




Harness Engineering从想法到发布的一次完整实践全流程解读

先说几个关键判断:AI coding 不会替你省掉软件工程的基本功——这是《Harness Engineering 又来碘伏了》留的那个悬念。三笔债:可见性、状态持久化、质量门禁。怎么还?《蒸馏 Google 工程基因》给出了一半答案:agent-skills 把高级工程师的判断力结构化,覆盖了质量门禁和可见性,但状态持久化那条一直没有落地。
直到用 OpenSpec + agent-skills 跑通了一个真实项目:jk,一个 Pipeline-native 的 Jenkins CLI。从「我想做个 Jenkins CLI」到 v0.1.0 发布,每一步都有凭据。这篇文章就是这次完整实践的记录——看看两个工具碰在一起到底发生了什么。
一、两个未竟的问题
《蒸馏 Google 工程基因》里 agent-skills 管的是「一次任务怎么做」,管不了「多次 session 之间项目状态怎么延续」。agent 没有记忆,context 会压缩,上一次做到哪里、踩了什么坑、下一步是什么——skill 本身解决不了这个问题。另一个问题是没有一次完整的实践记录:概念和设计讲清楚了,但实际用起来是什么感觉,从来没有人跑通过。
OpenSpec 是缺失的那块。它的核心设计是 spec 与 change 分离:spec 是意图载体,跨 session 稳定;change 记录执行状态,append-only。agent 每次进来,读 spec 知道要做什么,读 change 知道做到哪了。context 可以压缩,项目状态不会丢。加上 agent-skills,三条原则才有了完整的覆盖。jk 就是这套组合跑通的一次真实记录——全程用这套工作流从想法走到发布。
二、从一句话到三个设计决策
「我想做一个 Jenkins CLI 工具。」——agent 拿到这句话会写出点东西,但大概率不是你要的那个。它不知道现有工具哪里不够,不知道用户是谁、在什么场景下用、什么叫做完。
这就是 idea-refine 存在的原因。它不是头脑风暴工具,而是一个把隐藏假设逼出来的结构化对话流程:先发散、再收敛、最后输出一份可以直接驱动后续工作的 one-pager。
在 jk 的开发里,idea-refine 经历了三轮关键交互,每轮都有一个具体的转折:
第一轮:「替代浏览器 Tab」和「快速出结果」之间的张力。agent 直接点出来:这两个目标会打架。真正「替代浏览器 Tab」需要宽泛的功能覆盖,「快速出结果」需要窄而深。jk 的第一个实质性决策由此出炉:不做通用工具,只做 Pipeline operator 的日常工具——触发、监控、看日志、回应 input step。
第二轮:URL-as-identity。你问「怎么指定要操作哪个 Jenkins 实例?」常见答案是 profile、context、配置文件。但实际使用习惯是直接粘贴浏览器里的 Jenkins URL。agent 从这个行为模式里提炼出核心设计哲学:URL 即身份。每个命令以 Jenkins URL 为输入,hostname 隐式决定使用哪份凭证,无 profile、无 context、无 use。这不是一个功能,是整个 CLI 的交互范式。
第三轮:schema 设计反转。最初的设想是「原样反映 Jenkins API 的响应」。用户提出:「我无法控制 Jenkins 版本。」agent 意识到这意味着什么——Jenkins 升级改字段,所有依赖 jk 输出的脚本集体崩溃。当场反转:jk 维护自有 schema,由 jk 的版本号控制,不随 Jenkins 升级漂移。--raw 作为逃生舱留着。schemaVersion: "1" 出现在每条命令输出的第一行,是这次反转留下的直接痕迹。
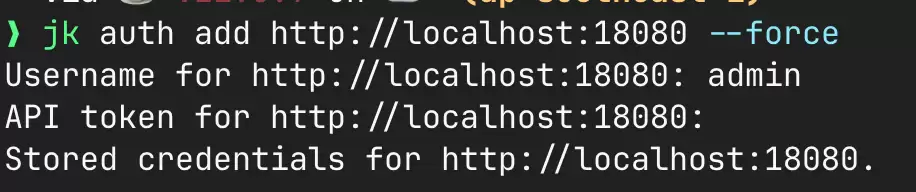
三轮之后,「我想做一个 Jenkins CLI」变成了可以驱动实现的设计约束。这些约束直接体现在最终产品里:jk auth add 只需要一个 URL,不需要给实例起名字、不需要选 profile。
idea-refine 做的事,对应的是《Harness Engineering 又来碘伏了》里的可见性原则:「Agent 看不见的就不存在。」这三个设计决策如果没有在开始就显式化,会在实现阶段以 bug、返工、和「这不是我想要的」的形式还回来。
三、两套 spec 打架的那一秒
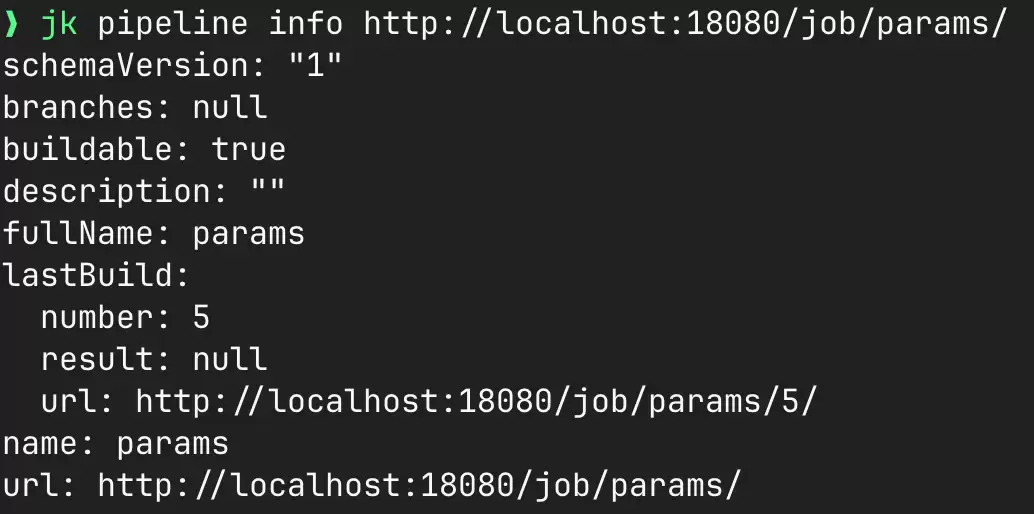
idea-refine 的产出是一份 one-pager,OpenSpec 的 /opsx-propose 负责把它拆成可执行的 artifacts。
/opsx-propose 生成了四类文件:
proposal.md——做什么、为什么design.md——10 个技术决策- 7 份
specs/*/spec.md——auth、build、errors、output、pipeline、tls-and-transport、url-resolution tasks.md——17 组、约 80 个 checkbox,把整个实现切成可执行的最小单元
artifacts 创建完成后,手动触发了 spec-driven-development。然后问题出现了。
spec-driven-development 的第一步是写项目级 spec——一份定义「在这个 repo 里怎么干活」的文档:构建命令、目录布局、代码风格、边界规则。但 OpenSpec 刚刚已经生成了 7 份 specs/*/spec.md。两套文档,都叫 spec,放在同一个 repo 里。
agent 加载 skill 后的第一个输出,直接处理了这个冲突:
OpenSpec specs = what the product does (capabilities & requirements)Project spec = how we work (toolchain, layout, style, guardrails)
裁决结果:SPEC.md 放在 repo 根目录,作为「项目宪法」;openspec/specs/ 管产品行为;两者边界从此清晰,永不合并。
这条边界在开发过程中一直有效。一个具体的例子:开发后期把「credentials 加密留作 v0.2」这条决定从 SPEC.md 的 Open Questions 转为 Past Decisions——这是 engineering practice 层面的判断,改 SPEC.md,不动 OpenSpec。如果决定的是「新增 jk auth encrypt 命令」,那就必须开新的 OpenSpec change,因为那是 product beha vior。
这条边界不是自然存在的。它是两个工具碰撞的那一秒,由 skill 即时裁决出来的。如果没有 spec-driven-development 的介入,SPEC.md 和 openspec/specs/ 很可能会在实现阶段互相打架——改了这边,那边过时;agent 下次进来,不知道以哪个为准。
四、tasks.md:让「下一步做什么」的决策成本归零
spec 的边界划清之后,剩下的问题是:怎么执行。tasks.md 就是答案。
/opsx-propose 生成的 tasks.md 里有 17 个任务组,约 80 个 checkbox。每个 checkbox 都是一个独立可执行的最小单元,有明确的完成标志。比如第 4.5 条:
不是「写单元测试」,是「这些输入,这些输出,测试通过才算完」。checkbox 的粒度就是验收标准的粒度。
agent 每次进来,第一件事是找下一个 - [ ]——不需要上下文重建,不需要问「我们做到哪了」。但更关键的是 context 压缩发生时的行为。
jk 的开发跨越了多次 session,context 被压缩了不止一次。agent 在 context 压缩时自动生成摘要,摘要里有一个固定的 Goal 段落,每次都完整保留了整个开发流程的标记:
Goal: Design, scaffold, and incrementally implement jk via idea-refine → OpenSpec change → SPEC.md → code flow.
Current: Task group 9 (output rendering), 3 of 5 checkboxes done.这一行是「记忆脊柱」。它不依赖 conversation history,不依赖外部工具,只要 tasks.md 在 repo 里,压缩摘要就能精确定位到「上次做到哪了」。
这正是 OpenSpec 的 tasks.md 与普通 TODO list 的本质区别:TODO list 的状态活在你的记忆或外部工具里;tasks.md 的状态活在 repo 里,跟代码一起被 git clone,被压缩摘要引用。context 可以压缩,项目状态不会丢。
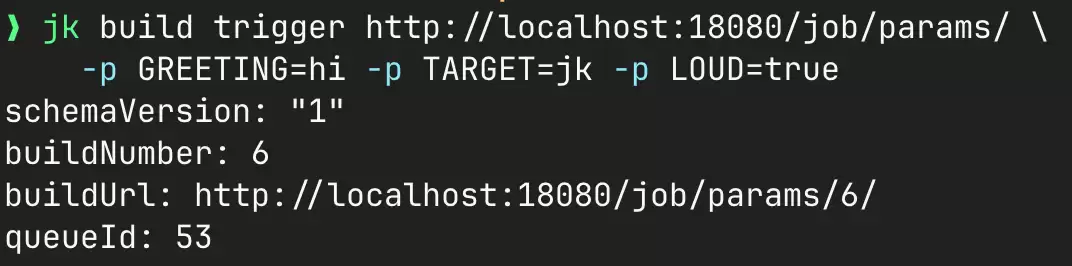
jk build trigger 是 tasks.md 第 11 组的产物——trigger + 实时状态轮询 + 退出码等于 build 结果。这条命令能存在,是因为在 context 压缩了三次之后,agent 还能找到并完成它对应的 checkbox。
这是《Harness Engineering 又来碘伏了》里「状态持久化」原则最具体的落地形态。
五、没有人要求,但它自己加载了
实现 internal/jenkinsurl 是 tasks.md 第 4 组,共 5 个 checkbox:定义 Ref 结构体、实现 Parse()、HostKey()、APIPath(),以及单元测试。
任务描述里没有出现「TDD」这个词。
agent 开始动手之前,输出了这样一段判断:
inputs/outputs 明确,有多个边界情况,适合 test-driven-development。
然后它加载了 test-driven-development skill,按 RED-GREEN-REFACTOR 顺序推进:先把 tasks.md 里「10 个真实 Jenkins URL 样本」的 spec scenarios 全部写成失败的测试,再让测试通过,最后清理实现。
没有人要求这样做。
skill 的作用不是提供步骤,而是让正确的 pattern 在合适的时机自动发生。agent 识别到「inputs/outputs 明确」这个信号,就知道该用哪套 pattern——不需要人来提醒,不需要 prompt 里写「请使用 TDD」。这正是《蒸馏 Google 工程基因》里说的:把高级工程师的判断力编码成 agent 无法绕过的结构性约束。
internal/jenkinsurl 是第一个,但不是唯一一个。整个 schema 层(internal/schema/、internal/output/)都是用同样的方式推进的——先把 spec scenario 里的字段写成测试断言,再让实现通过。
jk build status -o json " jq 的输出是结果:

每个字段在写实现之前就已经是测试的断言目标。TDD 驱动出来的不只是覆盖率,是 schema 稳定性。
质量门禁不是人来守的,是提前写进 skill 的信号识别逻辑里的。
六、v0.1.0 发布了,archive 还没做
tag v0.1.0 打了,CI 全绿,brew install addozhang/tap/jk 可用——从外面看,这个项目完成了。
openspec/changes/init-jk-jenkins-cli/ 这个 change 还没有 archive。
推迟的原因不是懒,是因为 archive 有一个前提:spec 被验证了。
/opsx-archive 的作用是把 change 里的所有决定——design.md 的 10 个技术判断、7 份 spec 的 scenario 定义——封存进主 spec,成为下一个 change 的基线。封存之后,这些决定就是既成事实——新的 agent 进来,读 spec,知道这些事已经决定了,不需要重新讨论。
这是 spec 的封存,不是功能的完成。
v0.1.0 的实现覆盖了 tasks.md 的 76 个 checkbox,4 个显式留到 v0.2。代码是完整的,但有几条 spec scenario 在真实 Jenkins 环境里还没有跑过——jk build logs -f 的流式输出,在测试环境里 mock 过,但没有对着生产 pipeline 用过。这是第一个要 dogfood 的命令。
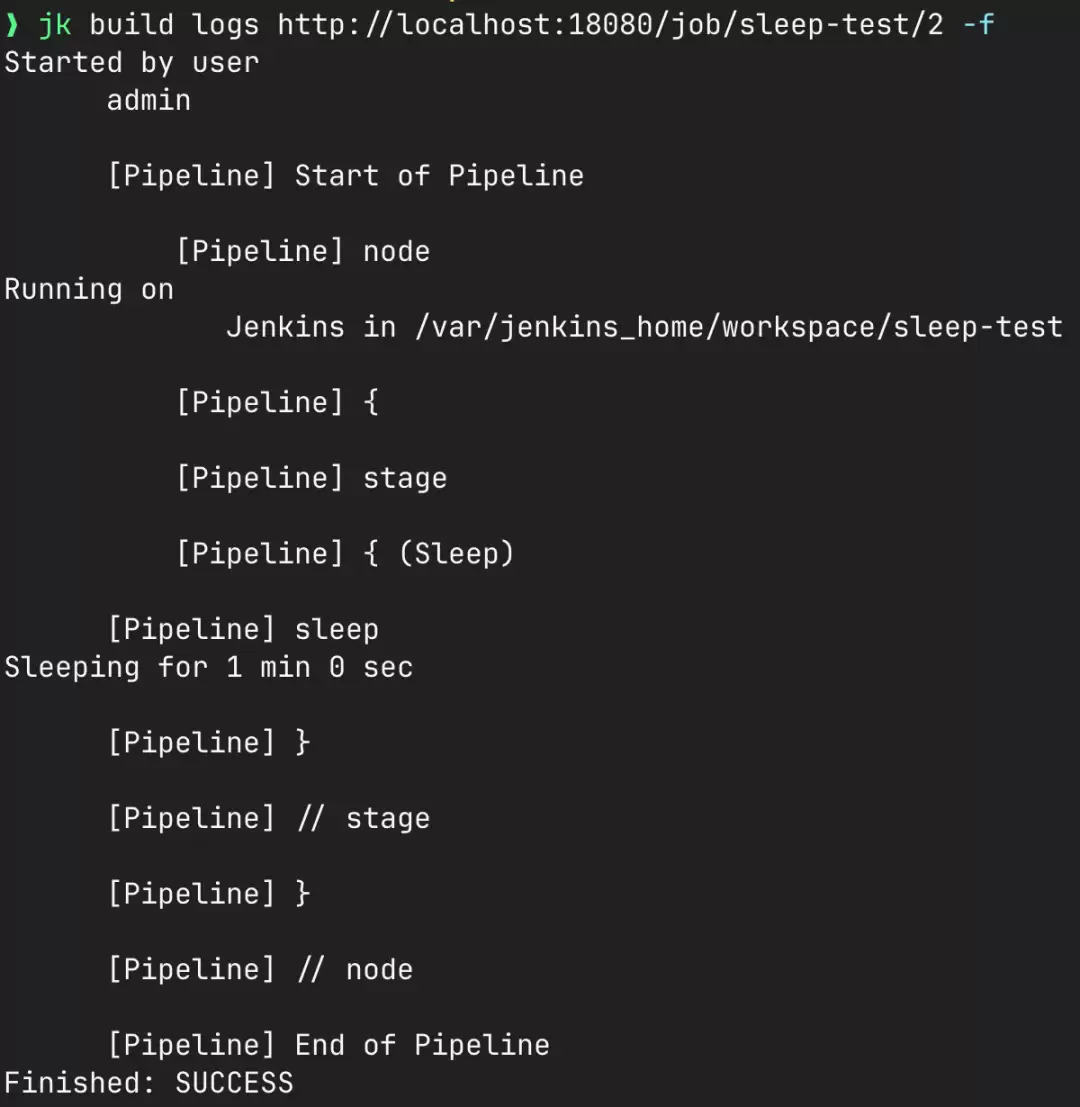
等这条命令在真实环境里稳定跑起来,再开 /opsx-archive。
三条债,这是最后一条还清的时机——不是 tag 打了,而是 spec 的假设被现实确认了。
功能完成和 spec 封存,是两件事。
参考资料
[1] 蒸馏 Google 工程基因: https://github.com/addyosmani/agent-skills
[2] spec-driven-development: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development
[3] OpenSpec: https://openspec.dev/
[4] jk: https://github.com/addozhang/jk
[5] idea-refine: https://github.com/addyosmani/agent-skills/tree/main/skills/idea-refine
[6] OpenSpec: https://openspec.dev/
[7] proposal.md: https://github.com/addozhang/jk/blob/main/openspec/changes/init-jk-jenkins-cli/proposal.md
[8] design.md: https://github.com/addozhang/jk/blob/main/openspec/changes/init-jk-jenkins-cli/design.md
[9] 7 份 specs/*/spec.md: https://github.com/addozhang/jk/tree/main/openspec/changes/init-jk-jenkins-cli/specs
[10] tasks.md: https://github.com/addozhang/jk/blob/main/openspec/changes/init-jk-jenkins-cli/tasks.md
[11] test-driven-development: https://github.com/addyosmani/agent-skills/tree/main/skills/test-driven-development

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI应用层真正赚钱的企业有哪些
AI应用层商业化呈现订阅制、API调用、广告三种模式,Midjourney和Cursor通过订阅制实现盈利,而多数公司因推理成本高导致亏损。2025至2026年处于融资驱动阶段,2027至2028年将转向利润驱动,届时成本下降与付费习惯成熟后赢家才会浮现。

BI公司当下启动全面战略转型
观远数据宣布从数据智能全面转向决策智能,发布DecideX平台,应对大模型对BI行业的冲击。转型面临案例规模化复制、FDE重服务模式能否变轻、自身AI原生转型等挑战,同时布局出海与港股IPO。

边缘人工智能每日早报七月五日最新发布
AI编码能力提升40%但80%内容需人工审核,决策疲劳成新瓶颈;AI漏洞发现速度超越修复能力,6月高危漏洞达1500个创新高;学生使用AI使作业分数升18%但考试成绩降20%;欧盟拟禁16岁以下接触战利品箱,影响280亿美元市场;多模态提示正成为AI智能体新母语。

ARD协议解读:Agent行业拐点已至
谷歌联合微软等发布ARD开放规范,补齐了Agent资源发现的关键拼图,与MCP、A2A构成完整互联体系。加上安全、调度等基础设施加速成熟,Agent规模化落地前提条件已基本齐备,行业正从单体能力竞争转向生态互联,迎来规模化发展的拐点。

ControlNet Mac电脑的详细完整安装教程:Apple Silicon与Intel配置步骤详解
ControlNet是常用AI绘画控制插件,macOS安装需区分AppleSilicon与Intel环境,重点处理Python、WebUI、插件目录、模型文件和启动参数,配置前应做好备份并关注版本兼容。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-05 16:41
2026-07-05 16:41
2026-07-05 16:41
2026-07-05 14:40
2026-07-05 06:45
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
热门教程
2026-07-05 16:41
2026-07-05 16:41
2026-07-05 16:41
2026-07-05 14:40
2026-07-05 06:45
2026-07-05 06:44
2026-07-05 06:44
2026-07-05 06:44
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
