




当所有AI都在理解世界时这家公司却更懂你

Clipto AI推出端侧多模态搜索工具,通过本地多模态大模型构建个人记忆层(MemoryLayer),将视频、音频、图片等私有数据转化为可理解结构,实现自然语言精准定位与记忆检索。全程本地运算保障数据安全,旨在弥补AI缺失的用户模型,推动从理解世界到理解个体的基础设施升级。
5月底,一家名为Clipto.AI的初创公司推出了一款端侧产品,随后迅速登顶Product Hunt全球榜单。
这款产品本质上是多模态搜索工具——用户只需用自然语言描述需求,就能在数TB级别的视频、音频、图片和文档中,快速定位到目标信息。
但Clipto的野心,远不止于“搜索”。
过去几年,大模型在生成能力上的跃升有目共睹。AI能写代码、能绘图、能剪辑视频,内容创作效率被推至历史高点。但与此同时,一个更隐蔽的问题浮出水面:人们生产和保存的数据量激增,但真正能再次激活和复用的,却少之又少。
硬盘里堆满了会议录音、直播回放、播客访谈、采访素材、项目文档和截图。对记者、内容创作者、律师、科研人员这类知识型工作者来说,真正消耗精力的往往不是产出内容本身,而是在庞杂资料中来回翻找。
在Clipto创始人康洪文看来,这背后暴露的不是简单的检索瓶颈,而是AI缺失了一层关键基础设施——他称之为Memory Layer(记忆层)。
AI在不断构建世界模型,却始终缺乏用户模型;智能体(Agent)的能力日益强大,但因为缺乏记忆支撑,很难真正理解个体用户。
而从视频理解研究起步,到投身AIGC创业,再到如今全力押注AI记忆层,康洪文近二十年的职业轨迹,恰好暗合了AI技术演进的一条深层脉络:从「理解内容」,到「生成内容」,再到「组织内容」。
## 01
## 从搜索工具到记忆层:
## Clipto 想解决什么问题?
在康洪文的定义里,Clipto并不是传统意义上的多模态搜索工具,而是连接个人数据与智能体生态的「记忆层」。
「过去十年,AI一直在构建世界模型,却长期缺失用户模型。每个人的数据散落在本地设备中,尚未转化为AI可持续理解与调用的个人上下文。」他指出了行业中的一个空白,「没有长期记忆,再强大的Agent也无法真正读懂用户。搜索只是起点,Clipto的终极目标,是补上AI时代所缺的那层记忆基础设施。」
Clipto给出的技术路径,是一套完全运行于本地的多模态记忆构建系统:用户将本地视频、音频、图片、文档等多模态数据导入后,系统依托设备内置AI算力与自研端侧多模态大模型,完成感知理解、结构化解析与向量化建模,最终构建起具备认知图谱、支持时空对齐的个人记忆体系。
实际使用时,用户只需用自然语言描述需求,端侧大模型就会立刻解析查询意图与上下文,再由本地搜索Agent在数秒内完成精准匹配——无论是特定人物出镜、某段对话、某个场景,还是完整事件片段,都能直接定位到对应文件及精确时间戳。
更进一步,Clipto真正打通了底层大模型与上层Agent之间长期割裂的记忆通路。在TB级私有数据基础上,用户可以直接以对话形式提问,让AI回答所有与本地记忆相关的问题,也可以基于已有内容自动生成摘要、提炼要点或梳理逻辑脉络。
而所有运算与处理,全程都在用户本地设备完成。一方面避免了海量数据上传和云端模型调用带来的高昂Token成本;另一方面,对于含商业机密、敏感信息的工作素材,以及移动办公、离线环境等特殊场景,“数据不出设备”本身就是一条不可妥协的安全底线。
康洪文认为,传统软件主要解决的是「存储」问题,却从未真正「理解」内容。Clipto的核心价值,在于利用本地多模态模型,把视频、音频、图片和文档转化为AI可读、可推理、可关联的数据结构,使用户从“搜索文件”,跃迁为“搜索记忆”。
在他看来,搜索只是入口,真正的关键在于建立一套可持续沉淀、不断演化的个人上下文体系——Memory Layer。过去十年,AI构建的是关于世界的通用知识库;未来十年,AI必须深入理解每个用户的个体经验与专属知识。
## 02
## 二十年:从视频理解到视频生成
从职业履历来看,康洪文几乎全程参与并亲历了过去二十年AI从学术研究走向产业落地的关键节点。
2004年,他进入微软亚洲研究院实习。彼时深度学习尚未兴起,AI多数还停留在实验室课题阶段。
他参与的早期项目之一,是为Xbox设计自动分析系统,帮助用户从大量家庭照片与视频中识别关键画面,再自动生成家庭纪念短片。
今天看来已是常规功能,但在当时,这项任务已经触及计算机视觉最本质的挑战:机器必须先“看懂”内容,才能“生成”内容。需要识别出谁在画面中、发生了什么、哪些帧具有语义重要性、哪些可以被忽略。
此后,康洪文赴卡内基梅隆大学攻读博士,师从计算机视觉泰斗Takeo Kanade。
在那里,他持续深耕图像与视频理解,致力于让机器人通过长期视觉经验积累,逐步建立对现实世界的认知。
在多数人眼中,视频只是连续帧的集合;但康洪文深知,视频本质上是一种融合时间、人物、事件与关系的复杂信息结构。理解视频,某种程度上就是在理解世界本身。
2017年,他创立慧川智能,并推出文字生成视频平台“智影”。此时正值移动互联网与短视频爆发期,大量创作者涌入内容生态。
一个新的矛盾随之浮现:过去的问题是机器看不懂内容;如今的问题是内容生产效率太低。
于是,他的技术重心开始从“理解”延伸至“生成”——文字生成视频、智能剪辑、数字人驱动……这些后来成为AIGC主流赛道的能力,早在智影的产品探索中就已落地实践。
2020年底,智影被腾讯收购。康洪文加入腾讯,主导腾讯智影团队,持续推进文生图、文生视频、数字人等全栈AIGC技术研发。
如果按既有路径发展,他本可以继续在生成式AI领域深耕。但真正触发其思维转向的,恰恰是生成能力的井喷式爆发。
当内容生产变得越来越容易时,一个更隐蔽的瓶颈浮现出来:信息过载。人们积累了海量视频、录音与文档,却越来越难找回真正需要的信息。AI解决了“创造”的难题,却没能破解“理解个人内容”的困局。当记录成本趋近于零,检索与组织反而成了最大的障碍。
这让他意识到:行业可能忽略了一个更基础的命题。
理解是生成的前提,而记忆,是理解之后的必然延伸。AI的下一程,或许正是“记忆”。
## 03
## AI 的下一层竞争,
## 为什么会是 Memory?
在康洪文看来,Agent若想真正走向成熟,必须先跨越一道门槛——记忆。
当前的大模型已经足够强大:写代码、做推理、生成报告,甚至能代用户执行部分工作流。但无论模型多先进,它始终有一个天然缺陷:不了解用户。
每一次打开新的AI应用,都像在跟一位健忘者重新相识——你得反复介绍自己是谁、正在做什么、过往做过什么;一旦对话结束,所有上下文即刻清空。
康洪文指出,整个AI基础设施缺失的,正是一层关键能力:用户模型。
今天的大模型坐拥全网公开知识,却无法真正理解一个具体的人。因为关于这个人的数据,不在互联网上,而在电脑、手机、NAS、网盘、相机、会议记录、本地笔记等私有设备中。
对AI来说,这些数据近乎“不可见”。而随着Agent进入规模化应用,这个问题将变得越来越严峻。
当下热议Agent,焦点大多集中在“能帮用户做什么”。但如果未来真有数百万乃至数亿个Agent普及开来,新问题就会接踵而至:它们如何理解用户?如何知晓用户的历史行为?又如何共享同一套个性化上下文?
康洪文认为,不可能也不应该让每个Agent都独立重建一套用户记忆。更合理的架构,是存在一个统一、独立、可复用的Memory Layer。
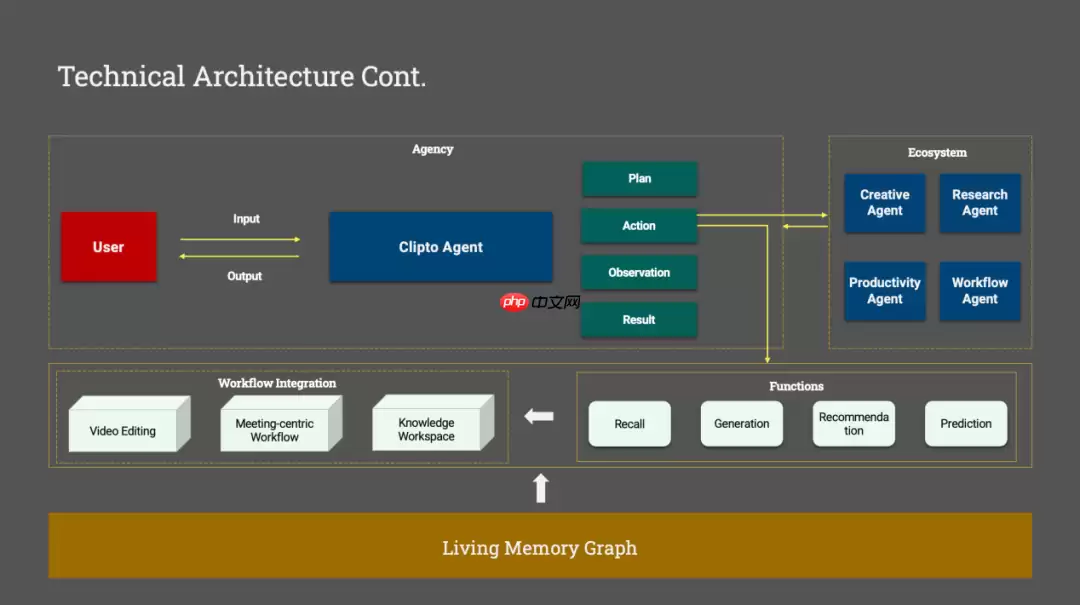 Living Memory Graph
Agent专注任务执行,Memory Layer专司记忆管理,所有Agent都可以基于同一套记忆系统理解用户。
这有点像互联网时代的操作系统:应用层出不穷,但底层文件系统始终唯一。
今天的Agent生态,同样需要这样一套公共记忆基础设施。而这,正是Clipto力图扮演的角色。
在康洪文的判断中,未来AI架构可能会形成双层基础设施:一层是Intelligence Layer(智能层),负责理解世界,由云端大模型提供通用知识;另一层是Memory Layer(记忆层),负责沉淀用户的个人知识、上下文与长期记忆,扎根于用户持续产生的私有数据之上。
二者协同,才构成真正意义上的Personal AI。因此,他并不认同“所有AI能力终将上云”的单一叙事。
过去几年,行业焦点几乎全部集中在云端大模型战场:OpenAI、Google、Anthropic,以及国内各大模型厂商,比拼的核心始终是模型性能。
但另一股趋势也在悄然成型:Apple M系列芯片持续强化神经网络算力,NVIDIA推动AI PC概念落地,微软发布Copilot+ PC。越来越多计算能力正回归终端设备。
AI的计算范式正在重构:过去,AI主要依赖云端;未来,随着个人数据价值凸显,与记忆强相关的功能将更多运行于本地,而通用推理与世界知识仍将持续受益于云端大模型。
原因很简单:用户最核心的数据,本来就存在于本地——采访纪要、合同文本、财务报表、创意素材、家庭影像……这些内容既不宜频繁上传,也难以完全交由云端处理。
更重要的是,数据规模本身正在指数级膨胀。影视团队单个项目动辄产生数十TB甚至上百TB视频素材;媒体机构数年积累,也能形成海量内容资产。
在这种背景下,云端未必是最优解。本地理解、本地索引、本地推理,反而重新获得了战略价值。
不过,康洪文强调,Memory Layer并非走向“纯本地AI”,而将是云端与本地协同的混合体系。
因为记忆 ≠ 存储。真正关键的是组织、关联与调用。用户的数据天然分散于不同终端与平台:电脑存文档,手机存照片与视频,云盘存备份资料……
未来的记忆系统,必须将这些割裂的数据重新缝合,最终构建出一张可供AI理解、查询与调用的个人知识网络。
而这,也正是康洪文二十年思考不断演进的结果:在微软亚研院,他探索机器如何“看懂”视频;在智影时期,他推动机器如何“生成”内容;而今,他追问的是:当AI已能理解与生成内容之后,谁来负责“组织”内容?
Living Memory Graph
Agent专注任务执行,Memory Layer专司记忆管理,所有Agent都可以基于同一套记忆系统理解用户。
这有点像互联网时代的操作系统:应用层出不穷,但底层文件系统始终唯一。
今天的Agent生态,同样需要这样一套公共记忆基础设施。而这,正是Clipto力图扮演的角色。
在康洪文的判断中,未来AI架构可能会形成双层基础设施:一层是Intelligence Layer(智能层),负责理解世界,由云端大模型提供通用知识;另一层是Memory Layer(记忆层),负责沉淀用户的个人知识、上下文与长期记忆,扎根于用户持续产生的私有数据之上。
二者协同,才构成真正意义上的Personal AI。因此,他并不认同“所有AI能力终将上云”的单一叙事。
过去几年,行业焦点几乎全部集中在云端大模型战场:OpenAI、Google、Anthropic,以及国内各大模型厂商,比拼的核心始终是模型性能。
但另一股趋势也在悄然成型:Apple M系列芯片持续强化神经网络算力,NVIDIA推动AI PC概念落地,微软发布Copilot+ PC。越来越多计算能力正回归终端设备。
AI的计算范式正在重构:过去,AI主要依赖云端;未来,随着个人数据价值凸显,与记忆强相关的功能将更多运行于本地,而通用推理与世界知识仍将持续受益于云端大模型。
原因很简单:用户最核心的数据,本来就存在于本地——采访纪要、合同文本、财务报表、创意素材、家庭影像……这些内容既不宜频繁上传,也难以完全交由云端处理。
更重要的是,数据规模本身正在指数级膨胀。影视团队单个项目动辄产生数十TB甚至上百TB视频素材;媒体机构数年积累,也能形成海量内容资产。
在这种背景下,云端未必是最优解。本地理解、本地索引、本地推理,反而重新获得了战略价值。
不过,康洪文强调,Memory Layer并非走向“纯本地AI”,而将是云端与本地协同的混合体系。
因为记忆 ≠ 存储。真正关键的是组织、关联与调用。用户的数据天然分散于不同终端与平台:电脑存文档,手机存照片与视频,云盘存备份资料……
未来的记忆系统,必须将这些割裂的数据重新缝合,最终构建出一张可供AI理解、查询与调用的个人知识网络。
而这,也正是康洪文二十年思考不断演进的结果:在微软亚研院,他探索机器如何“看懂”视频;在智影时期,他推动机器如何“生成”内容;而今,他追问的是:当AI已能理解与生成内容之后,谁来负责“组织”内容?
来源:https://www.php.cn/faq/2748024.html?uid=1246273
Living Memory Graph
Agent专注任务执行,Memory Layer专司记忆管理,所有Agent都可以基于同一套记忆系统理解用户。
这有点像互联网时代的操作系统:应用层出不穷,但底层文件系统始终唯一。
今天的Agent生态,同样需要这样一套公共记忆基础设施。而这,正是Clipto力图扮演的角色。
在康洪文的判断中,未来AI架构可能会形成双层基础设施:一层是Intelligence Layer(智能层),负责理解世界,由云端大模型提供通用知识;另一层是Memory Layer(记忆层),负责沉淀用户的个人知识、上下文与长期记忆,扎根于用户持续产生的私有数据之上。
二者协同,才构成真正意义上的Personal AI。因此,他并不认同“所有AI能力终将上云”的单一叙事。
过去几年,行业焦点几乎全部集中在云端大模型战场:OpenAI、Google、Anthropic,以及国内各大模型厂商,比拼的核心始终是模型性能。
但另一股趋势也在悄然成型:Apple M系列芯片持续强化神经网络算力,NVIDIA推动AI PC概念落地,微软发布Copilot+ PC。越来越多计算能力正回归终端设备。
AI的计算范式正在重构:过去,AI主要依赖云端;未来,随着个人数据价值凸显,与记忆强相关的功能将更多运行于本地,而通用推理与世界知识仍将持续受益于云端大模型。
原因很简单:用户最核心的数据,本来就存在于本地——采访纪要、合同文本、财务报表、创意素材、家庭影像……这些内容既不宜频繁上传,也难以完全交由云端处理。
更重要的是,数据规模本身正在指数级膨胀。影视团队单个项目动辄产生数十TB甚至上百TB视频素材;媒体机构数年积累,也能形成海量内容资产。
在这种背景下,云端未必是最优解。本地理解、本地索引、本地推理,反而重新获得了战略价值。
不过,康洪文强调,Memory Layer并非走向“纯本地AI”,而将是云端与本地协同的混合体系。
因为记忆 ≠ 存储。真正关键的是组织、关联与调用。用户的数据天然分散于不同终端与平台:电脑存文档,手机存照片与视频,云盘存备份资料……
未来的记忆系统,必须将这些割裂的数据重新缝合,最终构建出一张可供AI理解、查询与调用的个人知识网络。
而这,也正是康洪文二十年思考不断演进的结果:在微软亚研院,他探索机器如何“看懂”视频;在智影时期,他推动机器如何“生成”内容;而今,他追问的是:当AI已能理解与生成内容之后,谁来负责“组织”内容?
热点追踪提示词
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:当所有AI都在理解世界时这家公司却更懂你要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点AI热点2026-07-01 16:59
种神经网络最多可检测1000种物体的特斯特自动驾驶技术
特斯拉推送2020 12版自动驾驶软件,新增交通信号灯和停车标志识别功能。通过影子模式收集超30亿英里驾驶数据训练算法,其HydraNet包含48个神经网络可检测1000种物体,并能将二维图像还原为三维场景,实现更可靠的自动驾驶。
AI热点2026-07-01 16:59
机器学习应用于异常检测的常见问题解析
离群点可能正常,异常由不同过程产生。异常检测应用于制药、处方监控、临床试验。生成对抗网络识别高维非结构化异常,主成分分析处理相关变量,循环神经网络与隔离森林用于网络活动,自编码器通过重构误差发现新模式。
AI热点2026-07-01 16:59
人工智能本地部署Ollama是什么及使用教程详解
Ollama是一个开源工具,简化了deepseek-r1等大语言模型的本地部署、下载与管理流程,支持Windows和Linux系统,通过简单命令即可运行。安装时需注意显卡驱动配置及11434端口安全,推荐先用1 5b轻量模型体验。
AI热点2026-07-01 16:59
人工智能将如何深刻改变人类的法律体系
人工智能将深刻改变法律体系。机器人法官可消除偏见、提升效率,实现法律面前人人平等。同时,法律内容需快速更新以适应技术进步,并平衡隐私保护与司法公正的关系。
- 日榜
- 周榜
- 月榜
热点快看