




本体与AI驱动的智能体工厂从设计到实现

深入探索AI智能体工厂的完整实现路径:从业务需求到智能体交付,实现五阶段自动化转化。核心要点:1 平台以本体模型为核心枢纽,打通从原始需求到智能体的完整链路2 两大子应用协同配合,实现“文档化、模型化、代码化、技能化、Agent化”3 底层以LLM作为推理引擎,有效破解传统软件交付的三大痛点
深入探索AI智能体工厂的完整实现路径:从业务需求到智能体交付,实现五阶段自动化转化。
核心要点:
1. 平台以本体模型为核心枢纽,打通从原始需求到智能体的完整链路
2. 两大子应用协同配合,实现“文档化、模型化、代码化、技能化、Agent化”
3. 底层以LLM作为推理引擎,有效破解传统软件交付的三大痛点
本文系统分享了一个基于本体模型与AI大模型驱动的端到端AI智能体交付平台,涵盖需求分析、整体架构设计及核心功能实现,供广大开发者和技术决策者参考。
摘要:本文介绍一个完整的“AI智能体工厂”平台的设计思路与实现方案。该平台以本体模型(Ontology Model)作为中间表示层,打通了从原始业务需求到可运行AI智能体的完整链路:需求探索 → 本体建模 → 可视化验证 → 能力代码生成 → 技能封装 → Agent动态发布。平台由两个协同工作的子应用构成——OntoReq(智能体工厂)和 Code-Chat(智能体运行商店),底层以大语言模型(DeepSeek)作为核心推理引擎,实现了“需求文档化、文档模型化、模型代码化、代码技能化、技能Agent化”的五阶段转化。
一、需求背景与场景分析
1.1 传统软件交付的困境
在企业级软件开发过程中,从业务需求到可运行系统之间存在一条漫长且复杂的转化链条:业务人员提出原始需求,需求分析师撰写文档,架构师进行系统设计,开发人员编码实现,测试人员反复验证,最终交付上线。这一流程中普遍存在三个核心痛点:
信息衰减:每一次转化环节都伴随着信息丢失与理解偏差。业务人员脑海中完整的业务图景,经过文档、设计、代码的层层转译后,最终交付的系统往往与原始期望存在较大出入。
交付周期长:各环节严重依赖人工操作,需求文档、设计文档、接口文档的编写与维护成本居高不下,任何需求变更都会引发连锁修改,拖慢整体进度。
语义断层:需求文档采用自然语言描述业务,设计文档借助UML表达结构,代码则用编程语言实现逻辑——三者之间缺乏形式化的语义连接,导致需求可追溯性差、系统一致性难以保障。
1.2 为什么选择本体作为中间表示
本体(Ontology)源自哲学中研究“存在”的学科,在计算机科学领域,本体是对某一领域中的概念及其关系的形式化规范描述。选择本体作为AI智能体工厂的核心中间表示,主要基于以下关键判断:
- 语义完备性:本体不仅描述“有什么数据”(对象),还涵盖“能做什么”(行为)、“为什么这样做”(规则)、“在什么情况下触发”(事件与场景)、“谁来做”(主体)。相比传统的ER图或UML类图,本体的语义表达更为丰富完整。
- 人机共读:本体模型采用YAML结构化描述,既便于业务人员理解,也能被机器精确解析并被代码生成器直接消费。
- AI友好:大语言模型天然擅长理解和生成结构化文本。将本体模型作为Prompt的上下文注入,可以让AI获得对业务领域的“完整理解”,而不仅仅是数据库Schema层面的认知。
- 可追溯性:每一行生成的代码、每一个API接口、每一个数据库字段,都可以回溯到具体的本体模型元素,形成完整的“需求→模型→代码”追溯链条。
1.3 平台的愿景
我们设想的最终形态是:业务人员只需提供一段原始需求描述,平台在AI驱动下自动完成需求探索与确认,生成形式化的本体模型,基于模型自动生成数据库、API和业务逻辑代码,封装为语义完整的技能包,并最终发布为一个能够通过自然语言对话交互的AI智能体——整个过程在人工引导下有序推进,但大幅降低了对专业开发人员的依赖。
二、整体设计

2.1 系统分层架构
平台采用六层架构设计,各层职责清晰、单向依赖。完整的架构图见随文SVG文件 architecture-diagram.svg,其核心分层如下:
| 层序 | 层名 | 核心职责 | 关键技术 |
|---|---|---|---|
| L1 | 用户交互层 | 需求探索对话、本体可视化、智能体对话 | React 18, ECharts, Mermaid, AntV X6 |
| L2 | 应用服务层 | 对话管理、代码生成API、Agent编排 | Flask (OntoReq), FastAPI (Code-Chat) |
| L3 | AI智能编排层 | Prompt构建、LLM调用、工具编排、安全管控 | DeepSeek API, Function Calling, SSE |
| L4 | 核心引擎层 | 文档生成、本体生成、表生成、API生成、技能生成、Agent引擎 | Python核心引擎 |
| L5 | 本体模型层 | M1-M7+ME八大模型的YAML定义和持久化 | YAML, 本体建模规范 |
| L6 | 数据持久层 | 业务数据库、模型库、技能包文件系统 | SQLite, Markdown, YAML |
2.2 八大本体模型体系
本体模型层是整个平台的“灵魂”。我们定义了一套完整的八模型体系(实际实现聚焦M1-M5+ME六个核心模型),每个模型负责一个正交的建模维度:
| 编号 | 模型名称 | 核心建模内容 | 对下游的影响 |
|---|---|---|---|
| M1 | 对象模型 | 聚合根、实体、值对象、属性、聚合间关联、不变性约束 | 生成数据库表结构(DDL) |
| M2 | 行为模型 | 原子行为方法、触发条件、前置/后置约束、输入输出 | 生成行为API接口 |
| M3 | 规则模型 | 校验规则、计算规则、推导规则(可复用) | 生成规则API和校验逻辑 |
| ME | 事件模型 | 事件定义、事件生产者、事件订阅者、事件链 | 事件驱动架构的基础 |
| M4 | 场景模型 | 端到端业务流程、用例组装(行为+事件编排) | 生成BPMN流程图和场景API |
| M5 | 主体模型 | 角色、权限、数据范围控制、行为授权 | 生成权限控制逻辑 |
| M6 | 异常补偿模型 | 失败分类、补偿策略、Saga协调 | 分布式事务补偿 |
| M7 | 质量约束模型 | 性能SLA、并发策略、可靠性要求 | 非功能约束标注 |
各模型之间的依赖关系遵循严格的设计原则:对象模型是最底层的基础,行为模型依赖于对象和规则,场景模型依赖于行为和事件,主体模型横切所有模型提供权限语义。事件模型被独立提升为“一等公民”,通过producerBeha viorRef和subscriberBeha viorRefs建立与行为的松耦合引用关系,天然支持事件驱动架构(EDA)。
M1对象模型吸收了领域驱动设计(DDD)的聚合思想,将业务对象划分为聚合根(Aggregate Root)、实体(Entity)和值对象(Value Object)三个层次。聚合之间通过ID引用而非对象引用,从而保证聚合边界的清晰性和事务的隔离性。以下是一个典型的合同管理M1模型YAML片段:
aggregates:
-id:Contract
name:合同
alias:Contract
aggregateType:AGGREGATE_ROOT
lifecycle:[草稿,审批中,生效中,已关闭,已作废]
attributes:
-name:contractId
label:合同编号
type:String
required:true
unique:true
-name:totalAmount
label:合同总金额
type:Money
required:true
entities:
-name:付款条款
alias:PaymentTerm
cardinality:ONE_OR_MORE
attributes:
-name:termPhase
label:付款阶段
type:String
-name:termAmount
label:阶段金额
type:Money
invariants:
-name:金额一致性
expression:"sum(PaymentTerm.termAmount) == totalAmount"
violationMessage:"付款条款金额合计必须等于合同总金额"
2.3 两个子应用的职责分工
整个平台由两个独立但协同的应用构成,形成“工厂-商店”的架构模式:
OntoReq(智能体工厂) — 负责“制造”智能体。提供需求探索的AI交互界面、本体模型的可视化编辑器、代码生成的触发与管理、技能包的自动打包。它是平台的前半段链路:需求 → 模型 → 代码 → 技能包。
Code-Chat(智能体商店) — 负责“运行”智能体。通过Skill Manifest文件动态加载技能包,将技能包中的知识(领域概要、业务规则)、能力(可用API列表)和数据白名单注入AI的系统提示词,为用户提供自然语言对话服务。它是平台的后半段链路:技能包 → Agent → 对话。
两者的“契约”是技能包(Skill Package)——OntoReq生成技能包,Code-Chat加载并运行技能包。这种松耦合的设计意味着:技能包可以独立进行版本管理、独立升级,甚至可以由第三方工具生成。
2.4 端到端流水线设计
整个平台的端到端数据流如下:
原始需求描述(一句话/一段话)
│
▼
[AI需求探索] ── 四阶段引导式交互 ──→ 完整需求文档(Markdown, ~3000-8000字)
│
▼
[本体模型生成] ── 6个DeepSeek API调用 ──→ M1-M5+ME YAML模型文件
│
├──→ [本体可视化] ── 树状浏览 / 知识图谱 / ER图 / BPMN流程图
│
└──→ [能力代码生成]
├── M1 对象模型 → Table Generator → DDL + 字段元数据
├── M2 行为模型 → Beha vior API Generator → RESTful API
└── M3 规则模型 → Rule API Generator → 规则引擎接口
│
▼
[技能封装] ── 聚合模型+表+API ──→ 技能包(7个文件, Markdown+YAML)
│
▼
[Agent发布] ── 技能包加载 + Prompt注入 ──→ AI对话智能体
流水线的每一步都可以独立触发和重新生成。当需求文档发生变化时,用户可以重新生成下游的本体模型和代码,平台通过前序模型上下文注入保证各模型间的一致性。
三、核心功能实现

3.1 需求探索:AI引导的四阶段交互
需求探索环节是整个平台的起点。我们设计了一套完整的“AI需求分析师”提示词系统,让大语言模型扮演资深需求分析师的⻆色,基于原始业务需求,通过四阶段结构化对话,逐步引导用户完善需求。
核心设计理念:AI自主补全它能推断的通用知识,仅在企业特有的业务信息上向用户提问。具体来说,需求中的每一项信息被分为两类:A类(AI可基于行业惯例自主补全的内容,如标准业务属性、常见校验规则)和B类(必须向用户确认的内容,如审批流设置、级联删除策略、具体金额口径)。A类内容AI直接给出建议并标注“系统自动补全,请确认”,B类内容以结构化选项的方式分批提问。
四阶段推进流程:
- 阶段零:总体理解确认 — AI复述对业务范围的理解,列出初步的业务域、核心对象和流程清单,请求用户确认整体范围。
- 阶段一:业务对象探索 — 逐个给出业务对象的草拟内容(分类、属性、关联),标注AI自动补全,针对父子/引用关系的数据命运和特殊业务口径提问。
- 阶段二:业务功能与规则探索 — 草拟每个业务功能的完整描述(操作角色、前置条件、操作步骤、后置变更、下游触发),对同步/异步触发方式和企业自定义规则数值提问。
- 阶段三:场景与流程探索 — 串联端到端流程并生成Mermaid流程图,逐一确认核心单据是否需要审批及审批节点设置。
- 阶段四:岗位角色探索 — 汇总所有操作角色,构建功能权限矩阵,逐功能确认各角色的数据查看范围。
整个对话过程中,所有结论实时落地为需求文档草稿,每个内容标注来源标记([AI自动补全]/[已确认]/[待确认])。只有所有B类问题都已确认、文档满足完整性自检清单后,才能进入下一个本体建模阶段。
3.2 本体模型生成:顺序生成与上下文注入
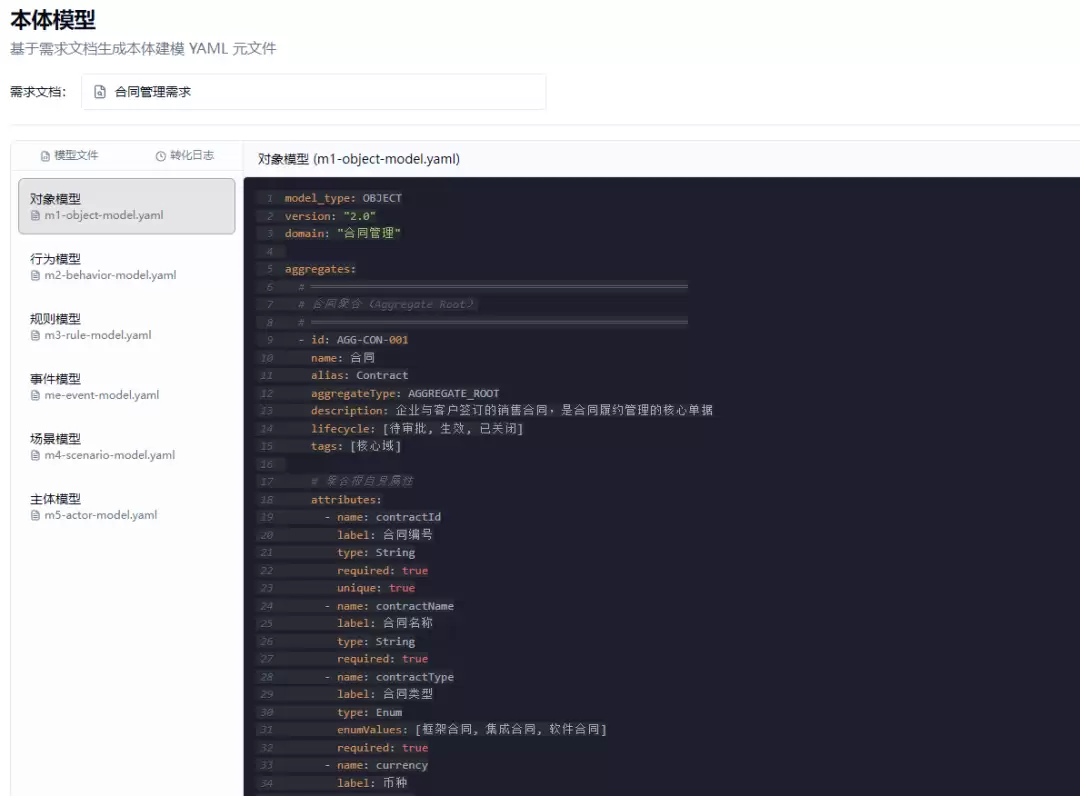
本体模型生成是平台的核心技术环节。系统将需求文档(Markdown)和完整的本体建模规范文档(87KB, 包含M1-M7+ME的全部定义、模板和字段规范)组合为Prompt,按严格的生成顺序(M1 → M2 → M3 → ME → M4 → M5)调用DeepSeek API,每个模型独立生成一个YAML文件。
顺序生成的关键技术在于前序模型上下文注入。由于后序模型依赖前序模型的定义(例如M2行为模型需要引用M1中的对象名称和行为主体,M4场景模型需要引用M2中的行为ID和ME中的事件ID),系统在生成第N个模型时,会将前N-1个已生成模型的YAML摘要(截断至3000字符)注入Prompt,使AI生成的后序模型与前序模型保持引用一致。
# 前序模型上下文注入的核心逻辑(简化示意)
if idx > 0:
previous_context = "nn## 已生成的前序模型(供参考)nn"
for pm in prev_models:
summary = pm["content_yaml"][:3000] + "..."
previous_context += f"### {pm['model_name']}n```yamln{summary}n```nn"
prompt = f"""...基于需求文档和建模规范,生成{model_name}...
{previous_context}
现在请生成 {model_name} 的完整YAML元文件。"""
整个生成过程通过SSE(Server-Sent Events)实时推送到前端,用户可以看到每个模型的生成进度、实时流式输出的YAML内容,以及详细的生成日志(成功/失败/警告)。生成完成后,YAML文件持久化到数据库,支持重新生成单个模型或全部模型。
3.3 本体可视化:四维视图验证
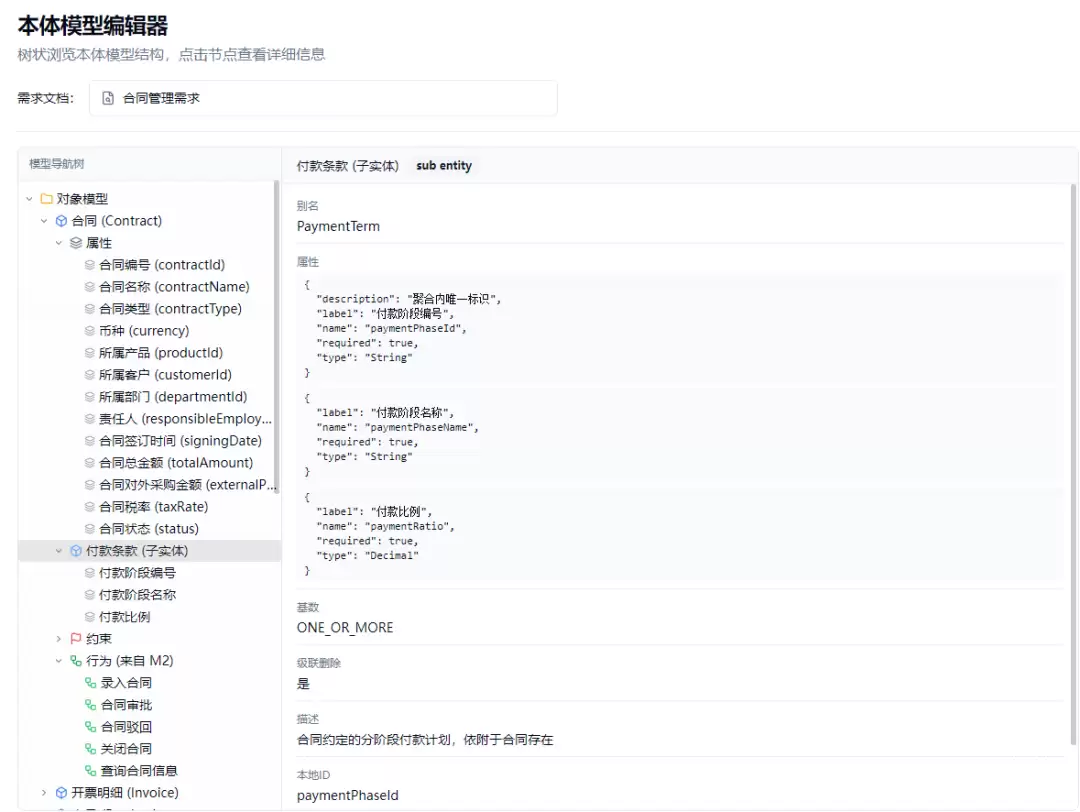
本体模型生成后,平台提供四种可视化维度,帮助用户从不同角度验证模型的正确性和完整性:
(1)本体模型树(Tree View):将六个YAML模型解析为统一的树形结构。M1按“聚合根→实体→属性”展开,M2按“行为→前置条件→输入→输出”展开,以此类推。树节点间通过引用关系建立超链接导航(例如行为模型中的对象引用可跳转到M1对应节点)。这是最全面的逐元素浏览方式。
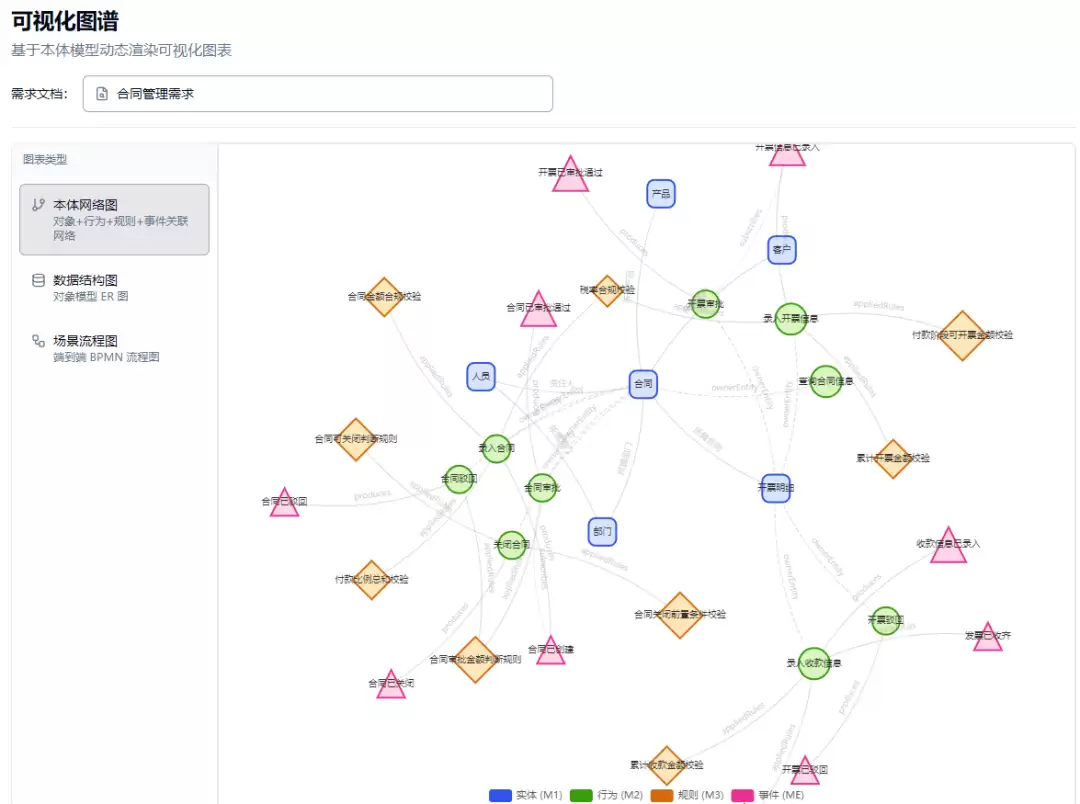
(2)知识图谱(Network Graph):基于ECharts力导向图,将对象、行为、规则、事件、场景、主体六类节点以及它们之间的引用关系(对象-行为、行为-规则、事件-行为、场景-行为、主体-行为等)渲染为交互式网络图。用户可拖拽节点、缩放视图,直观感受模型的“连接密度”和潜在的信息孤岛。
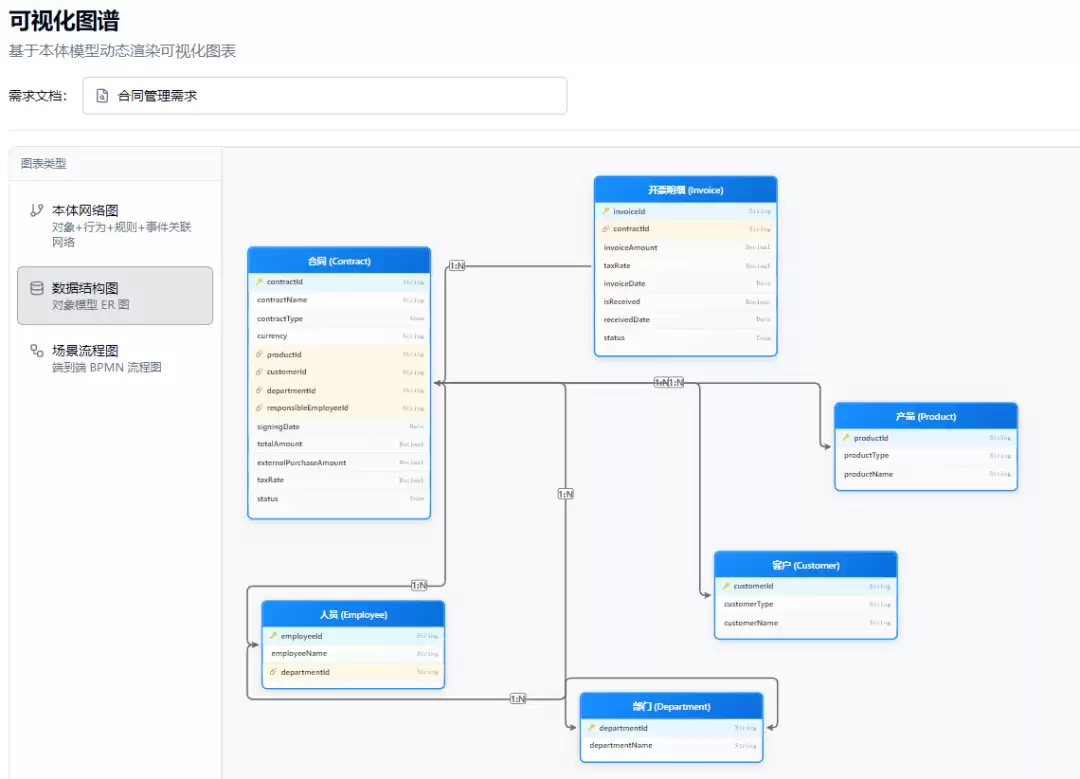
(3)数据模型ER图(ER Diagram):基于M1对象模型的聚合间关联(Aggregate Association),用AntV X6图编辑器渲染实体关系图。聚合根渲染为实体框(含属性列表),聚合间关联渲染为连线(标注引用字段和基数关系)。
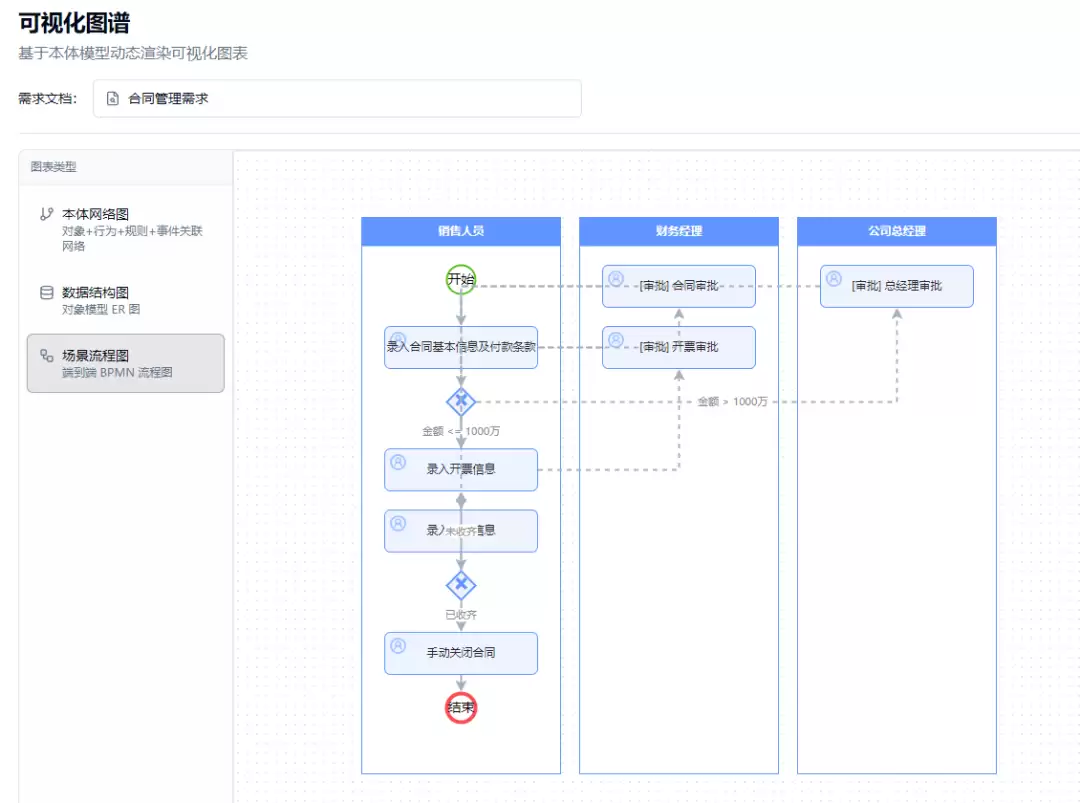
(4)流程模型BPMN图(BPMN Diagram):基于M4场景模型和ME事件模型,用Mermaid渲染端到端业务流程图。场景中的行为序列和事件触发关系被翻译为Mermaid的flowchart语法,泳道按主体角色分组。
3.4 能力代码生成:从模型到可执行代码
能力代码生成是平台将“设计态”转化为“运行态”的关键步骤,包含三个生成器:
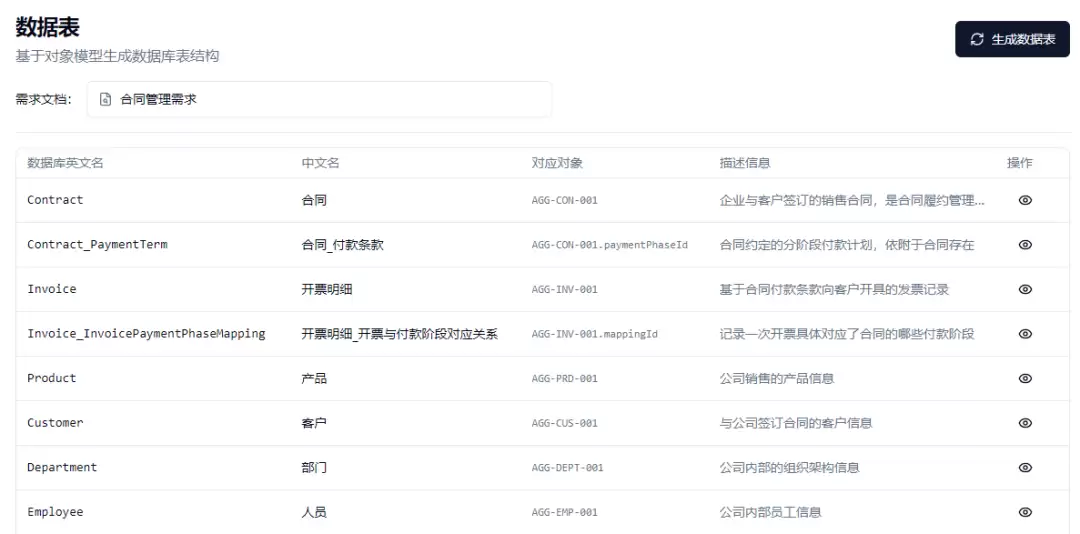
Table Generator(表生成器):解析M1对象模型的YAML,将每个聚合根映射为一张数据库主表(含聚合根属性字段),将每个子实体映射为一张子表(自动添加外键字段指向主表)。字段类型映射规则将本体的String/Integer/Decimal/Money/Date/Enum等类型映射为SQLite的TEXT/INTEGER/REAL类型。聚合间关联(Aggregate Association)自动创建外键字段。生成器直接执行CREATE TABLE DDL,在ontoreq_tables.db中创建实际的数据库表结构,同时将字段元数据(中英文名、类型、长度、PK/FK标记、引用关系)持久化到generated_tables和generated_fields元数据表中。
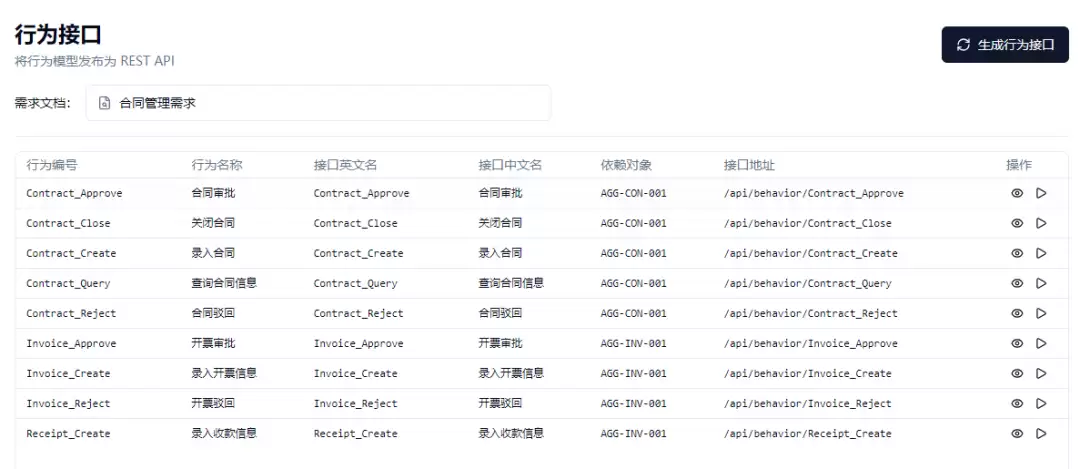
API Generator(接口生成器):基于生成的数据库表,为每张表自动生成标准的CRUD五个接口(POST新增、PUT修改、DELETE删除、GET按主键查询、POST条件查询)。每个接口生成完整的请求示例和响应示例JSON。
Beha vior API Generator(行为接口生成器):解析M2行为模型的YAML,为每个行为定义生成一个POST /api/beha vior/{行为ID}接口,包含输入参数(对应M1的属性引用)和输出结果定义。同样,Rule API Generator基于M3规则模型生成规则校验接口。
3.5 技能封装:语义聚合的七文件技能包
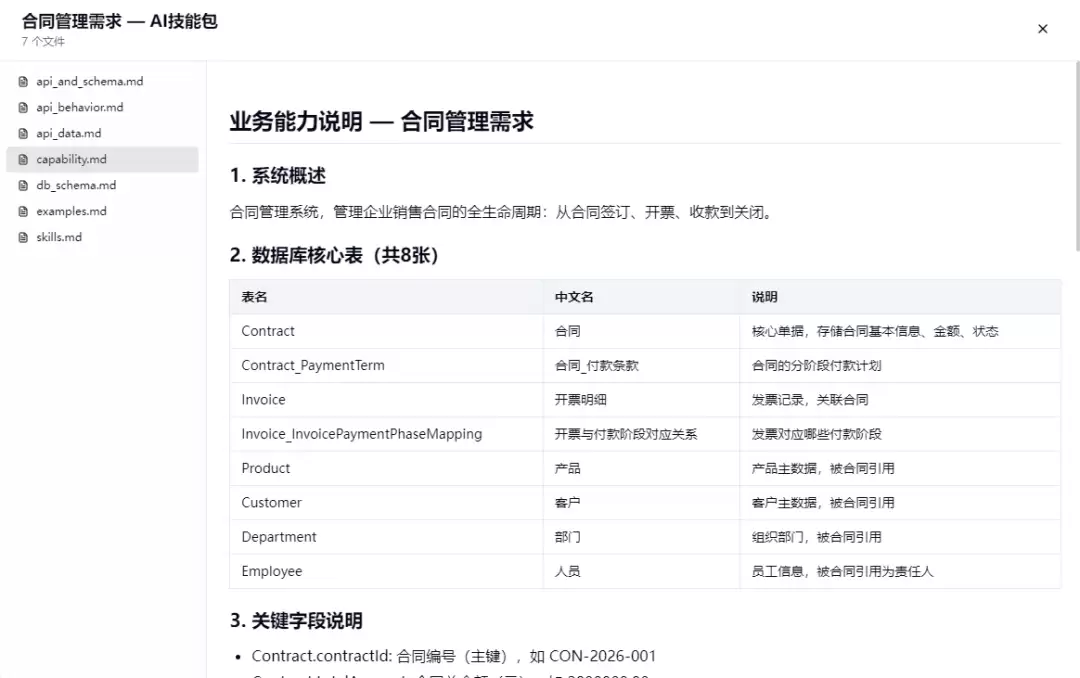
技能包(Skill Package)是本平台的核心创新——它将分散的模型、表结构、API接口、业务知识聚合为一个自描述的、AI可直接消费的语义包。每个技能包包含七个文件:
| 文件 | 内容 | AI消费方式 |
|---|---|---|
skills.md | 技能包概述、文件索引、对话能力声明 | 入口导航 |
capability.md | 业务能力说明、核心表、关键字段、业务流程、API映射 | 领域知识注入Prompt |
db_schema.md | 完整的数据库表结构(表名、字段、类型、PK/FK、说明) | SQL生成参考 |
api_data.md | 所有CRUD数据接口文档(含请求/响应示例) | API调用参考 |
api_beha vior.md | 所有行为接口文档(含输入输出定义) | 行为API调用参考 |
api_and_schema.md | 综合API+Schema参考(AI对话的主要参考文件) | 主Prompt上下文 |
examples.md | 典型对话场景示例(查询、统计、录入) | Few-shot学习 |
Code-Chat通过Skill Manifest文件(skill.manifest.yaml)加载技能包,manifest中声明了技能的激活条件、依赖运行时(数据库类型、LLM类型、是否需要推理机)、资源索引(数据层白名单、能力层工具、知识层文档、提示层文本)和能力边界(能回答什么、不能回答什么、写操作策略)。
3.6 Agent发布:智能体对话与动态表单
Agent发布是平台的最终产出环节。Code-Chat将加载的技能包内容注入AI系统提示词,构建一个“拥有完整业务领域知识”的AI助理。
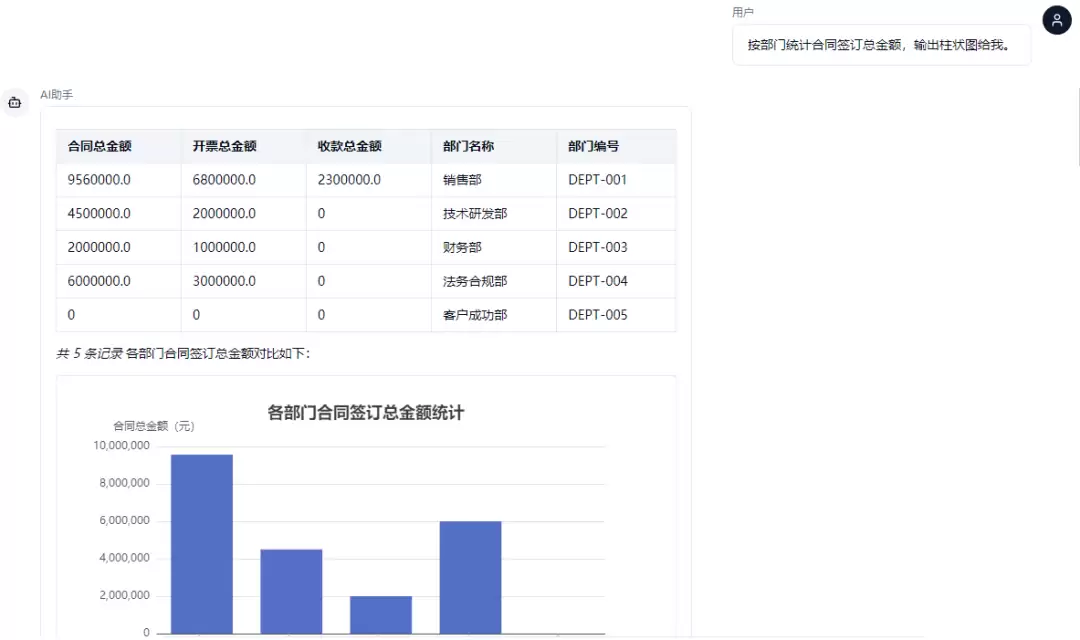
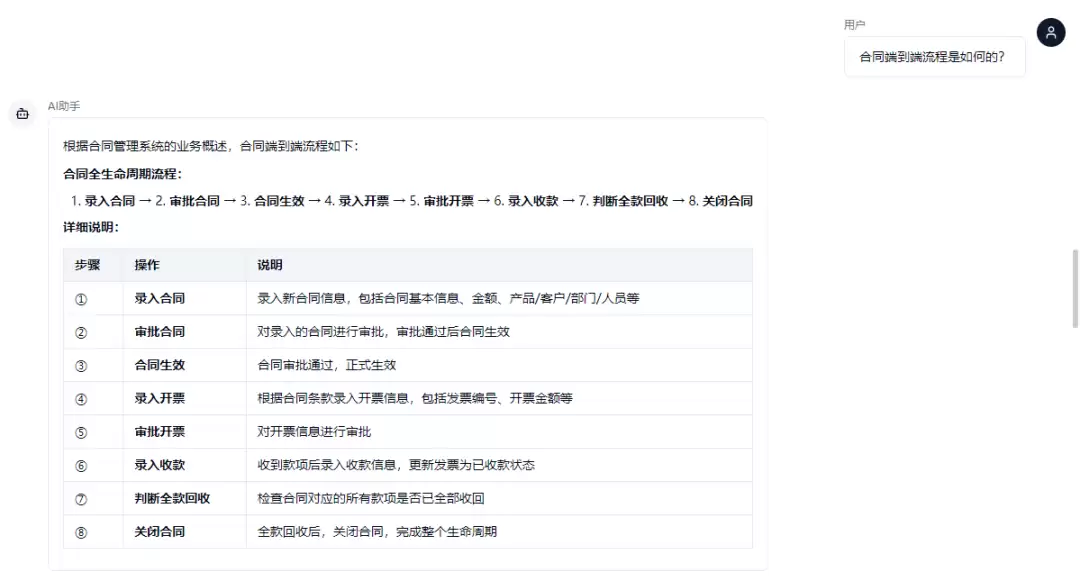
多轮工具编排:Code-Chat后端实现了一个基于DeepSeek Function Calling的多轮编排引擎(最多5轮工具调用)。AI可以调用的工具包括:query_database(自然语言转SQL查询,结果以表格/图表渲染)、explain_domain(基于场景模型生成Mermaid流程图解释业务流程)、open_page(引导用户跳转到对应的业务录入页面)。每轮工具调用作为一个独立的“步骤块”(block)通过SSE逐步呈现给前端——先流式输出步骤说明文字,再渲染查询结果(表格/卡片/图表/流程图),给用户一种“AI在逐步思考和执行”的透明体验。
安全管控:AI生成的SQL在执行前经过多层安全检查:白名单校验(只允许查询白名单内的表和字段)、危险关键词拦截(禁止INSERT/UPDATE/DELETE/DROP等写操作)、最大行数限制(默认200行)、最大JOIN数限制。这些措施确保AI对话仅具有只读查询能力。
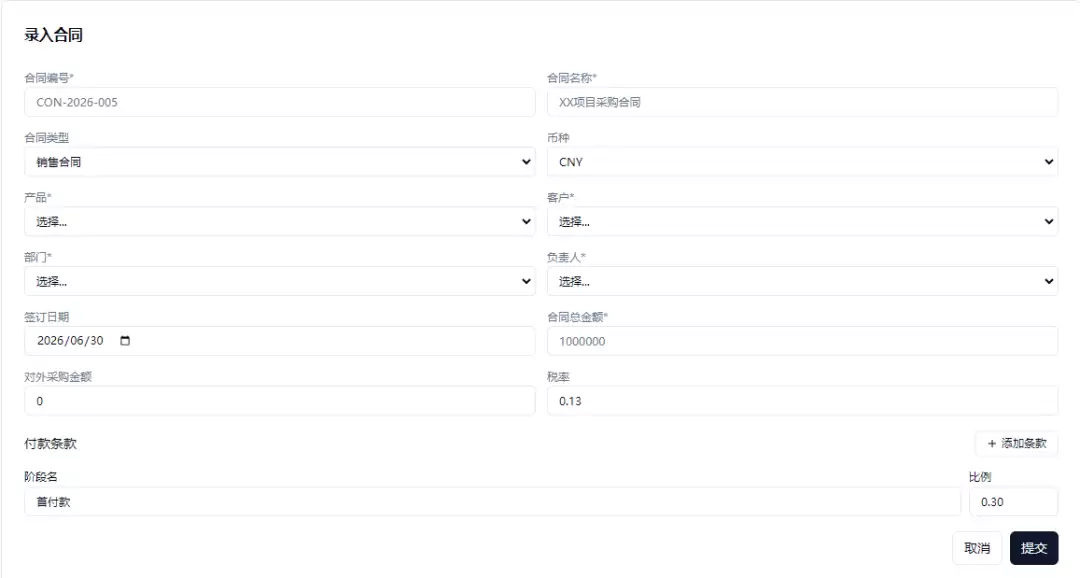
动态表单生成:当AI识别到用户的“录入”意图时,不是直接执行写操作,而是输出ui-form指令,由前端渲染为交互式表单。AI根据对应表的字段定义(从技能包中获取),自动推断每个字段的表单控件类型(文本输入、数字输入、日期选择、下拉选择等)、是否必填、验证规则。用户填写表单后,前端调用对应的API完成数据录入。这一机制将“AI理解业务意图”和“平台提供标准化UI/UE”进行了职责分离。
四、总结与展望
4.1 核心价值回顾
本文介绍的“本体+AI驱动的AI智能体工厂”平台,通过以下三个核心设计决策,实现了从需求到智能体的半自动化交付:
第一,以本体模型作为“通用中间语言”。本体模型比数据库Schema语义更丰富(包含行为、规则、事件、场景)、比自然语言需求文档更精确(形式化YAML)、比代码更抽象(独立于技术栈)。这一选择使得AI能够在每个转化阶段都“理解”完整的业务上下文。
第二,将AI定位为“智能转化器”而非“黑盒生成器”。在每个阶段,AI的角色不是“猜你想要什么然后直接生成最终产物”,而是在明确的建模规范和模板约束下,将上游产物转化为下游产物。需求探索有明确的四阶段流程和A/B类判定规则,本体生成有严格的模型规范文档和生成顺序,代码生成有确定性的映射规则。AI的创造性被约束在“语义理解和内容填充”层面,结构和格式的正确性由规范和模板保证。
第三,“工厂-商店”的松耦合架构。OntoReq负责制造技能包,Code-Chat负责运行技能包,两者通过技能包文件契约解耦。这意味着技能包可以独立迭代、独立测试、独立分发,甚至可以由其他工具生成。
4.2 当前进展与后续方向
目前,平台已完成从需求探索到Agent对话的完整链路闭环。OntoReq实现了需求探索对话、六大本体模型生成、三种可视化视图、数据库表生成和CRUD/行为/规则API生成、技能包封装,以及基础的Agent对话。Code-Chat实现了技能包动态加载、多轮Function Calling编排、SQL安全执行、图表和流程图渲染、以及基础的动态表单生成。
尚未完全自动化的部分主要集中在动态表单的智能化生成——当前AI可以根据表字段定义生成基础表单,但在表单控件的智能选择(如根据字段语义自动选择日期选择器vs文本输入)、字段间的联动逻辑(如选择了某客户后自动过滤该客户下的合同)、以及符合企业级UE规范的布局排版方面,仍需要进一步的提示词优化和前端渲染引擎增强。
后续演进方向包括:引入本体推理引擎(如基于SHACL的模型一致性校验)、支持多技能包的组合和编排、支持对接不同的LLM后端(模型无关的抽象层)、以及增强平台的协作能力(多用户、多项目、模型版本管理)。
本文档版本 1.0 | 2026年6月 | 基于 Onto-DeepSeek 项目实际源码撰写
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:本体与AI驱动的智能体工厂从设计到实现要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看