




商汤科技开源SenseNova信息图专项模型

一、SenseNova-U1-8B-MoT-Infographic:国产开源信息图生成模型详解 信息图生成长期以来被视为AI图像生成领域的难点。文字渲染模糊、版式杂乱无章、中文支持不佳——这些问题如今终于迎来了解决方案。 商汤科技日日新团队近期开源了一款专注信息图生成的多模态大模型,型号为Sense
一、SenseNova-U1-8B-MoT-Infographic:国产开源信息图生成模型详解
信息图生成长期以来被视为AI图像生成领域的难点。文字渲染模糊、版式杂乱无章、中文支持不佳——这些问题如今终于迎来了解决方案。
商汤科技日日新团队近期开源了一款专注信息图生成的多模态大模型,型号为SenseNova-U1-8B-MoT-Infographic。从命名即可看出,它基于SenseNova-U1-8B-MoT基础模型迭代而来,核心攻克的任务正是信息图(Infographic)生成这一高难度场景。
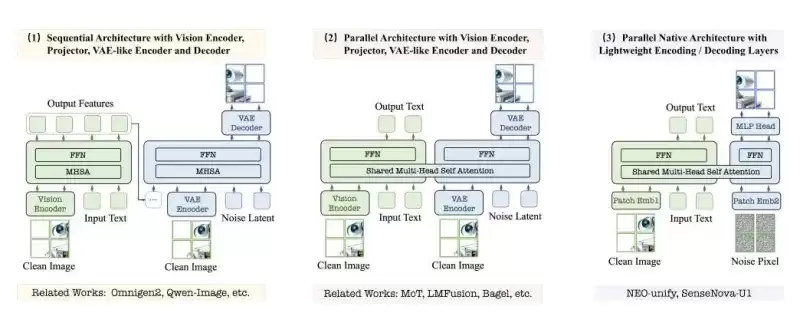
该模型的定位非常清晰:低成本、高精准、可商用的国产信息图生成方案。它采用商汤自研的NEO-unify统一架构,参数规模仅为8B,却针对高密度文字渲染、结构化版式设计、数据图表精准生成三大核心场景进行了深度优化。2026年5月29日正式开源,采用Apache 2.0协议,支持商用和本地部署——这意味着你可以直接将其用于商业产品,无需额外付费。
五、使用方法
1. 环境准备
先说结论:部署门槛不高,单张RTX 3090即可运行。
硬件要求:
- 最低配置:NVIDIA RTX 3090(16GB显存)、32GB内存
- 推荐配置:NVIDIA RTX 4090(24GB显存)、64GB内存
软件依赖:
创建虚拟环境,安装PyTorch和Transformers等基础库即可。具体命令如下:
# 配置虚拟环境 conda create -n sensenova-infographic python=3.10 conda activate sensenova-infographic # 安装依赖库 pip install torch==2.1.0 transformers==4.35.2 accelerate==0.24.1 pillow==10.1.0 pip install huggingface_hub==0.19.4
2. 模型获取
模型权重托管在Hugging Face上,需提前安装Git LFS,然后直接克隆仓库:
# 克隆模型仓库 git clone https://huggingface.co/sensenova/SenseNova-U1-8B-MoT-Infographic cd SenseNova-U1-8B-MoT-Infographic
3. 代码推理示例
核心推理代码非常简洁。创建一个infer.py文件,将以下代码粘贴进去即可:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from PIL import Image
# 加载模型与分词器
model_name = "./" # 模型本地路径
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# 输入提示词(示例:生成中国足球发展信息图)
prompt = "生成一张横版信息图,主题为中国足球发展与改革关联梳理,包含文字说明、关系图,排版清晰,文字准确"
# 生成配置
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=1024,
temperature=0.7,
top_p=0.95
)
# 输出并保存图像
image = tokenizer.decode(outputs[0], skip_special_tokens=True)
image.sa ve("football_infographic.png")
print("信息图生成完成,已保存为football_infographic.png")
4. 运行与优化
# 执行推理脚本 python infer.py # 批量生成(修改提示词列表循环即可) # 提示词优化技巧:明确尺寸、风格、文字要求,例如“1024×768、简约商务风、文字清晰无模糊”
六、竞品对比
要判断一款模型的能力,须与市面标杆产品横向对比。我们选取了GPT-Image 2(闭源商用)和Stable Diffusion 3(开源通用)作为参照,从核心维度评估差异:
| 对比维度 | SenseNova-U1-8B-MoT-Infographic | GPT-Image 2 | Stable Diffusion 3 |
|---|---|---|---|
| 模型定位 | 国产开源信息图专项模型 | 闭源通用多模态模型 | 开源通用文生图模型 |
| 参数规模 | 8B | 千亿级(未公开) | 12B |
| 文字渲染(中文) | ★★★★★(准确率99%+,小字清晰) | ★★★★(中文较好,小字偶有模糊) | ★★(中文乱码多,小字糊化严重) |
| 信息图适配性 | ★★★★★(专项优化,版式规整) | ★★★★(通用适配,需调提示词) | ★★(需插件,效果不稳定) |
| 开源与商用 | Apache 2.0,免费商用、可微调 | 闭源,按Token计费($30/百万token) | 开源,非商用免费,商用需授权 |
| 中文理解能力 | ★★★★★(深度适配中文语义) | ★★★★(支持中文,语义理解较强) | ★★★(基础支持,复杂语义有偏差) |
| 本地部署 | 支持单卡(16GB显存) | 不支持本地部署 | 支持单卡(24GB显存+插件) |
| 推理速度 | 8-12秒/张 | 3-5秒/张 | 15-20秒/张(加插件) |
核心差异可总结为:
- 对比GPT-Image 2:开源免费、支持本地部署、中文信息图适配更优,但推理速度略慢——这个权衡可以接受。
- 对比Stable Diffusion 3:无需插件、文字渲染精准、信息图生成效率高,直接解决了SD3中文乱码的硬伤。
七、常见问题解答
Q:模型生成的信息图文字仍然模糊,如何解决?
A:首先检查提示词中是否明确写有“文字清晰、小字号精准、无模糊”等要求。其次确保显存≥16GB,显存不足会直接降低生成质量。最后可将temperature参数调至0.6-0.7,降低随机性,文字稳定性会明显提升。
Q:模型能否生成自定义尺寸的信息图?
A:支持。在提示词中标注即可,例如“生成1920×1080横版信息图”。建议优先选择16:9、4:3等标准比例,非标比例可能导致版式错乱。
Q:商用是否需要付费?是否存在版权风险?
A:模型采用Apache 2.0开源协议,免费商用,无版权风险。商业产品、营销内容、企业服务均可直接使用,无需向商汤支付任何费用。
Q:能否在手机端或轻量化设备上部署?
A:当前版本专为NVIDIA显卡优化,暂不支持手机端。若需在低显存设备上运行,可尝试模型量化(INT8/INT4),显存需求可降至约10GB,但生成速度和质量会有所折损。
Q:生成的信息图能否二次编辑?
A:模型输出为PNG格式位图,无法直接修改文字。如需二次编辑,可在提示词中要求“分层设计、文字与图形分离”,或生成后使用PS等工具手动处理。
八、总结
SenseNova-U1-8B-MoT-Infographic的定位十分明确——国产开源信息图方向的标杆级模型。依托NEO-unify统一架构和MoT主干网络,它在8B这个相对较小的参数规模下,实现了三大核心突破:高密度文字的精准渲染、专业版式的自动生成、中文场景的深度适配。这些痛点正是传统AI生图模型长期难以攻克的问题——文字模糊、版式混乱、中文支持差。
更关键的是,它完全开源可商用,支持低成本本地部署,覆盖内容创作、企业办公、科研学术等常见场景。对于国内用户而言,这无疑是GPT-Image 2等海外闭源模型的优质替代方案。可以说,这款模型的推出,正将AI信息图生成从“实验室玩具”真正推向“可落地工具”。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:商汤科技开源SenseNova信息图专项模型要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点企业AI选型易陷入十大误区:盲目追求通用方案、关注技术指标而非实际价值、忽视数据质量、照搬成功案例、贪图低成本忽视长期代价、忽略团队能力、低估变革难度、过度依赖供应商、忽视隐私合规、缺乏明确ROI标准。选型应聚焦业务需求、数据基础与行业特性。
使用可灵AI生成视频时多手问题源于模型缺乏人体解剖约束。通过启用肢体数量专项负向词组合、强化上肢解剖附着点正向锚定、导入双视角参考图锁定骨骼绑定、分段生成并硬锚定关键帧肩部区域,可从词、图、帧三维度提供不可违背的解剖约束,有效扼制多手问题。
想让Canva的AI在生成电商商品图前主动追问细节,而不是直接输出一张图片?这里有一个实用技巧:关键在于激活它的“对话式提示词引导模式”。要实现这一点,你需要在输入提示词时有意识地留下结构化的空白,并确保首句包含明确的提问意图动词。下面我们来详细拆解操作步骤。 用提问句式开头,强制AI进入追问流程
基于亚马逊云AWS经验,某AI助手的回复精准复刻其市场策略,涵盖底层逻辑、话术节奏和关键切入点。通过追问可进行竞争对手、产品及技术分析,辅助摸清整个销售战场,有效提升策略制定效率。
- 日榜
- 周榜
- 月榜
热点快看