乎始终围绕“规模”展开:参数更多、数据更大、上下文更长、训练策略更强。规模扩张的确带来了能力跃迁,也推动了大模型在实际场景中的加速落地。
但事情总有另一面。当模型开始承担那些需要持续推理、多种能力穿插、不断切换工具并验证结果的任务时,单体模型的边界感越来越明显:规划、推理、检索、验证、调用工具、生成结果……所有压力都集中在单一模型内部,分工与专业化无从谈起。
Language Model Networks提供了一种不同的思路:预训练语言模型不一定非要做成独立的预测器,而完全可以被当作可复用的计算节点。真正值得关注的,是这些节点之间的连接、通信与协同——它们本身就是智能能力的重要来源。
换句话说,AI的能力不仅取决于单模型有多强,更取决于模型被如何组织起来。
二、为什么仅靠自然语言“聊天”还不够
目前,在大模型推理阶段的test-time scaling、多模型协作以及多智能体系统中,模型之间通常通过自然语言对话。一个模型生成一段文字,另一个模型读进去再继续推理。这种方式直观、便于人类理解,用来快速搭建原型颇为顺手。
但从机器通信的角度看,自然语言并非最高效的媒介。语言是离散的、符号化的,模型之间每交流一次,都要经历“内部表示→文本→内部表示”的转换过程。这一来回,信息难免损失,更重要的是梯度传播被打断——整个系统难以直接根据最终任务目标进行端到端优化。
模型协作中真正关键的,不光是“提示词怎么写”,而是“通信这件事本身能不能被学习”。
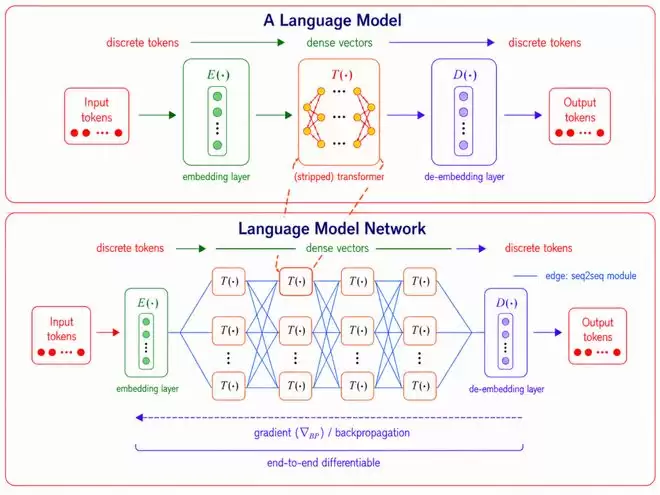
图 1 :离散的自然语言对于模型间通信是非必需的,且传递信息效率低、难以优化;LMNet 利用稠密连续向量进行模型间通信。
三、LMNet:在语言模型之上构建“模型级神经网络”
LMNet的设计可以这样理解:在语言模型的上层,再搭建一个“模型级的神经网络”。
普通神经网络中,神经元通过连接形成层级;而在LMNet中,预训练语言模型被当作可复用的计算节点,模型之间的通信模块则构成可训练的连接边。具体实现上,系统最外层的输入和输出仍然是自然语言,但中间节点之间尽量绕开反复的文本生成与理解,直接交换连续的稠密向量。这样一来,模型之间的沟通就不再完全依赖人工设计的提示词、角色分工或者中间推理文本,而是在训练过程中自动学习出来。
图 2 :LMNet 模型网络结构示意图。语言模型作为节点,通信模块(如 attention block)作为边,形成可端到端优化的模型网络。
四、让通信从人工设计变为自己学习
这项工作的关键意义在于,它把“通信”从外部设计的规则,提升为系统内部可以被优化的能力。系统不需要有人去标注每个中间节点该说什么,也不需要提前规定每个模型必须扮演什么角色。只要最终任务有监督信号,LMNet就能通过梯度优化自动调整模型节点之间的信息流,学会“谁该向谁传递什么信息”。
从这个角度看,LMNet更像是一次关于“智能组织方式”的探索。它把大语言模型从单个预测器,推进为可连接、可组合、可协同的网络化组件;也让AI系统设计的焦点从“怎么提示一个模型”延伸到“怎么组织一组模型”。
这个思路与测试时推理、多智能体协作、工作流优化等方向有天然联系,但LMNet更激进了一步:它直接针对底层通信机制本身,让通信变成可微、可训练、可优化的系统能力。
五、实验数字:小额外成本下的能力提升
实验结果表明,LMNet在通用能力提升和有限监督适应两个场景中都表现不错。
在通用能力提升实验中,研究团队以Qwen2.5-0.5B作为基础语言模型节点,构建了1/4/4/4/1结构(共4层通信,14个节点共享参数),参数总量约1.14B。额外训练token少于0.1T,训练成本不到基础模型预训练成本的0.2%——仅凭这点额外开销,LMNet在多个通用任务上取得了明显的性能提升(图3)。
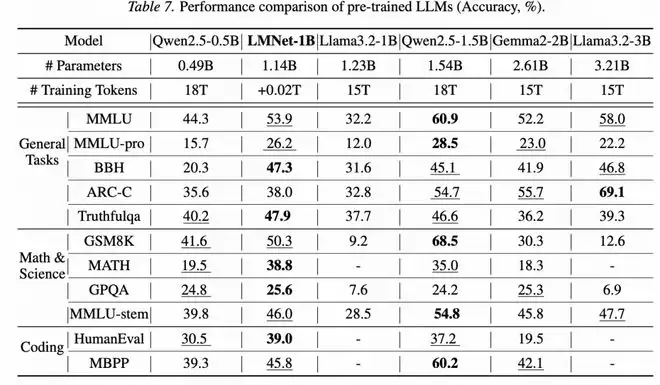
图 3:相近参数规模 LLM 的性能比较
另外,如果拿单个模型做test-time scaling来比较,在相近的推理时间开销下,LMNet依然具备明显优势(图4)。
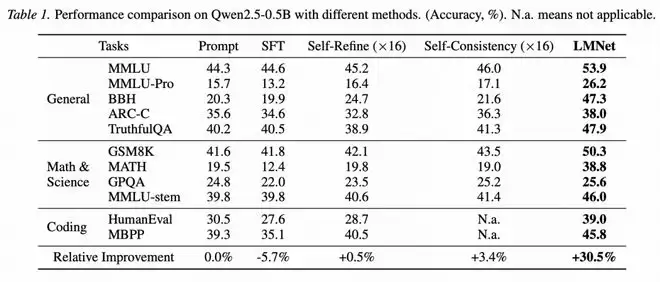
图 4:Qwen2.5-0.5B 不同的 test-time scaling 方法的性能比较
在有限监督适应场景中,研究团队构造了更小型的LMNet,并冻结节点大模型的参数,只训练边模型的参数,以避免微调大量参数导致的过拟合。与其他SFT(包括PEFT方法)相比,LMNet依然展现了明显的性能优势(图5、图6)。
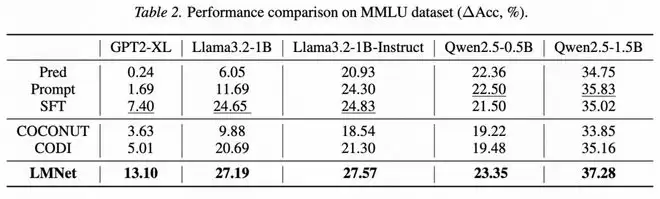
图 5:以不同的 LLM 为底座/节点,在 MMLU 上微调并测试的性能比较
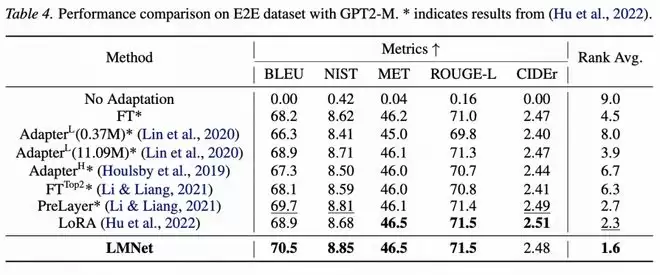
图 6:在 E2E 数据集上用不同的 PEFT 方法微调 GPT2-M 并测试的性能比较
这些数字当然不是全文最重要的部分,但它们传递了一个清晰的信号:模型之间的可学习通信,确实可能成为提升系统能力的一条有效路径。LMNet的价值不只在于某个benchmark的提升,更在于它证明了那个方向——通信方式本身可以被学习,模型网络可以从最终任务的监督中自动形成更高效的信息流。
六、从单体智能走向网络智能
这项工作指向了一个可能的未来:下一代AI系统未必是一个不断膨胀的单个模型,而可能是一个由多个模型、工具、记忆和反馈模块共同构成的可学习网络。
在这样的系统里,智能不只来自单个模块的能力,也来自模块之间如何连接、如何交流、如何共同适应任务。
“沟通即智能”不是一句简单的口号,而是对未来AI系统形态的一种判断。当语言模型开始学会自己“组网”,人工智能的竞争将从单体模型的能力比拼,转向系统组织能力、通信效率和协同学习能力的全面较量。
值得注意的是,这个方向已经受到国际前沿研究的持续关注。比如近期的Google DeepMind和AWS Agentic AI都在从不同角度探索类似思路——模型间的通信媒介、通信拓扑和可学习接口,正在成为构建下一代AI系统的关键技术支点。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:清华姚权铭团队提出LMNet实现语言模型自主组网要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点通过角色、约束与结构模板强制分叉AI生成路径,可产出轻量社交、深度访谈、教学实践三种风格播客提纲,且需严格遵循版本参数、限制条件和输出格式,从而确保提纲风格多样且符合规范要求。
1、美国封堵英伟达、AMD向海外中企出口人工智能芯片的漏洞 美国商务部近日出手,封堵了近一年来让中国AI企业通过海外子公司轻松获取先进芯片的漏洞。新指引明确:任何总部位于中国的实体,无论其芯片收货地设在马来西亚还是其他地方,想要采购英伟达、AMD等公司的高端AI芯片,都必须先通过许可证审批。 这个漏
微信发布PC端AI工具小微助手,通过对话方式实现本地文件、系统功能及Chrome书签的智能搜索,支持自然语言输入。内置翻译、剪贴板管理、JSON解析等实用工具,提供自定义快捷面板。圈子功能支持共享空间,可接入微信对话开放平台、混元及ChatGPT等外部大模型,支持定制开发。
通义智文是阿里云推出的免费阅读助手,基于通义大模型实现自动摘要、智能笔记、语义搜索与多格式支持。它针对网页、论文、图书等场景配置不同引擎,可生成全文概要与逐章导读,支持提问溯源,帮助用户高效获取信息。
- 日榜
- 周榜
- 月榜
热点快看