




企业大模型交互式数据分析与Data Agent方案构建

自然语言驱动数据分析:Text2SQL 的技术路径与实战坑点 在上一篇中,我们聊过企业应用中基于自然语言的交互式数据分析——本质上就是把大模型当作一个更友好的数据袋里(Data-Agent),与现有的 BI 工具形成互补。当时给出了三种基础方案设想。今天这篇,咱们重点拆解其中看起来最直接、也最性感的
自然语言驱动数据分析:Text2SQL 的技术路径与实战坑点
在上一篇中,我们聊过企业应用中基于自然语言的交互式数据分析——本质上就是把大模型当作一个更友好的数据袋里(Data-Agent),与现有的 BI 工具形成互补。当时给出了三种基础方案设想。今天这篇,咱们重点拆解其中看起来最直接、也最性感的一条路:Text2SQL(也叫 NL2SQL)。
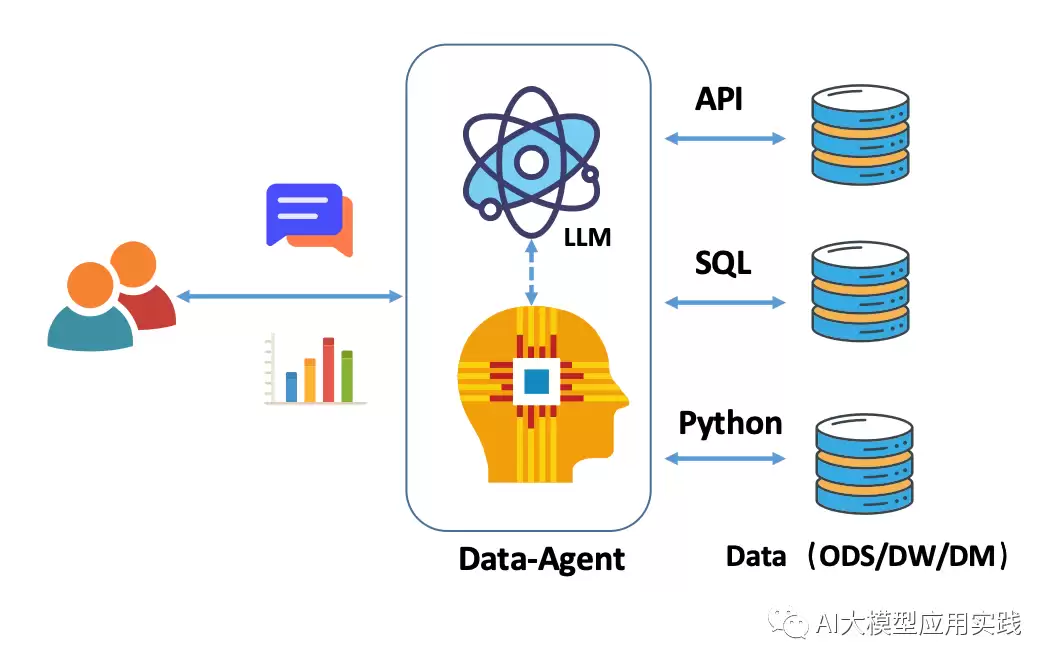
说白了,就是把你说的自然语言,变成数据库能听懂的 SQL 语句。然后让数据库自己回答你。听起来很酷?但真实的坑,比想象中多得多。
1. Text2SQL 的基础实现
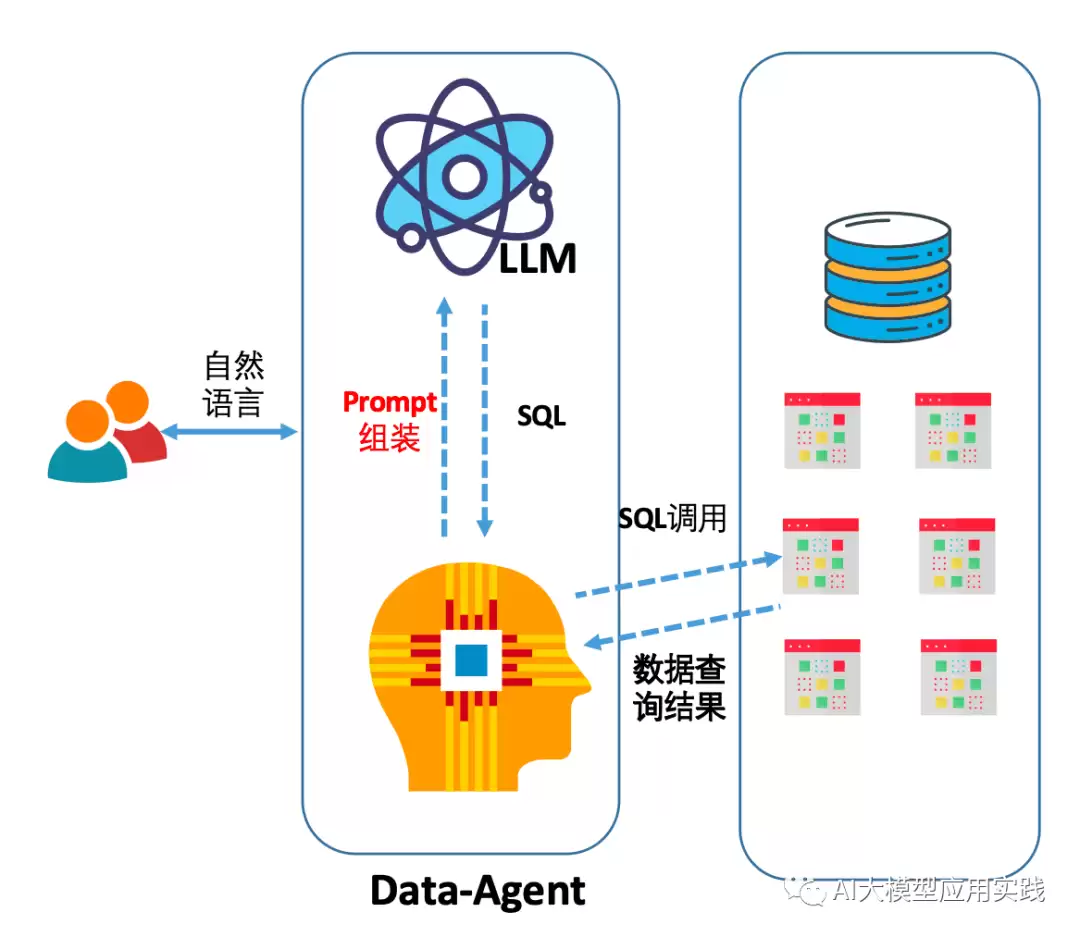
Text2SQL 并不是大模型时代才冒出来的新概念。早在几年前,就有大量机器学习研究项目专注于此。只是大语言模型出现后,凭借强到离谱的自然语言理解能力和推理能力,一下子把这条路推到了聚光灯下。
核心原理并不复杂:把自然语言组装成 Prompt,交给大模型,让它输出 SQL。OpenAI 官方给过一个很标准的例子:
System
/*系统指令*/
Given the following SQL tables, your job is to write queries given a user’s request.
/*数据库内表结构*/
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
...此处省略其他表...
/*问题*/
Write a SQL query which computes the a verage total order value for all orders on 2023-04-01.
看起来就是一个“咒语”就能搞定?确实,做一个原型 demo 五分钟就够了。但是,在实际企业应用中,你会发现这条路上埋伏着各种暗箭。
一个典型的 Text2SQL Prompt 通常由这几个部分组成:
- 指令(Instruction):比如,“你是一个 SQL 生成专家。请参考如下的表格结构,直接输出 SQL 语句,不要多余的解释。”
- 数据结构(Table Schema):相当于翻译中的“词汇表”。包括表名、列名、列类型、列含义、主外键信息。大模型没法直接读取数据库,你得把结构塞进 Prompt。
- 用户问题(Questions):自然语言的问题,比如“统计上个月的平均订单额”。
- 参考样例(Few-shot):一个可选项,但很常用。给一两个样例,让模型照着写。
- 其他提示(Tips):比如要求列名必须用“table.column”的形式,或者禁止某些函数。
2. 问题在哪里?
实现一个原型简单,但让它真正可用,困难指数直接飙升。最关键的问题是:当前大模型输出 SQL 的准确性,远达不到人类工程师的精度。深度学习模型的输出天生带有置信度问题,无法确保绝对可靠。而输出的不确定性,是目前限制大模型进入关键企业系统最大的障碍。
除了模型自身能力,还有一些客观因素:
- 自然语言本身有歧义,而 SQL 是精确语言。比如“谁是这个月最厉害的销售”——到底是指订单数量最多,还是订单金额最大?
- 即便你把数据结构喂给了模型,它也可能因为缺乏行业知识而犯错。比如“分析去年的整体客户流失率”,如果模型不理解“客户流失率”的含义,就可能瞎编。
除此之外,企业应用场景还会带来两个更严重的挑战:
可能出现“正常运行的假象”
这是最坑的地方:它正常执行了,但结果是错的。Text2SQL 直接输出 SQL 给数据库,只要语法正确,执行就成功,哪怕语义上完全错误。这和 Text2API 不同——API 有严格的输入输出校验,错误很大概率会暴露。而在 Text2SQL 里,你很难察觉。
举个简单的例子:同一个问题,大模型输出了两个 SQL,都能执行,但第二个才是对的。而第一个虽然能跑出结果,但查询逻辑完全错了。这样的错误,对使用者来说几乎是隐形的。
造成这种困境的核心在于:判断一段 SQL 代码是否正确,远比判断一个选择题答案或字符串相似度复杂得多。
拿 Text2SQL 输出评估工具 TestSuiteEval 中的例子来说:Gold 是标准答案,predicted1 和 predicted2 是两个模型输出。predicted2 是正确的,predicted1 是错误的。但:
- 如果只看执行结果,predicted1 的结果可能和标准答案完全一样,但实际上 SQL 是错的。
- 如果直接对比输出 SQL,predicted2 和标准答案不完全一致,你可能误判它是错的,但它在这个场景下确实正确。
所以,你不能单靠执行结果来判断,也不能简单地把输出 SQL 和标准答案逐字对比。这就是评估的复杂所在。
企业应用的特点会放大错误概率
我们在上篇总结过企业分析场景的几个特点:
- 真实数据库的结构比测试应用复杂得多。
- 真实分析逻辑更复杂,几百行的 SQL 报表很常见。
- 不仅有正确性要求,还有性能要求——大型数据仓库里,查询慢一秒都可能出问题。
那么,大模型能应对吗?坦白说,从目前的测试结果看,让大模型在这些场景下达到人类工程师的精度,是不现实的。但我们可以从几个方向入手,让它在部分场景下先做到可用:
- 选择或微调合适的大模型
- 提示词工程优化
- 应用场景的限制与设计
3. 优化一:选择合适的大模型
模型本身无非两条路:要么选用最强的通用模型(比如 GPT-4),要么通过 SFT(高效微调)训练一个更适配自身任务的模型。怎么选?得看评估。
Spider 基准测试
Spider 是 Text2SQL 领域最主流的评估数据集。包含 1 万多个自然语言问题及其对应的 SQL,覆盖 200 多个数据库、100 多个领域。你可以自己下载测试,也可以提交官方排名。
目前官方最新排名中,GPT-4 依然是大模型中的“遥遥领先”。注意,排名列表里不仅有模型名,还包括提示工程技术(比如 DAIL-SQL 等)。
BIRD 基准测试
BIRD 是阿里达摩院联合香港大学推出的,比 Spider 更贴近真实应用——考虑了数据库信息的复杂性和 SQL 运行效率。包含约 12000 个自然语言问题与 SQL,覆盖 37 个专业领域、90 多个数据库。
在这个更难的测试集上,大模型的最高分只有 60.71%,而人类能力是 92.96%。差距一目了然。
微调模型
实际企业应用中,由于数据安全或网络安全,你可能只能用私有模型。直接拿开源模型做 Text2SQL 效果不算好,微调就成了常规手段。这里推荐两个开源项目:
- DB-GPT-Hub:专注于 LLM 在 Text2SQL 上的微调实验,支持多种模型和数据集。根据公开结果,meta 的 CodeLlama-13b 表现不错。
- SQLCoder:基于 CodeLlama 微调,其内部评估显示与 GPT-4 不相上下。
从当前数据看,CodeLlama-13b 和 SQLCoder-34b 可能是开源领域比较合适的选择。
4. 优化二:提示工程
在基准测试中,很多高分结果后面都跟着 DAIN-SQL、DIN-SQL、C3-SQL 这类标注,它们本质上是提示工程方案。好的提示 + 好的模型 = 最高分。这里介绍两种:
DAIN-SQL
阿里推出的方法,在 Spider 上拿了 86.6 分(当时最高),BIRD 上也有 57.41 分。核心思路:在 Prompt 里注入一些相似的样例,利用大模型的上下文学习能力。具体怎么选样例?通过用户提问的“骨架”找相似问句,再通过预生成 SQL 的“骨架”找相似 SQL,排序后取最相似的组装进 Prompt。
问题在于:备选样例从哪儿来?可以用公开测试集,也可以用企业自己的训练数据集。门槛不低。
C3-SQL
浙江大学推出的 zero-shot 方法,不依赖样例。它从三个角度优化:
- Clear Prompting:在构建 Prompt 前,先让大模型分析哪些表、列最相关,只注入这些必要信息,而不是整个数据库结构。
- Calibration Bias Prompting:在上下文里加入一些“注意点”或规则,指导模型正确行为。
- Consistent Output:让模型输出多次 SQL,根据执行结果“投票”选出最一致的。比如输出四次,三个结果相同,就认为那是正确的。
实际企业应用中,前两个 C 更实用——精简注入结构 + 增加规则。最后一个多次执行可能带来性能开销,适合数据量小的场景。
5. 优化三:应用场景限制与设计
既然模型精度不可能百分百,我们就得在设计上做文章:
- 优先用在特定场景:比如企业 BI 中的即席查询。特点就是条件灵活、数据结构相对简单,用自然语言生成查询天然合适。
- 配合其他方案:如果中间处理逻辑复杂,单次 SQL 搞不定,可以考虑 Text2API 的方式(上篇有讲)。
- 从小主题开始:如果底层数据实体太多,Prompt 很容易撑爆上下文。可以按数据仓库的“主题”来设计,每次只注入相关表的 schema。
总的来说,Text2SQL 是一条看上去最简单、最直接的路。但企业数据环境的复杂性和对可靠性的严苛要求,决定了它需要大量的模型优化和针对性设计。否则,理想很丰满,现实很骨感。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:企业大模型交互式数据分析与Data Agent方案构建要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点通义灵码登录失败多因本地服务未启动,可通过日志确认。重置插件环境、清除状态目录或强制刷新缓存可解决。若问题持续,需释放默认端口(34567)并禁用安全软件,或修改备用端口。
在2026年粤港澳大湾区车展现场,上汽奥迪AUDI品牌正式发布了旗下第二款重磅车型——奥迪E7X,并同步开启用户交付。这款定位为“智慧性能旗舰SUV”的C级全尺寸纯电五座车型,不仅延续了品牌向电动化转型的战略节奏,更在定价策略上做出了大胆创新,让整个豪华电动车市场都感受到了新的竞争压力。作为AUDI
首先,我们直面一个现实困境:中小企业实施数字化转型究竟有多难?资金与技术的高门槛如同两座难以逾越的大山。而数据隐私与安全风险更如同一柄悬顶之剑——一旦出现漏洞,企业信用与客户信任将瞬间崩塌。然而,近期大模型技术的崛起,似乎为这一难题带来了全新的破解之道。 如今的大模型技术,参数规模已普遍达到千亿甚至
项目简介 近期,一款名为Backseat AI的智能工具在英雄联盟玩家群体中引发了广泛关注。它不仅完全免费开放使用,还获得了Riot官方的正式授权——这意味着你可以安心下载使用,不必担心账号安全或封禁风险。概括而言,它是一款AI语音教练,能在对局中通过实时语音为你提供战术点评与决策建议,例如何时购买
- 日榜
- 周榜
- 月榜
热点快看