




MIT注意力匹配:内存暴降50倍精度无损,终结大模型显存危机?

你正盯着屏幕——一个自主AI智能体正在高速运转,穿梭于数十万行代码的开源项目之间,翻阅文件、API文档和调试日志,宛如一台不知疲倦的超级程序员。然而,在这片“无所不能”的表象之下,潜伏着一个随时可能引爆的硬件梦魇:随着上下文不断拉长,大模型的工作记忆正急速膨胀,像一个无底洞,无情吞噬着昂贵的GPU显
你正盯着屏幕——一个自主AI智能体正在高速运转,穿梭于数十万行代码的开源项目之间,翻阅文件、API文档和调试日志,宛如一台不知疲倦的超级程序员。然而,在这片“无所不能”的表象之下,潜伏着一个随时可能引爆的硬件梦魇:随着上下文不断拉长,大模型的工作记忆正急速膨胀,像一个无底洞,无情吞噬着昂贵的GPU显存池。

这个让所有企业级AI开发者头疼的显存杀手,正是KV Cache。
但局面正在改变。来自MIT的研究团队(Adam Zweiger、Xinghong Fu等人)提出了一套全新的解决方案——“注意力匹配”(Attention Matching),一种基于潜在空间压缩的技术。它能够将大模型的上下文内存压缩至50倍,且几乎不损失精度,整个过程仅需短短几秒。

论文标题:Fast KV Compaction via Attention Matching
论文地址:https://arxiv.org/pdf/2602.16284
代码地址:https://github.com/adamzweiger/compaction
换言之,那些原本需要一整排H100 GPU才能勉强支撑的超长对话或巨型文档分析任务,现在可能只需单张显卡就能跑满并发。AI基础设施的效率革命,已经到来。
昂贵的工作记忆:大模型的阿喀琉斯之踵
要理解这项技术有多强大,首先得正视大模型的软肋。
LLM采用自回归方式生成回答——它逐词输出,为了避免每预测一个新词就把数万字的聊天记录从头到尾重新计算一遍,模型必须将之前每个token的“数学灵魂”缓存起来。这些被提取的多维向量,就是键(Key)和值(Value)对,即KV Cache。
结果,随着上下文越来越长,工作记忆会不可逆转地膨胀。
在现代企业级应用中——分析数百页的法律合同、维持数月的私人AI伴侣记忆,或运行自治编码智能体——一个用户的请求就能让KV Cache瞬间飙升到几十GB。
正如论文第一作者Adam Zweiger所说:“在超长上下文服务中,KV Cache是最大的物理瓶颈。它锁死了并发量,迫使我们缩小批处理规模,甚至逼着系统做极其影响性能的频繁卸载。”
面对这个显存吞噬者,此前的研究者尝试过多种方法:
Token丢弃与合并(如H2O, SnapKV, PyramidKV等):这些方法试图剔除模型认为不重要的token。轻度压缩尚可,但一旦压缩率超过10倍,模型性能就会大幅下降。
文本摘要:这是工业界目前最无奈的标配。当内存见底时,系统暂停,让模型自己写一段上下文总结,然后清空记忆。问题在于,这种方法极度“有损”——它会彻底抹去极其关键的微小细节,比如医疗记录里的一个罕见指标。
潜空间压缩(如Cartridges):这是近期的前沿方向,证明了高比例压缩可行且能保持高精度,但代价太大——需要通过极其缓慢的端到端梯度下降来训练压缩后的记忆。压缩一段上下文,即使使用昂贵的GPU,也耗时数小时。这对要求“秒回”的实时企业应用而言,简直是天方夜谭。
市场需要一种既有Cartridges的精度,又有传统方法速度的方案。而MIT的“注意力匹配”,正好填补了这个空白。
打破常理的数学魔法:“注意力匹配”的底层逻辑
MIT的研究人员没有死磕缓慢的机器学习训练,而是找到了一条绝妙的数学捷径。他们退后一步,提出了一个极其本质的问题:当我们压缩记忆时,模型真正在乎的是什么?
答案很简单:模型根本不关心你存了多少个Key和Value,它只在乎当它抛出一个查询(Query,即q)时,这堆记忆能返回什么结果。
为了欺骗AI,让它觉得“压缩后的记忆和原本庞大的记忆一模一样”,压缩后的键值对(C_k, C_v)必须严格匹配原始记忆的两个核心数学属性:
注意力输出(Attention Output):即AI提取到的实际信息向量。
注意力质量(Attention Mass):这一点至关重要。在拼接新token或旧记忆时,一段记忆的话语权取决于它的“质量”。
如果直接把1000个token压缩成20个,那么这20个token的“总质量”绝对比不上原本的1000个。结果,模型在后续推理时会极度轻视这部分被压缩的记忆。为了破解这一难题,研究团队引入了一个微小但堪称神来之笔的变量:每token标量偏差β。
这个β偏差就像杠杆权重——它在注意力计算的指数层面上,对保留下来的Key进行乘法重加权,让区区一个Key爆发出代表50个被移除Key的巨大质量。
用数学语言表达(如论文中的公式1和2),优化的目标就是找到(C_k,β, C_v),使得对所有相关查询q,匹配注意力输出:
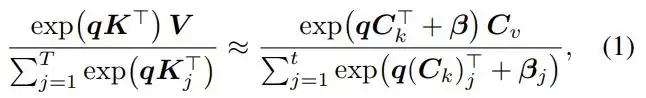
并且匹配总质量:
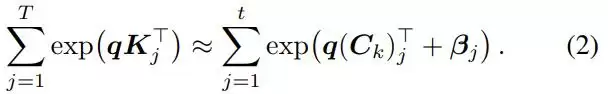
更令人惊艳的是,这个看似复杂的非线性优化问题竟然自然而然地解体了。研究人员完全摒弃了吃算力的反向传播和梯度优化。
首先,锁定C_k后,质量匹配问题退化为非负最小二乘法(NNLS)问题,瞬间就能算出偏差β。
然后,注意力输出匹配问题直接变成标准的普通最小二乘法(OLS)问题,通过简单的代数矩阵运算,眨眼间就能求出压缩后的值C_v。
这是降维打击。原本需要数小时的训练,被线性代数优化到了以秒为单位。
来自VentureBeat,由AI生成
预判你的预判:如何提取“参考查询”与挑选“金钥匙”?
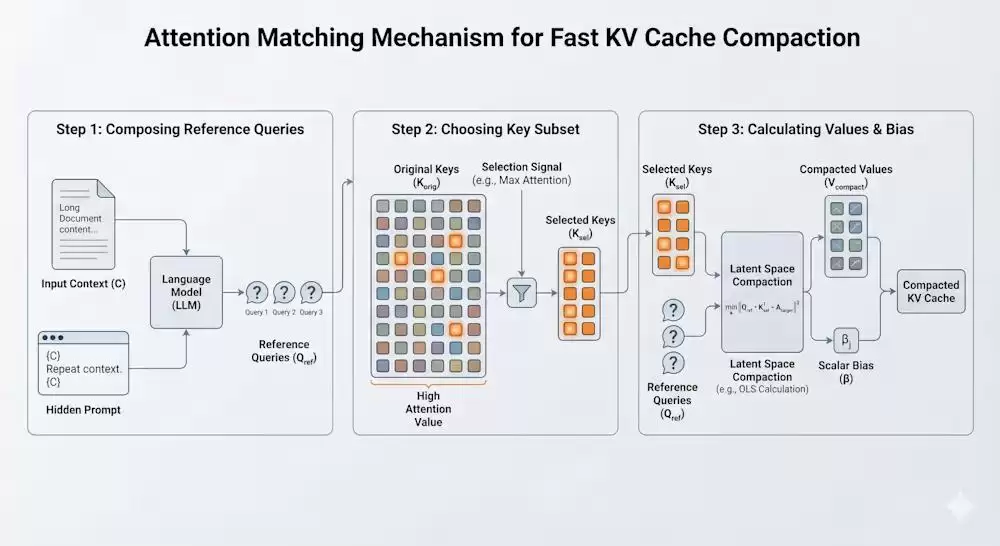
有了数学武器,接下来的工程落地同样精彩。为了让压缩算法知道该保留什么,系统需要一批“参考查询”(Q_ref),作为模型未来可能提出问题的“替身”。
研究团队设计了极其聪明的“预演”机制:
重复预填充:悄悄在文档末尾加一句隐藏指令“重复前面的上下文”,然后捕获模型在试图复述时产生的内部Query向量。
自我学习:让模型对文档做快速合成任务,比如“提取所有核心事实”或“把日期结构化为JSON”,从而嗅探出模型在深度推理时会生成什么样的Query。
手里有了这些具代表性的Query探针,系统开始从原始Key海中挑选“金钥匙”(C_k)。论文提供了两种方法:
最高注意力法(Highest Attention Keys):闪电般的启发式方法,直接挑出在参考查询中被关注度最高的Keys。速度快,性价比高。
正交匹配追踪(Orthogonal Matching Pursuit, OMP):更贪婪的算法,像搭积木一样,每一步都精挑细选一个最能填补“质量误差”残差的Key,然后用NNLS重新校准权重。虽然耗时稍长(仍在几分钟级别),但能将压实质量推向巅峰(AM-OMP)。

并非所有“注意力”生来平等:非均匀压缩策略
这还不是全部。深入探索模型架构后,他们发现了一个有趣现象:在多头注意力机制中,并非所有的“头”都是工作狂。
有些Head极度贪婪,需要庞大的KV容量才能保持性能(比如负责长程依赖的Head)。另一些Head则极其佛系,哪怕把它的记忆砍掉90%,它依然能完美运转(比如只关注局部词法结构的Head)。
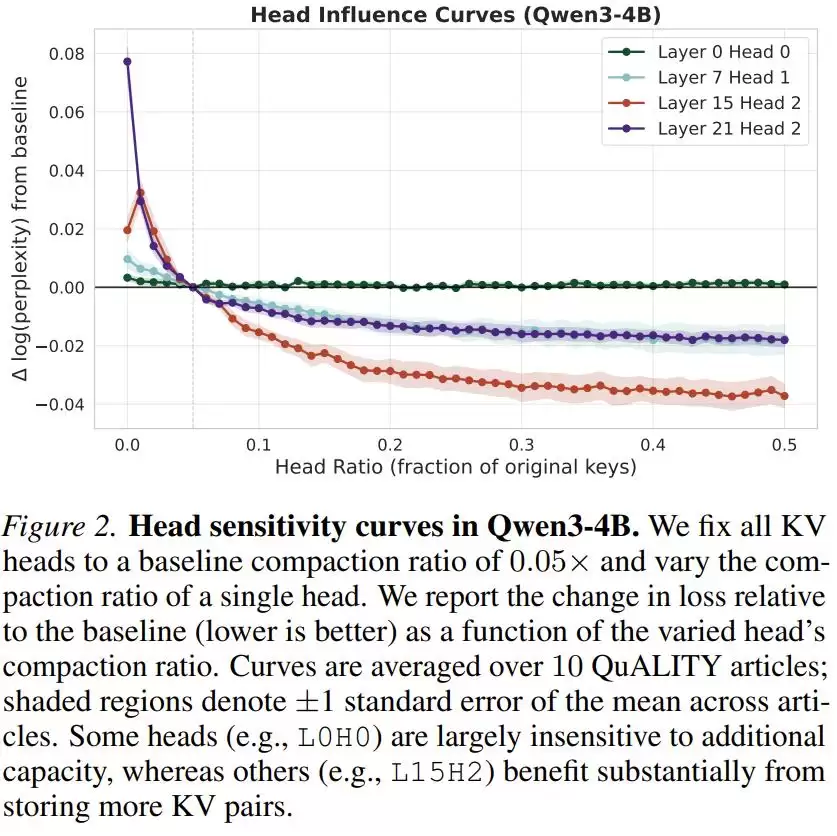
基于这个洞察,团队开发了非均匀压缩(Nonuniform Compaction)策略:为每个模型预先计算一条“敏感度曲线”,就像给每个注意力头做一次体检。实际压缩时,系统不再一刀切,而是把宝贵的显存预算倾斜分配给那些对信息最敏感的“核心Head”。这一策略的引入,让压缩后的模型性能实现了质的飞跃。
即使在像Gemma-3-12B这种大量使用滑动窗口注意力的混合架构模型上,注意力匹配依然表现出惊人的适应性和鲁棒性。
压力测试:见证奇迹的时刻
为了验证这项技术是否真的能在现实世界站住脚,研究人员选了Qwen3-4B、Llama3.1-8B和Gemma3-12B,扔进两个完全不同的测试场。
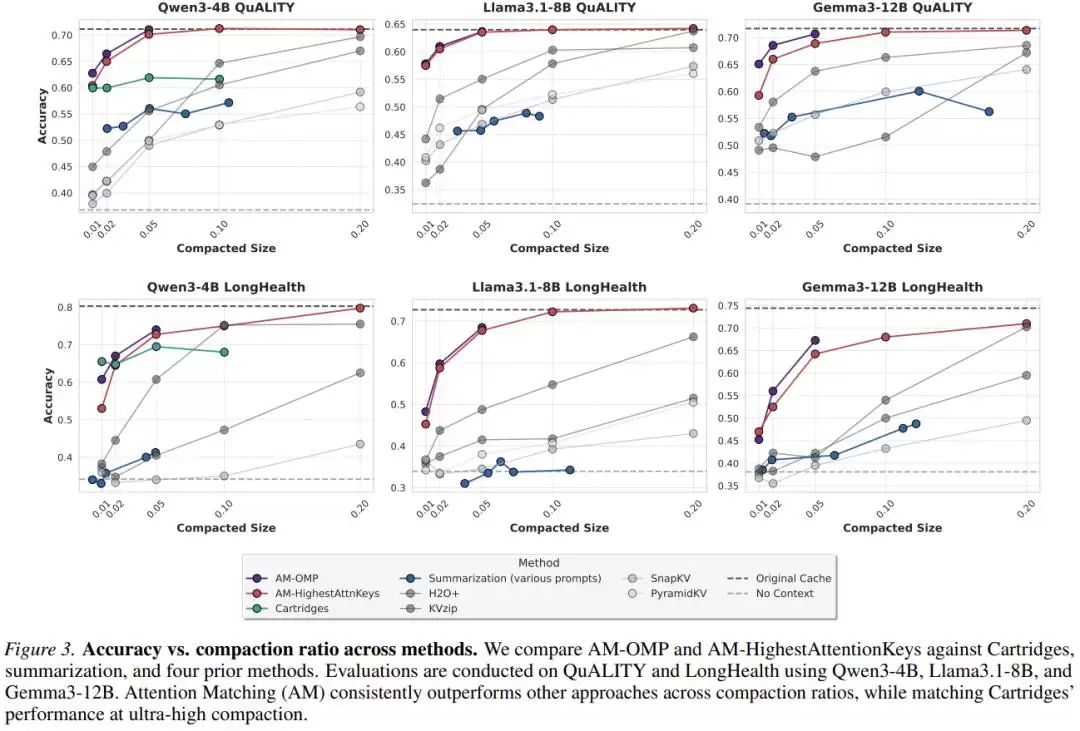
1. QuALITY基准测试:秒杀全场
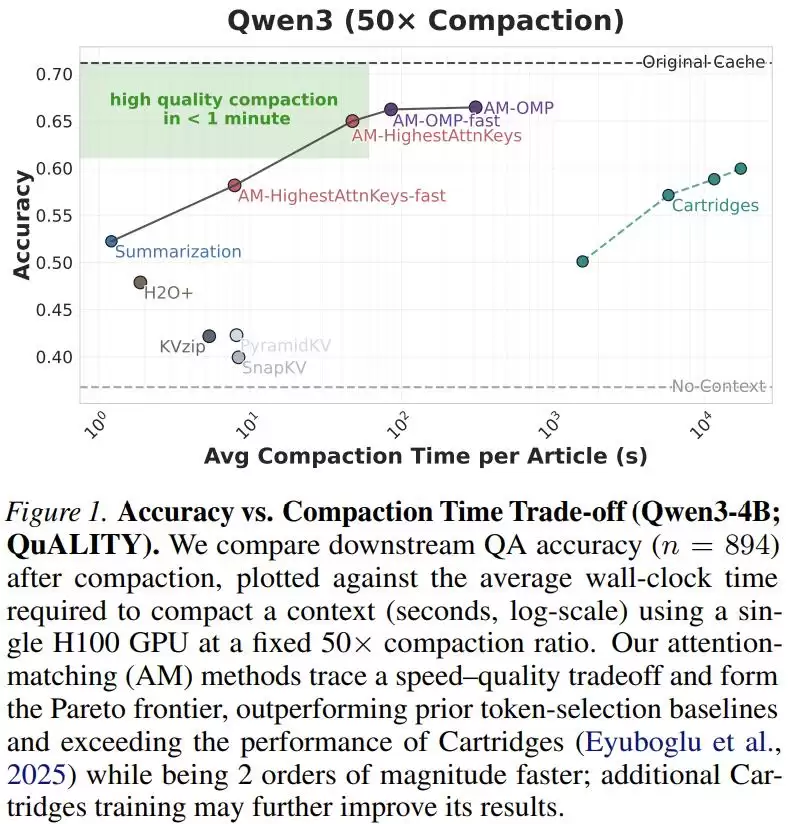
在这个包含5000到8000词的标准阅读理解测试中,Attention Matching在50倍的极限压缩比下,耗时几秒到一分钟(取决于是否使用OMP算法),彻底碾压了H2O+、SnapKV、KVzip等所有基于token裁剪的方案。它的准确率曲线紧紧咬住了耗时数小时的Cartridges,诠释了什么是“快、准、狠”。
2. LongHealth医疗卷宗:传统方案的坟墓
这是代表企业级挑战的数据集——整整60,000个token,塞满多个患者复杂的病历、化验单和用药记录,信息密度极高。
在这个测试中,工业界最爱用的“文本摘要”彻底沦为笑柄——它的准确率跌到了和“不提供任何上下文(No-Context)”一模一样的底线。模型看了摘要等于没看。
而Attention Matching像战神附体,大幅超越了所有传统权宜之计。
当然,Zweiger也坦诚给出了工程建议:“对于这种极高信息密度的任务,如果希望保留所有细节,建议把压缩比调得温和一些(比如10倍或20倍),以换取绝对的精确度。”
3. AIME 2025在线动态压缩:飞行中换引擎
最让人兴奋的,是对在线压缩的概念验证。面对AIME顶级数学推理题,研究人员锁死物理内存上限。模型就像在狭小的笼子里进行极度消耗脑力的计算。
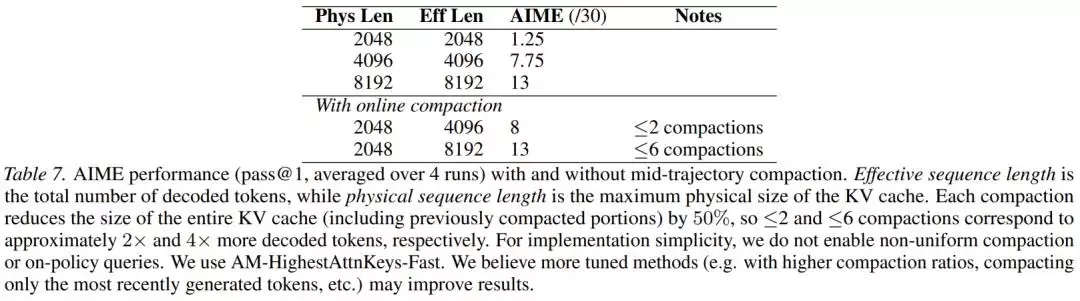
每当内存爆满,系统就瞬间按下暂停键,用Attention Matching把工作记忆暴力压缩50%,然后让模型继续思考。即便在一次解题过程中连续六次“切除”一半的记忆,模型最终依然成功找到了正确答案,表现与拥有无限内存的模型完全一致。
这对像OpenClaw这样需要长时间运行、不断产生冗长工具调用日志的Agent来说,简直是救命稻草。
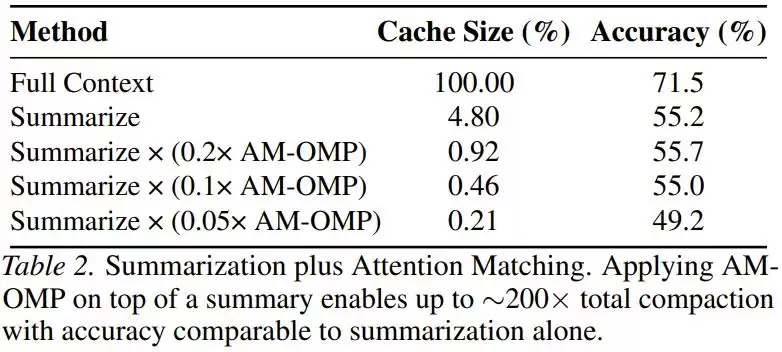
对于追求压缩率、对精度要求稍宽容的场景,研究人员还解锁了一种“200倍压缩”的组合技:先让模型生成文本摘要,再对摘要的KV Cache进行Attention Matching压缩。最终在微乎其微的显存占用下,达到与纯摘要一样的准确率。
结语:从开发者自救到大厂标配的范式转移?
当然,没有魔法是没有代价的。
必须指出的是,如果你面对的是极其复杂的数据,非要追求100倍以上的压缩,那么缓慢的、基于梯度优化的Cartridges依然会在精度上险胜一筹——它可以在更广阔的潜空间中搜索最优解,不受限于“从原始Key中挑选”的设定。
另外,这套技术目前还不是一个可以无脑安装的插件。正如Zweiger所说:“潜空间压缩是一种模型层的技术。你必须拥有访问模型权重的权限。”如果你完全依赖闭源的API(比如直接调用GPT-4接口),就无法自己实现这套魔法。企业要享受这种显存自由,必须拥抱开源权重模型(如Llama 3、Qwen 3)。
要把这种潜空间KV压缩技术编入现代商用推理引擎(那些已经集成了前缀缓存、变长内存打包等复杂技巧的系统),还需要工程师们掉不少头发。
但趋势已经挡不住了。就像Zweiger预言的那样:“我们正在见证上下文压缩发生根本性的范式转移——它正从‘企业自己拼凑的粗糙工程’,进化为‘底层模型提供商内置的核武器’。比如OpenAI最近推出的黑盒压缩端点,返回的是一个不透明的对象,而不是纯文本摘要。”
当“注意力匹配”彻底融入AI基础设施的血液中时,显存瓶颈终将被击碎。到那时,像OpenClaw这样的智能体,也许真的能以单机之躯,吞吐整个世界的知识。
参考链接
https://venturebeat.com/orchestration/new-kv-cache-compaction-technique-cuts-llm-memory-50x-without-accuracy-loss
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MIT注意力匹配:内存暴降50倍精度无损,终结大模型显存危机?要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点通义灵码登录失败多因本地服务未启动,可通过日志确认。重置插件环境、清除状态目录或强制刷新缓存可解决。若问题持续,需释放默认端口(34567)并禁用安全软件,或修改备用端口。
在2026年粤港澳大湾区车展现场,上汽奥迪AUDI品牌正式发布了旗下第二款重磅车型——奥迪E7X,并同步开启用户交付。这款定位为“智慧性能旗舰SUV”的C级全尺寸纯电五座车型,不仅延续了品牌向电动化转型的战略节奏,更在定价策略上做出了大胆创新,让整个豪华电动车市场都感受到了新的竞争压力。作为AUDI
首先,我们直面一个现实困境:中小企业实施数字化转型究竟有多难?资金与技术的高门槛如同两座难以逾越的大山。而数据隐私与安全风险更如同一柄悬顶之剑——一旦出现漏洞,企业信用与客户信任将瞬间崩塌。然而,近期大模型技术的崛起,似乎为这一难题带来了全新的破解之道。 如今的大模型技术,参数规模已普遍达到千亿甚至
项目简介 近期,一款名为Backseat AI的智能工具在英雄联盟玩家群体中引发了广泛关注。它不仅完全免费开放使用,还获得了Riot官方的正式授权——这意味着你可以安心下载使用,不必担心账号安全或封禁风险。概括而言,它是一款AI语音教练,能在对局中通过实时语音为你提供战术点评与决策建议,例如何时购买
- 日榜
- 周榜
- 月榜
热点快看