




电脑本地能运行哪些DeepSeek-R1版本

最近DeepSeek-R1的热度持续攀升,很多朋友都在问:我的电脑到底能不能跑得动?又该如何选择适合自己的版本?今天这篇文章就把门槛拆解清楚,一步步带你搞懂。 核心内容: 先搞清楚你的操作系统——Windows和Mac的硬件架构差异非常大 Windows电脑:如何查看显卡显存,以及对应的推荐配置 M
最近DeepSeek-R1的热度持续攀升,很多朋友都在问:我的电脑到底能不能跑得动?又该如何选择适合自己的版本?今天这篇文章就把门槛拆解清楚,一步步带你搞懂。
核心内容:
- 先搞清楚你的操作系统——Windows和Mac的硬件架构差异非常大
- Windows电脑:如何查看显卡显存,以及对应的推荐配置
- Mac电脑:统一内存是什么,不同配置对应的机型怎么选
一、先看看你的电脑配置
动手之前,先确认你用的是Windows还是Mac,这两类设备在硬件结构上完全不同。
Windows电脑:看显卡显存
Windows电脑,关键看独立显卡的显存容量。目前市面上常见的显卡配置大致如下:
入门级显卡:
- RTX 3060:12GB 显存
- RTX 3070:8GB 显存
- RTX 3070 Ti:8GB 显存
中端显卡:
- RTX 3080:10GB 显存
- RTX 3080 Ti:12GB 显存
- RTX 4070:12GB 显存
高端显卡:
- RTX 4080:16GB 显存
- RTX 4090:24GB 显存
如何查看显存:
- 按 Win+R,输入"dxdiag"
- 点击"显示"选项卡
- 查看"显示内存"大小
不过需要留意,Windows电脑实际可用的显存会略小于标称值,因为系统本身也会占用一部分。
Mac:看统一内存
Mac(尤其是搭载Apple Silicon的机型)采用统一内存架构,没有独立的显存概念。需要看整体的内存大小:

入门配置:
- MacBook Air M1/M2:8GB 统一内存
- MacBook Pro M1/M2 (基础版):8GB 统一内存
中端配置:
- MacBook Air M2:16GB/24GB 统一内存
- MacBook Pro M2 Pro:16GB/32GB 统一内存
高端配置:
- MacBook Pro M2 Max:32GB/64GB/96GB 统一内存
- Mac Studio M2 Ultra:64GB/128GB/192GB 统一内存
如何查看内存:
- 点击左上角苹果图标
- 选择"关于本机"
- 点击"更多信息"查看内存大小
二、先聊聊模型"参数"是什么?
在选模型之前,不妨用一个生活中的例子来理解大语言模型里的"参数"。
这就好比你在教一个小孩子认识世界,拿着卡片指着教他:
- 教他认识"猫"——要记住:四条腿、有尾巴、会"喵喵"叫
- 教他认识"狗"——要记住:四条腿、有尾巴、会"汪汪"叫
- 教他认识"鸟"——要记住:两条腿、有翅膀、会飞
每个特征就像模型的一个"参数"。人工智能也是通过这种方式学习的,只不过它需要记住的特征要多得多:
- 1.5B 的模型相当于记住了 15 亿个特征
- 7B 的模型相当于记住了 70 亿个特征
- 70B 的模型则记住了 700 亿个特征!
参数越多,模型就越"聪明",但也需要更多的显存来存储这些"知识"。你想学的东西越多,需要的书本(也就是内存)就越多。
三、DeepSeek-R1 都有哪些版本?
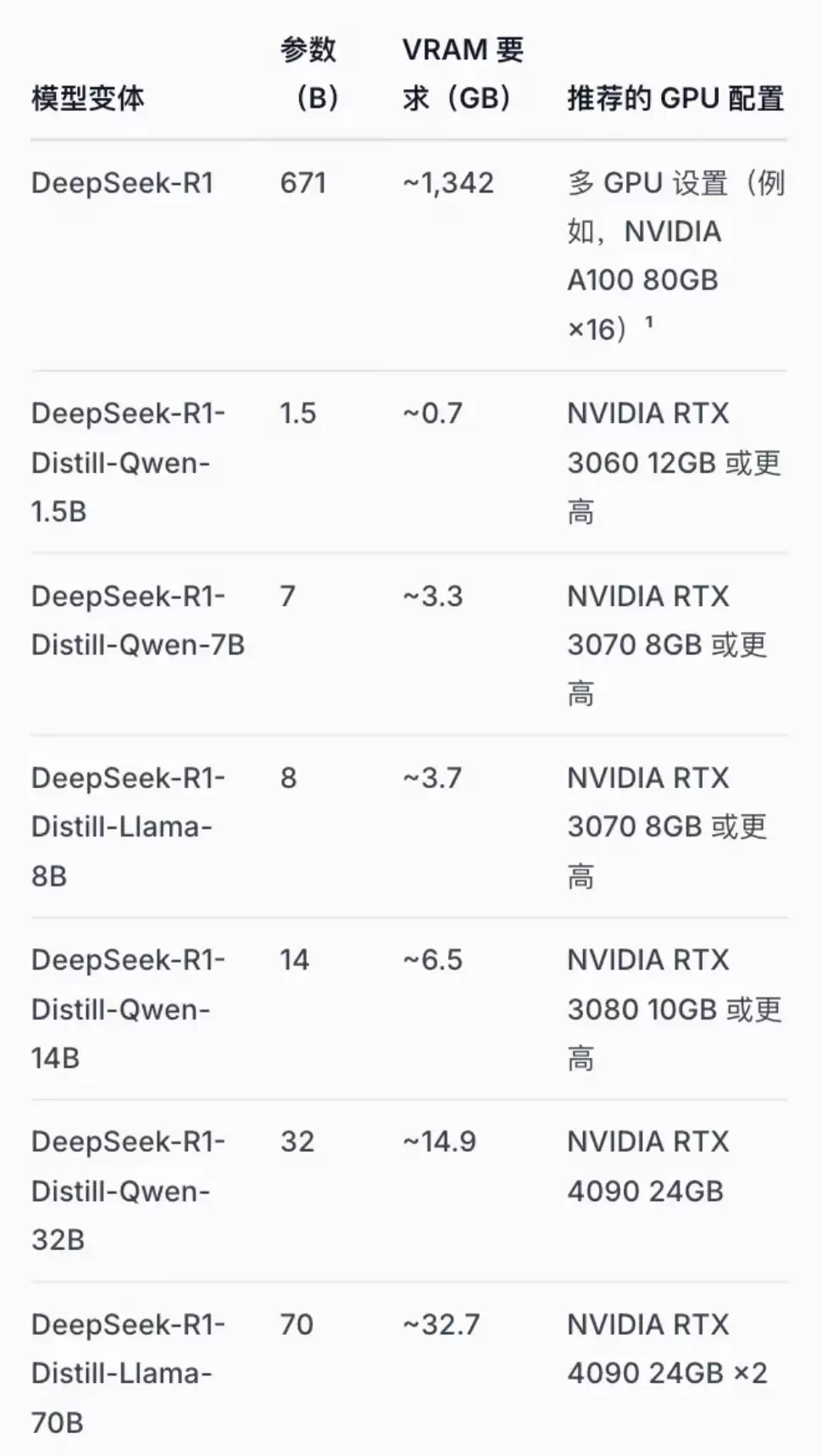
DeepSeek-R1 针对不同的硬件环境,提供了多个版本:
- 轻量版(1.5B - 14B):
DeepSeek-R1-Distill-Qwen-1.5B:最小只需 0.7GB 显存
DeepSeek-R1-Distill-Qwen-7B:需要 3.3GB 显存
DeepSeek-R1-Distill-Qwen-14B:需要 6.5GB 显存 - 中量版(32B - 70B):
DeepSeek-R1-Distill-Qwen-32B:需要 14.9GB 显存
DeepSeek-R1-Distill-Llama-70B:需要 32.7GB 显存 - 完整版(也叫满血版):
DeepSeek-R1:需要高达 1,342GB 显存(这得靠多卡方案来支撑了)
四、量化:让模型"减肥"
如果你觉得显存不够用,别急——还有"量化"这个神奇的技术能让模型"瘦身"。
什么是量化?
其实量化在生活中很常见:比如单反拍的高清照片,可能用了上百万种颜色(甚至更多)。如果把相近的颜色归为一类,比如把所有深蓝色简化为同一种蓝,图片文件体积就会变小,但看起来差别不大。
又比如MP3压缩音乐:无损文件很大,但压成MP3后,虽然丢失了些许细节,普通人几乎听不出差别,文件却小了不少。
再比如手机拍照:选"标准"模式而不是"高清"模式,照片占的空间更少,日常查看时几乎看不出质量差异。
模型的量化也是这个道理:
- 原始模型就像一位艺术家,能分辨出上百种蓝色的细微差别
- 量化后的模型像一位普通画家,只使用十几种蓝色,但画出来的画依然很美
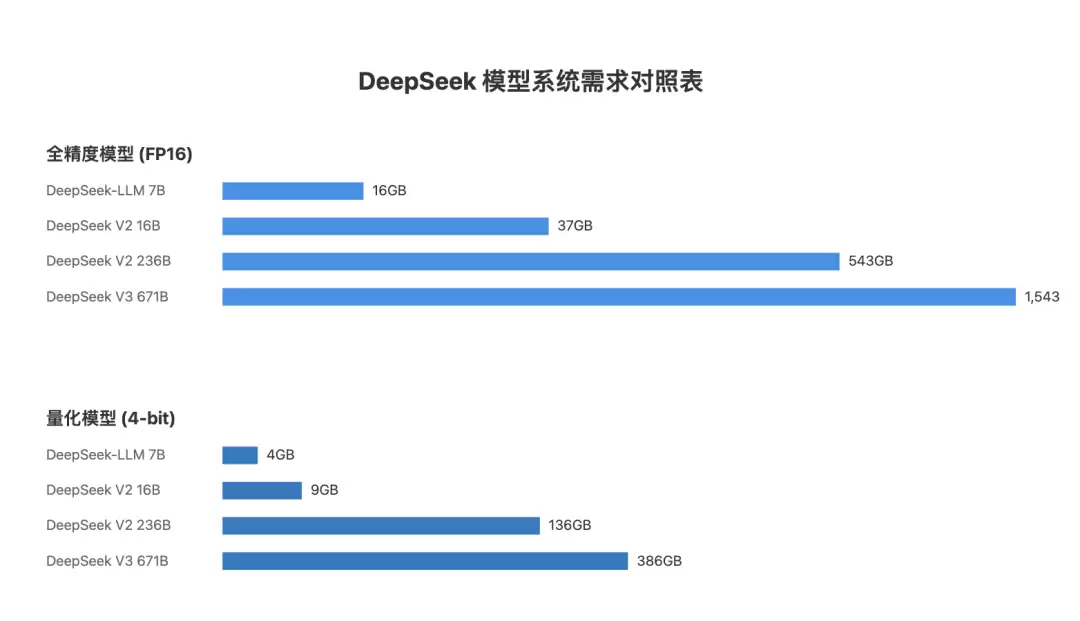
通过量化,可以显著减少模型对显存的需求。来看一个7B模型的例子:
- 原始版本(FP16):需要约 13GB 显存
- 8位量化(INT8):需要约 6.5GB 显存
- 4位量化(INT4):仅需约 3.25GB 显存
说白了,就是能把两居室的家具完美塞进一居室,而且基本保持原有的生活品质。
五、到底选哪个版本?
根据显卡配置,可以这样推荐(实测环境下,4090跑32B模型体验相当顺滑):
- 8GB 显存显卡(如 RTX 3070):
推荐:DeepSeek-R1-Distill-Qwen-7B(4位量化版本)
可以流畅运行基础对话和代码生成任务 - 12GB 显存显卡(如 RTX 3060):
推荐:DeepSeek-R1-Distill-Qwen-14B(4位量化版本)
能处理更复杂的对话和编程任务 - 24GB 显存显卡(如 RTX 4090):
推荐:DeepSeek-R1-Distill-Qwen-32B
可以跑更大的模型,接近完整版的体验
六、实用部署建议
- 建议预留 20-30% 的显存空间,比如有 12GB 显存,最好选需求不超过 8-9GB 的配置
- 对话质量要求高的话,优先选更大的模型;响应速度要求高,可以用量化版本的小模型
当然,上面这些只是理论值。完全可以从较小的模型开始,根据实际效果逐步尝试更大的。遇到显存不足时,试一下量化版本就好。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:电脑本地能运行哪些DeepSeek-R1版本要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看