




谷歌Gemini 2.0 Pro多模态编程能力免费开放

谷歌发布Gemini2 0系列,全部免费开放。2 0Pro实验性模型支持200万token上下文,在代码生成和推理上表现突出,获首席科学家JeffDean好评。2 0Flash正式上线,低延迟高性能;2 0Flash-Lite兼具成本效益。所有模型支持多模态输入,免费额度每日最高1500次。
谷歌DeepMind刚刚投下了一枚重磅冲击波——Gemini 2.0系列现已全面开放,而且全部免费。这波更新带来的信息量不小,新模型、新能力,还有那个让Jeff Dean都直呼“震惊”的编程表现。来,我们直接把核心内容拆开看看。
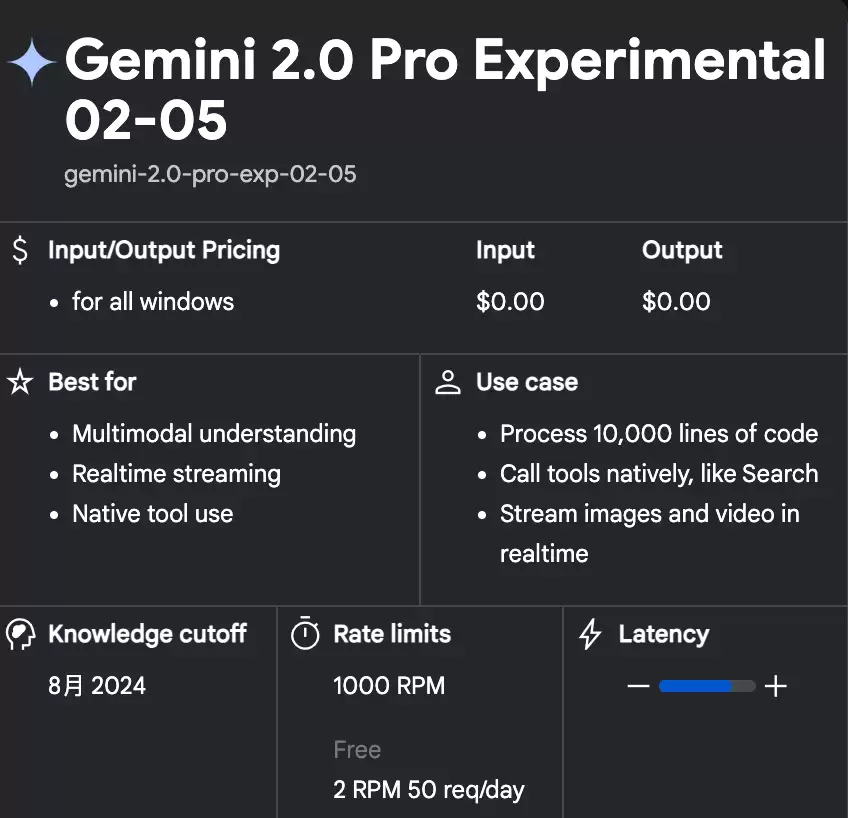
先说说最受关注的Gemini 2.0 Pro。这是个实验性模型,但在代码生成和复杂推理方面表现相当抢眼,支持高达200万个token的上下文窗口——这意味着它能一口气处理海量信息。谷歌首席科学家Jeff Dean亲自下场带货,用一个Boggle填字游戏的例子演示了它的编码能力:只需要一个相对简单的提示,模型就能写出完整的代码,包括所有正确的数据结构和搜索算法,一次性在游戏板上找到所有有效单词。Dean用了"Discombobulating"(令人困惑/震惊)来形容这个表现,作为计算机科学家,他对模型第一次就能把数据结构写对这件事尤其满意。

看得出来,Gemini 2.0 Pro在代码生成这条赛道上,底子相当扎实。
主要亮点:
Gemini 2.0 Flash 正式上线:去年12月还是实验版本的2.0 Flash,现在正式转正了。低延迟、高性能,开发者可以直接通过Google AI Studio和Vertex AI中的Gemini API,把它用到生产级应用里。
Gemini 2.0 Pro Experimental 发布:专为代码性能和复杂提示优化,推理能力强,200万token的上下文窗口摆在那里,处理复杂问题游刃有余。Gemini Advanced用户现在就能在Gemini应用里体验。
Gemini 2.0 Flash-Lite 亮相:2.0系列里最具成本效益的选手。在保持跟1.5 Flash相同速度和成本的前提下,质量明显提升,大部分基准测试已经超越1.5 Flash。同样支持100万token上下文窗口和多模态输入。
2.0 Flash Thinking Experimental 面向Gemini应用用户开放:此前只出现在Google AI Studio里的Thinking模型,现在桌面端和移动端的Gemini用户也能在模型下拉菜单里直接调用了。
多模态能力:所有模型发布时都支持多模态输入(文本输出),未来几个月内会逐步支持更多模态。
模型性能对比:
谷歌给出了一个详细的性能对照表,把Gemini 1.5 Flash、1.5 Pro、2.0 Flash-Lite、2.0 Flash和2.0 Pro Experimental放在一起比了比。几个关键指标值得关注:
| 能力 | 基准测试 | 1.5 Flash | 1.5 Pro | 2.0 Flash-Lite | 2.0 Flash | 2.0 Pro Exp |
| 通用 | MMLU-Pro | 67.3% | 75.8% | 71.6% | 77.6% | 79.1% |
| 代码 | LiveCodeBench (v5) | 30.7% | 34.2% | 28.9% | 34.5% | 36.0% |
| Bird-SQL (Dev) | 45.6% | 54.4% | 57.4% | 58.7% | 59.3% | |
| 推理 | GPQA (diamond) | 51.0% | 59.1% | 51.5% | 60.1% | 64.7% |
| 事实性 | SimpleQA | 8.6% | 24.9% | 21.7% | 29.9% | 44.3% |
| FACTS Grounding | 82.9% | 80.0% | 83.6% | 84.6% | 82.8% | |
| 多语言 | Global MMLU (Lite) | 73.7% | 80.8% | 78.2% | 83.4% | 86.5% |
| 数学 | MATH | 77.9% | 86.5% | 86.8% | 90.9% | 91.8% |
| HiddenMath | 47.2% | 52.0% | 55.3% | 63.5% | 65.2% | |
| 长上下文 | MRCR (1M) | 71.9% | 82.6% | 58.0% | 70.5% | 74.7% |
| 图像 | MMMU | 62.3% | 65.9% | 68.0% | 71.7% | 72.7% |
| 音频 | CoVoST2(21 lang) | 37.4 | 40.1 | 38.4 | 39.0 | 40.6 |
| 视频 | EgoSchema (test) | 66.8% | 71.2% | 67.2% | 71.1% | 71.9% |
从数据来看,2.0 Pro Experimental在大部分基准测试上确实拔得头筹,尤其是推理、事实性和数学能力上优势明显。但2.0 Flash也不弱,在很多项目上已经超过了1.5 Pro,性价比非常突出。
一点个人的判断
这次发布的重点是Gemini 2.0 Pro,但从现有信息来看,它并没有带来那种“碘伏性”的惊喜。跟OpenAI o3 mini high、Claude 3.5 Sonnet、DeepSeek R1这些选手比起来,编程能力到底谁更强,还得等后续实测数据说话。
不过谷歌有一点确实很良心——模型全部免费开放使用。Gemini 2.0 Pro每天有50次提问额度,其他模型更是给到了1500次免费额度。这个力度,在当前的AI模型定价环境下,确实算是诚意满满了。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:谷歌Gemini 2.0 Pro多模态编程能力免费开放要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在近日圆满落幕的亚马逊云科技中国峰会上,国产大模型领域的新锐力量——月之暗面(Moonshot AI)重磅发布了其明星模型Kimi的最新成绩。数据显示,Kimi的海外付费用户数与API调用收入均实现了400%的惊人增长,目前服务已覆盖全球超过200个国家和地区,并深入渗透互联网、金融、制造业、教育、
强制声明5个必填字段 在提示词开头单独写一行,明确告知AI:【所有输出内容必须包含且仅包含以下5个字段:①报告类型|②周期范围(格式:YYYY-MM-DD至YYYY-MM-DD)|③主责人|④核心指标值|⑤结论建议】。不要指望AI能靠“默认规则”或“上下文推测”自动补全——一旦漏掉某个字段,它就会整
项目运行过程中突然出现风场图无法渲染的情况——在全球气象可视化这类应用场景里,最令人头疼的莫过于海外API突发性断连。如果此时人工手动翻阅文档、寻找替代接口、修改代码,往往需要耗费半天时间。豆包专业版的应对策略是主动跳过错误,自动识别数据结构,并匹配国内可用的气象数据源完成渲染。简而言之,它不会被动
快对AI网页版:一款真正用心打磨的智能学习工具平台 近期,快对AI网页版成为众多学生和家长热议的学习利器。大家都渴望找到一款稳定、高效、无需折腾的在线学习工具——最好能打开浏览器直接使用,免下载、免安装客户端,并且真正能起到辅导作用。 快对AI网页版提供了一整套免费的学习服务:覆盖小学到高中、十余门
- 日榜
- 周榜
- 月榜
热点快看