




Selenium自动化测试入门:从环境搭建到首个可维护用例

Selenium 入门的核心不在于记住多少 API,而在于把三件事想清楚:环境别装错版本、等待机制别用 sleep、用例结构别写成流水账。下面按照“装环境 → 跑通第一个脚本 → 理解等待 → 选对定位器 → 拆成 Page Object”的顺序走一遍,每一步都附上代码,踩过的坑直接标出来。
Selenium 能帮你做什么——先划边界再动手
Selenium 干的事情很明确:用代码驱动真实浏览器,来完成页面操作。它的能力边界很清楚——凡是需要浏览器渲染、JS 执行、用户交互的场景,它都能覆盖;但它不是万能胶,不适合所有自动化需求。
适合用 Selenium 的场景:Web UI 回归测试、表单交互验证、跨浏览器兼容性检查、需要登录态的页面操作验证。
不适合的场景:纯 API 接口测试(用 requests 或 Postman 更轻)、移动端原生 APP 测试(那是 Appium 的活)、性能压测(Selenium 开浏览器成本太高,压不出量)。
有个典型反面案例:有人拿 Selenium 做接口级别的数据校验,每次跑完一轮要 40 分钟,换成直接调接口后缩到 3 分钟。工具选对了,后面才不浪费时间。
环境搭建:就三件事
第一件事,装 Selenium 库。Python 环境下一行命令:
pip install selenium
第二件事,确认本机有浏览器。Chrome 和 Firefox 都行,Chrome 用的人最多,社区资料也最全。
第三件事,驱动。这是以前最容易踩坑的地方——Chrome 版本和 ChromeDriver 版本对不上,脚本直接报错。但 Selenium 4.6 之后内置了 Selenium Manager,它会自动检测浏览器版本并下载匹配的驱动,不需要手动去找了。
验证环境是否就绪,跑这段:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
print(driver.title)
driver.quit()
如果正常弹出浏览器、打印出页面标题、浏览器关闭,环境就没问题。
踩坑提醒:如果公司网络有袋里或防火墙,Selenium Manager 自动下载驱动可能失败。这种情况下需要手动下载 ChromeDriver 放到 PATH 里,或者在代码里指定路径:
from selenium.webdriver.chrome.service import Service
service = Service("/path/to/chromedriver")
driver = webdriver.Chrome(service=service)
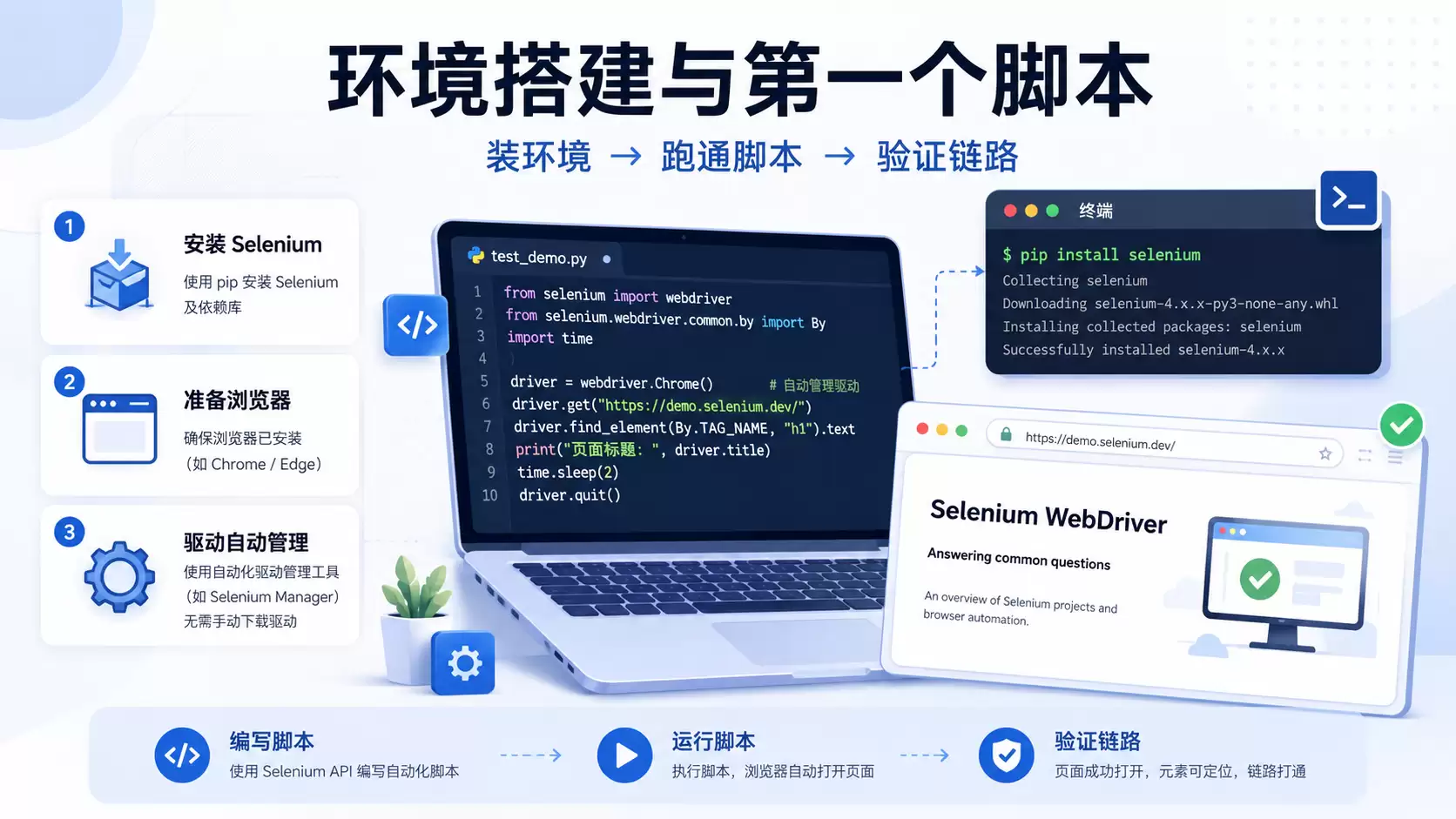
第一个测试脚本:先跑通,再优化
很多教程上来就讲框架设计,其实应该反过来——先写一个最简单的、能跑通的脚本,确认链路没问题,再考虑怎么组织。
假设要测试一个搜索功能:“打开页面 → 输入关键词 → 点搜索 → 验证结果页有内容”。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
try:
# 1. 打开目标页面
driver.get("https://www.example.com")
# 2. 找到搜索框,输入关键词
search_box = driver.find_element(By.NAME, "q")
search_box.clear()
search_box.send_keys("selenium testing")
# 3. 提交搜索
search_box.send_keys(Keys.RETURN)
# 4. 简单验证:页面标题是否包含搜索词
assert "selenium" in driver.title.lower(), "搜索结果页标题不符合预期"
print("测试通过")
except Exception as e:
print(f"测试失败: {e}")
finally:
driver.quit()
这段代码完成了“操作 → 断言 → 清理”的完整闭环。先确认这个闭环能跑,后面的优化才有基础。
等待机制:新手踩坑第一名
最常见的 Selenium 报错就是 NoSuchElementException——不是元素不存在,是页面还没加载完你就去找它了。
三种等待方式,推荐程度差很多。
time.sleep() 是最差的选择。写 sleep(3) 意味着不管页面是不是早就加载好了,都要傻等 3 秒。页面快的时候浪费时间,页面慢的时候 3 秒还不够——两头不讨好。
隐式等待 implicitly_wait() 好一点,它设一个全局超时,Selenium 在找元素时会轮询直到找到或超时:
driver.implicitly_wait(10)
# 全局生效,最多等 10 秒
问题是它是全局的,没法针对不同元素设不同策略,而且和显式等待混用容易出诡异的超时叠加问题。
显式等待是正解。它让你针对某个具体条件设等待,条件满足立刻往下走:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
# 等待某个元素可点击
button = wait.until(EC.element_to_be_clickable((By.ID, "submit-btn")))
button.click()
# 等待某个元素出现在 DOM 中
result = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".result-item")))
常用的 expected_conditions 记住这几个就够应付大多数场景:
presence_of_element_located:元素出现在 DOM 里(不一定可见)visibility_of_element_located:元素可见element_to_be_clickable:元素可点击text_to_be_present_in_element:元素文本包含指定内容url_contains:URL 包含指定字符串
一条原则:每次交互前都确认目标元素处于预期状态。不要假设“上一步点了提交,下一步结果页肯定加载好了”,网络波动、JS 异步渲染随时可能让你的假设失效。

元素定位:优先级排一下
Selenium 提供了 8 种定位方式,但实际项目里常用就三种,按优先级排:
第一优先:ID。如果目标元素有 id 属性,直接用 By.ID,最快最稳,不受 DOM 结构变化影响。
driver.find_element(By.ID, "username")
第二优先:CSS 选择器。大多数元素没有 id,这时候 CSS 选择器比 XPath 更简洁、可读性更好、执行速度也略快。
# 类名定位
driver.find_element(By.CSS_SELECTOR, ".login-form .submit-btn")
# 属性定位
driver.find_element(By.CSS_SELECTOR, "input[data-testid='email']")
# 层级定位
driver.find_element(By.CSS_SELECTOR, "div.container > ul > li:first-child")
第三优先:XPath。在需要按文本内容定位、或者需要向上查找父元素时,XPath 是唯一选择。
# 按文本内容找按钮
driver.find_element(By.XPATH, "//button[text()='提交']")
# 按部分文本匹配
driver.find_element(By.XPATH, "//span[contains(text(), '搜索结果')]")
避坑:不要写过长的绝对路径 XPath,比如 //html/body/div[3]/div[2]/form/input[1]——页面结构稍微一变就全废了。用相对路径配合有意义的属性锚定,稳定性好得多。
如果你的项目前端团队愿意配合,最好的做法是让他们给关键交互元素加 data-testid 属性,专门给测试用,不受样式重构影响。
Page Object 模式:项目大了不拆就是灾难
当测试用例超过 10 个,如果所有定位器和操作逻辑全写在测试方法里,改一个元素选择器要翻遍所有文件。Page Object 模式解决的就是这个问题:把页面元素和操作封装成类,测试用例只调方法,不直接碰选择器。
以登录页为例:
# pages/login_page.py
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class LoginPage:
URL = "https://www.example.com/login"
# 元素定位器集中管理
USERNAME_INPUT = (By.ID, "username")
PASSWORD_INPUT = (By.ID, "password")
SUBMIT_BUTTON = (By.CSS_SELECTOR, "button[type='submit']")
ERROR_MESSAGE = (By.CSS_SELECTOR, ".error-msg")
def __init__(self, driver):
self.driver = driver
self.wait = WebDriverWait(driver, 10)
def open(self):
self.driver.get(self.URL)
return self
def login(self, username, password):
self.wait.until(EC.visibility_of_element_located(self.USERNAME_INPUT))
self.driver.find_element(*self.USERNAME_INPUT).clear()
self.driver.find_element(*self.USERNAME_INPUT).send_keys(username)
self.driver.find_element(*self.PASSWORD_INPUT).clear()
self.driver.find_element(*self.PASSWORD_INPUT).send_keys(password)
self.driver.find_element(*self.SUBMIT_BUTTON).click()
def get_error_message(self):
error = self.wait.until(EC.visibility_of_element_located(self.ERROR_MESSAGE))
return error.text
测试用例就变得很干净:
# tests/test_login.py
import pytest
from selenium import webdriver
from pages.login_page import LoginPage
@pytest.fixture
def driver():
d = webdriver.Chrome()
yield d
d.quit()
def test_invalid_login_shows_error(driver):
page = LoginPage(driver).open()
page.login("wrong_user", "wrong_pass")
assert "用户名或密码错误" in page.get_error_message()
def test_empty_password_shows_error(driver):
page = LoginPage(driver).open()
page.login("some_user", "")
assert "请输入密码" in page.get_error_message()
页面元素变了,只改 LoginPage 里的定位器,所有引用它的测试用例不用动。

跑测试:用 pytest 组织,别散着写
单个脚本用 python test.py 能跑,但用例多了以后需要框架来管理执行、报告和前置/后置操作。Python 生态里 pytest 是最主流的选择。
装好 pytest:
pip install pytest
项目结构建议:
project/
├── pages/ # Page Object 类
│ ├── login_page.py
│ └── home_page.py
├── tests/ # 测试用例
│ ├── conftest.py # 公共 fixture(比如 driver 初始化)
│ ├── test_login.py
│ └── test_search.py
└── pytest.ini # pytest 配置
把 driver 的初始化和清理放进 conftest.py,所有测试文件自动共享:
# tests/conftest.py
import pytest
from selenium import webdriver
@pytest.fixture
def driver():
options = webdriver.ChromeOptions()
# 无头模式,CI 环境常用
# options.add_argument("--headless")
d = webdriver.Chrome(options=options)
d.maximize_window()
yield d
d.quit()
运行全部测试:
pytest tests/ -v
加 -v 看详细结果,加 --tb=short 看精简的报错堆栈,加 -k "login" 只跑名字包含 login 的用例。
我踩过的坑,列一份清单
元素被遮挡点不到。页面有浮层、Cookie 提示、固定导航栏挡住了目标按钮。Selenium 会抛 ElementClickInterceptedException。解决办法:先关掉浮层,或者用 JS 直接点:
driver.execute_script("arguments[0].click();", element)
iframe 里的元素找不到。如果目标元素在 iframe 里,必须先切进去:
driver.switch_to.frame("frame-name")
# 操作完再切回主文档
driver.switch_to.default_content()
页面跳转后句柄丢失。点击链接打开了新标签页,但 Selenium 的控制还在原标签。需要手动切换:
# 获取所有窗口句柄
handles = driver.window_handles
# 切到最新打开的
driver.switch_to.window(handles[-1])
下拉框选不中。原生 元素用 Selenium 的 Select 类:
from selenium.webdriver.support.ui import Select
dropdown = Select(driver.find_element(By.ID, "country"))
dropdown.select_by_visible_text("中国")
# 或者
dropdown.select_by_value("CN")
如果是前端框架自定义的下拉组件(不是原生 select),Select 类不管用,需要先点击展开,再点击选项,当普通元素操作。
CI 环境跑不起来。服务器没有图形界面,Chrome 启动失败。加 headless 模式:
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=options)
从"能跑"到"能维护",几条原则
测试用例之间不要有依赖。每个用例独立跑都能通过,不要依赖"前一个用例已经登录了"。用 fixture 做前置准备,用例之间互不影响。
断言写清楚预期。assert result 不如 assert result == "预期文本"——失败时报错信息差别很大,前者只告诉你 False,后者告诉你实际值是什么。
截图留证。测试失败时自动截图,排查问题快得多:
@pytest.hookimpl(tryfirst=True, hookwrapper=True)
def pytest_runtest_makereport(item, call):
outcome = yield
report = outcome.get_result()
if report.when == "call" and report.failed:
driver = item.funcargs.get("driver")
if driver:
driver.sa ve_screenshot(f"screenshots/{item.name}.png")
不要过度自动化。不是所有测试都适合用 Selenium 做。纯逻辑计算、API 返回值校验、数据格式验证这些,用单元测试或接口测试更快更稳。Selenium 留给那些"必须打开浏览器才能验证"的场景。
FAQ
Q1:Selenium 4 和 Selenium 3 差别大吗,新项目该用哪个版本?
新项目直接用 Selenium 4。主要变化有三个:内置 Selenium Manager 自动管理驱动(省掉最大的环境坑)、相对定位器(locate_with 可以按"在某元素右边"来定位)、以及对 CDP(Chrome DevTools Protocol)的原生支持。老项目从 3 升到 4 的迁移成本不高,大部分 API 向下兼容。
Q2:Headless 模式跑出来的结果和有界面时会不一样吗?
大多数情况下一致,但有例外。某些页面的 JS 行为依赖窗口尺寸,headless 默认窗口可能和你本地不同,导致元素布局变化。建议 headless 模式下显式设窗口大小:
options.add_argument("--window-size=1920,1080")
另外,部分网站会检测 headless 环境并返回不同内容,测试时如果发现结果不一致,先排查这个。
Q3:测试数据应该写死在代码里还是外部管理?
小项目写死在代码里没问题。用例超过 20 个以后,建议把测试数据抽到 JSON、YAML 或 CSV 文件里,用 pytest.mark.parametrize 做数据驱动。这样加新的测试场景只需要加一行数据,不用改代码。
Q4:Selenium 执行速度慢,有办法加快吗?
几个方向:headless 模式比有界面快;显式等待替换 sleep 减少空等时间;禁用不必要的浏览器功能(图片加载、通知弹窗);用例之间并行执行(pytest-xdist 插件)。但核心瓶颈在于 Selenium 每次操作都要和浏览器通信,它天然就不适合追求速度,需要快速反馈的场景可以用 Playwright 替代——Playwright 的自动等待机制和执行速度都更好。
Q5:pytest 和 unittest 选哪个?
pytest。写法更简洁(不需要继承 TestCase 类)、fixture 机制比 setUp/tearDown 灵活得多、插件生态丰富(并行执行、报告生成、失败重试都有现成插件)。unittest 是标准库自带的,不需要额外安装,但新项目没有理由不用 pytest。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

2026实测解析GPT-5.5模型能力详解与国内合规使用规范
2026年,AI大模型迎来了又一次迭代升级。GPT-5 5凭借在多模态精细化处理能力上的跨越式突破,正逐步成为职场办公、内容创作、代码开发以及数据优化等领域的核心生产力工具。然而,对国内多数用户而言,当前仍面临不少现实难题:渠道杂乱、合规边界模糊、账号频繁被封、数据泄露风险——各类非正规镜像站、共享

分时操作系统和实时操作系统的主要区别
分时操作系统和实时操作系统区别 ?️ 操作系统家族里,有两类系统经常被放在一起比较:分时操作系统和实时操作系统。它们虽然都叫“操作系统”,但设计哲学、工作机制和应用场景可以说是天差地别。一个追求“公平共享”,一个追求“确定性响应”。这篇文章打算从定义、核心机制、调度策略、实际应用等维度,把这两者的本

企业AI智能体从零搭建实战踩坑经验全记录
去年开始用腾讯云智能体开发平台(ADP)跑了几个企业项目,从最基础的客服Bot一路干到多Agent协同系统,中间踩的坑不少,但积累下来的经验价值也相当可观。这篇文章就聊聊实际落地过程里的那些关键节点和教训,给同样在腾讯云上折腾AI Agent的朋友做个参考。为什么选腾讯云ADP而不是从零搭建做第一个

Selenium自动化测试入门:从环境搭建到首个可维护用例
Selenium 入门的核心不在于记住多少 API,而在于把三件事想清楚:环境别装错版本、等待机制别用 sleep、用例结构别写成流水账。下面按照“装环境 → 跑通第一个脚本 → 理解等待 → 选对定位器 → 拆成 Page Object”的顺序走一遍,每一步都附上代码,踩过的坑直接标出来。 Sel

专业表格魔法师 QoderWork CN 让脏数据秒变仪表盘神器
使用案例 今天聊聊怎么用阿里巴巴的 QoderWork CN 桌面应用智能体,把 Excel 里那堆乱糟糟的原始数据清洗干净,再做成可视化的看板。整个过程基本不需要写代码,全靠自然语言对话就能搞定。下面就用一个实际案例,把操作步骤拆开来讲。 步骤一:安装并注册 QoderWork CN 账号 先到








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
热门教程
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
2026-06-03 21:20
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
