




什么是机器学习问题 普适逼近定理浅析

普适逼近定理 在机器学习领域,神经网络几乎成了万能工具,处理各类统计学习问题都能交出令人满意的答卷。但你是否曾深入思考:为什么它偏偏比众多其他算法更强大? 答案藏在一个精确的数学原理中。简单来说,神经网络所能描述的函数集极为庞大。但“函数集大小”究竟意味着什么?这个概念乍一听有些抽象,一旦理清,就能
普适逼近定理
在机器学习领域,神经网络几乎成了万能工具,处理各类统计学习问题都能交出令人满意的答卷。但你是否曾深入思考:为什么它偏偏比众多其他算法更强大?
答案藏在一个精确的数学原理中。简单来说,神经网络所能描述的函数集极为庞大。但“函数集大小”究竟意味着什么?这个概念乍一听有些抽象,一旦理清,就能解释为什么某些算法天生比另一些更强。
机器学习作为函数逼近
我们换个抽象视角来理解机器学习问题。假设手头有这样一组数据:
其中 \(x^{(k)}\) 是数据点,\(y\) 是与之对应的观测值。这个观测值可以是实数,也可以是概率分布(比如分类问题)。任务归根结底就是寻找一个函数 \(f(x)\),使得 \(f(x^{(k)})\) 能近似等于 \(y^{(k)}\)。
为此,我们会预先选定一个带参数的功能系列,然后从中挑选最优的参数配置。例如线性回归使用的是这样的函数族:
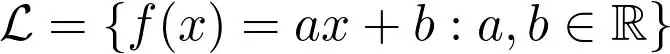
参数就是 \(a\) 和 \(b\)。
如果假设存在一个真实的底层函数 \(g(x)\) 描述了 \(x^{(k)}\) 和 \(y^{(k)}\) 之间的关系,那么问题就转化为函数逼近——一个属于近似理论的美妙领域。
近似理论入门
指数函数你可能见过无数次了。它的定义是:
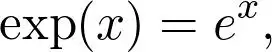
其中 \(e\) 就是著名的欧拉数。这是一个超越函数,意味着你无法通过有限次加法和乘法算出它的精确值。可为什么计算器一按就能出来一个数字?那个数字其实只是个近似值——尽管对我们来说通常够用。实际上,我们有:
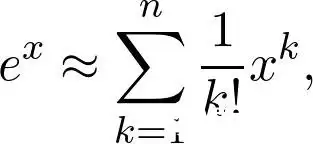
这是一个多项式,可以显式计算。\(n\) 越大,近似值就越接近真实值。
近似理论的核心,就是给这类问题搭建一套数学框架。给你一个函数 \(g(x)\),再给你一组在计算上更易处理的函数族,目标是从中找到一个足够接近 \(g\) 的“简单”函数。本质上,近似理论在回答三个关键问题:
- 什么叫“足够接近”?
- 该用哪个函数族来做近似?
- 给定函数族后,哪个具体函数最合适?
别觉得这些听起来太抽象,接下来我们会具体看神经网络的情况。
神经网络作为函数逼近器
把问题重新表述一下。存在一个函数 \(g(x)\) 描述了数据和观测值的关系,但它并不确切已知,只知道某些点上的值:
其中 \(g(x^{(k)}) = y^{(k)}\)。我们的任务是找到一个 \(f(x)\),既能从数据中泛化出知识,又在计算上可行。
假设所有数据点都落在子集 \(X\) 中:
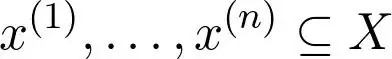
我们希望找一个函数,使得以下上确界范数尽可能小:
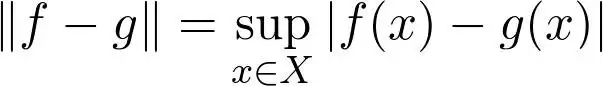
你可以想象把这两个函数画出来,给它们围起来的区域涂上色,然后量一量沿 y 轴方向的最大伸展范围。
即便我们不能在任意点上评估 \(g(x)\),也应该在更广泛的意义上逼近它,而不是只要求 \(f(x)\) 在已知数据点 \(x_k\) 上拟合好。
问题已经摆出来了:到底该用哪一组函数来做近似?
具有单个隐藏层的神经网络
从数学上看,单个隐藏层的神经网络定义为:
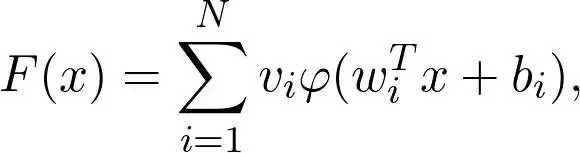
其中 \(\phi\) 是非线性函数(即激活函数),比如 S 型函数:
这里的 \(x\) 对应数据,\(w_i, b_i, v_i\) 是参数。问题来了:这个函数族
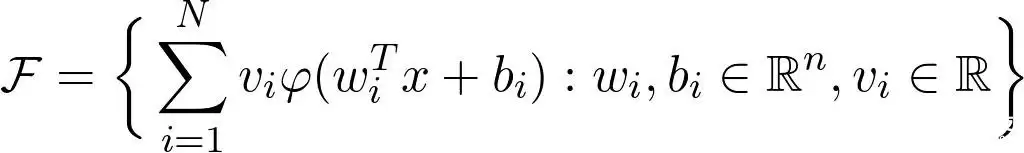
是否足以近似任何合理的函数?答案是肯定的!
普适逼近定理
The universal approximation theorem in its full glory :) Source: Cybenko, G. (1989) "Approximations by superpositions of sigmoidal functions", Mathematics of Control, Signals, and Systems, 2(4), 303–314.
1989 年有一个著名结论,称为通用逼近定理。它指出:只要激活函数是 S 型函数且被逼近的函数是连续的,那么带一个隐藏层的神经网络就能以任意精度逼近该函数(用机器学习的话说,就是能够学习)。
别被定理的数学表述吓到,我们来一步一步拆解(为了更清晰,这里略去了“稠密”之类的概念,精度上可能不够严格,但足以说明思路)。
步骤 1:设要学习的函数 \(g(x)\) 是连续的。固定一个很小的 \(\epsilon\),在函数周围画一条 \(\epsilon\) 宽的“条纹”。\(\epsilon\) 越小,结果越好。
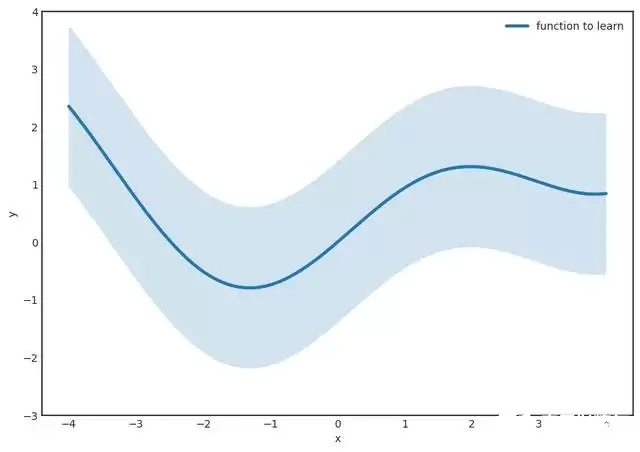
步骤 2(最困难的部分):找到一个形如
的函数,让它完全落在这条条纹之内。定理保证了这样的 \(F(x)\) 一定存在——这个函数族就是所谓的“通用逼近器”。这正是神经网络之所以强大的根本原因。
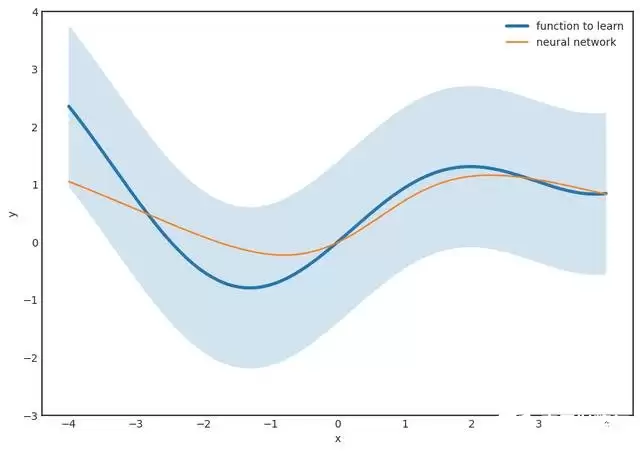
但别高兴得太早,这里有几个陷阱。
首先,定理完全没有告诉你隐藏层神经元的数量 \(N\) 是多少。对于很小的 \(\epsilon\),\(N\) 可能会非常大——计算上可就不好玩了。谁都不想算一个 100 亿项的和。
第二个问题:即便定理保证这样的好函数存在,它也没告诉我们怎么找到它。听起来有点反直觉,但这在数学中很常见:我们有强有力的工具证明某些东西存在,却无法显式构造出来(数学里有一派叫“构造主义”,就拒绝接受纯存在性证明,比如通用逼近定理最初的证明。不过这个问题根深蒂固:不承认非构造性证明,我们甚至没法谈论无穷集上的函数)。
最大的问题还在后面:在实践中,我们永远不可能完全知道底层函数,只能看到观测到的那些点:
有无数种可能的配置都能很好地拟合这些数据点,其中绝大部分对于新数据的泛化能力都惨不忍睹——这就是令人头疼的过拟合。
拥有权利的同时也被赋予了重大的责任
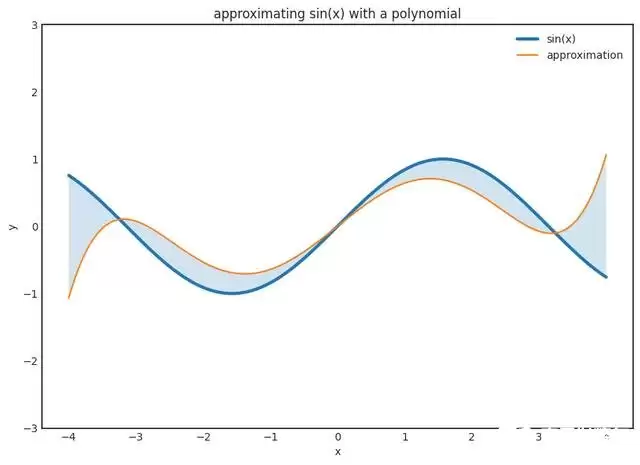
事情是这样的:如果你有 \(N\) 个观测值,你就一定能找到一个 \(N-1\) 阶多项式完美拟合这些观测值。这没什么了不起,你甚至可以用拉格朗日插值把这个多项式显式写出来。然而,它对任何新数据都不会泛化,结果会非常糟糕。下面这张图展示了把高阶多项式套到小数据集上会发生什么:
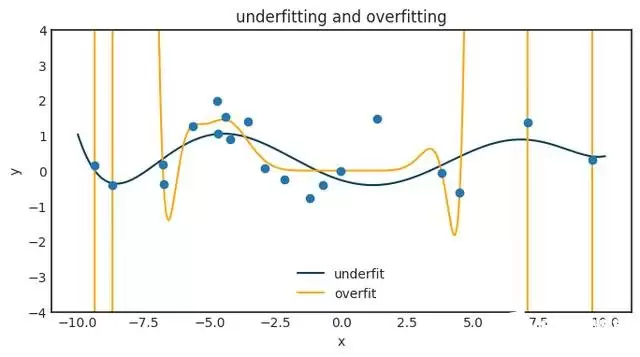
神经网络也逃不过同样的命运。这是一个巨大的问题,而通用逼近定理关于如何解决它,只字未提。
通常情况下,函数族的表现力越强,就越容易过拟合。这叫做偏差-方差权衡。对于神经网络,从权重 L1 正则化到 dropout 层,有很多缓解手段。但因为神经网络的表现力实在太强,这个问题始终像影子一样跟在后面,需要时刻留意。
超越万能逼近定理
正如前面提到的,那个定理并没有提供任何工具来为神经网络寻找具体的参数配置。从实用角度看,这一点几乎和通用逼近性质本身同等重要。神经网络曾经有几十年不受待见,就是因为缺乏计算上有效的方法来拟合它们。后来两大进步让它们重见天日:反向传播和通用 GPU。有了这两个工具,训练庞大的神经网络变得轻而易举——你用笔记本就能训出最先进的模型,毫不费力。相比通用逼近定理的时代,我们已经走了多远!
通常,标准深度学习课程就从这里开始。因为数学上的复杂性,神经网络的理论基础往往被跳过。但通用逼近定理(以及它的证明中使用的工具)为理解神经网络为何如此强大提供了深刻的洞见,甚至为设计新颖的架构奠定了基础。毕竟,谁说我们只能组合 S 型函数和线性函数呢?
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:什么是机器学习问题 普适逼近定理浅析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点与AI高效协作这件事,最近有个挺有意思的切入点——谷歌和瑞士邮政旗下的Digitalidag联合办了一场提示词比赛,让选手们编写指令,比如让AI制定一份详细的学习计划。亚军得主Joakim Jardenberg赛后接受了专访,分享了不少实操心得。下面这几个核心判断,值得每一位与AI共事的人反复琢磨。
物联网已成为继智能手机热潮之后,半导体芯片领域最大的应用增长引擎。根据IDC的市场分析报告,中国物联网市场规模增长潜力巨大,预计2022年将超越美国,成为全球最大的物联网市场,占据世界物联网总规模的四分之一以上。按照这一趋势推算,到2025年中国物联网市场规模至少将达到3918亿美元。物联网的核心应
在生成式AI技术迅猛发展的背景下,Dify作为一款面向开发者的开源大语言模型应用开发平台,正在深刻改变AI应用的构建方式。它诞生于2023年前后,核心目标非常明确:通过低代码化与模块化设计,使开发者无需从零搭建复杂架构,即可快速部署生产级AI应用。随着大语言模型(LLM)技术的普及,Dify逐渐成为
这次咱们来拆解一个实际项目:如何基于 TypeScript 构建一个完整的 MCP 服务器。别担心,整个过程会一步步拆开揉碎了讲,从环境搭建到代码实现,再到集成 Claude Desktop 进行测试,一条龙说清楚。 为了不让这个教程显得太干,我们会用一个非常接地气的场景——**天气查询服务**——
- 日榜
- 周榜
- 月榜
热点快看