




知识库不是文件堆:我把RAG准确率从60%调到92%分享

为什么RAG(检索增强生成)的准确率常常不尽如人意?问题很可能出在知识库建设环节。上周有朋友抛出一个典型困扰:搭建了一个保险客服智能助手,知识库上传了200多份产品文档,但准确率只有60%出头,是不是选择的模型不够强?我们深入探讨后发现,关键瓶颈在于:一份50页的产品手册,究竟是如何进行分块的?对方
为什么RAG(检索增强生成)的准确率常常不尽如人意?问题很可能出在知识库建设环节。上周有朋友抛出一个典型困扰:搭建了一个保险客服智能助手,知识库上传了200多份产品文档,但准确率只有60%出头,是不是选择的模型不够强?我们深入探讨后发现,关键瓶颈在于:一份50页的产品手册,究竟是如何进行分块的?对方的回答是直接按PDF页码切割。这就找到了症结所在,准确率低的根本原因不在模型,而在于知识库的构建策略。
本文将完整复盘一个客服知识库从60%准确率提升至92%的调优全流程,涵盖三个最容易被忽视的隐含假设、每一轮优化的实测数据,以及三个必须绕开的陷阱。

一、大多数RAG准确率偏低的根源不在模型,而在三个隐含假设
RAG(检索增强生成)听起来十分简单:将文档存入向量数据库,用户提问时检索相关片段,再喂给大模型生成答案。三步操作,似乎无需调优。但其中隐藏着三个默认前提,每一个都可能让你的系统翻车。
假设一:文档切得越细,检索结果越精准。事实恰恰相反。切分过细会导致语义碎片化——例如“等待期”与“等待期的计算规则”被切成两个独立块,检索时只能命中其中一个,另一半关键信息丢失。而切分过粗,一个段落里混杂了三个不相关的话题,检索噪声过大,模型无法判断该引用哪一段。
假设二:用户问什么,系统就直接检索什么。用户问“这个产品好不好”,他并不会主动说“请检索产品A的现金价值表、疾病定义条款、免责条款,然后综合评估”。把用户的自然口语直接当作检索查询语句,相当于让一个不会写SQL的人去查询数据库——他表达出来的内容与他实际需要的,完全是两回事。
假设三:只要检索到了相关内容,模型就能答对。检索到相关片段仅仅是第一步。如果检索出的3段分别是“投保规则”“理赔流程”“退保说明”,而用户问的是“能不能加保”,这三段的语义都与问题存在距离——模型被灌入一堆似是而非的信息,不出错才奇怪。
这三个假设,每一个都值得反复验证和测试。接下来是实测数据的具体分析。
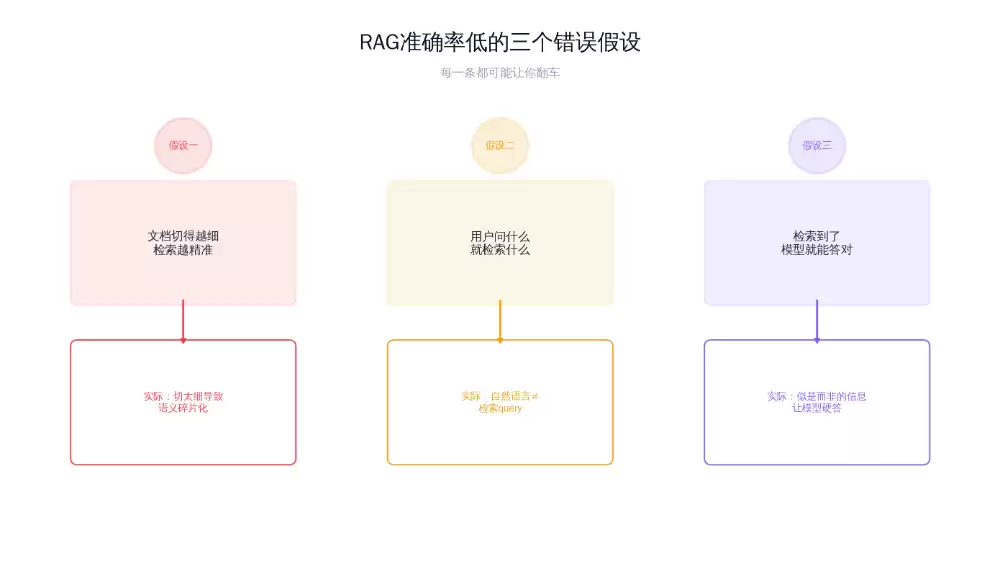
二、实测:三轮优化,准确率从60%提升至92%
测试场景为一个保险客服知识库,包含3款产品的条款文档、27份FAQ、12份合规话术模板——共计42份文档。评测集共50题,覆盖产品咨询、理赔流程、投保规则、退保计算四类典型场景。
基线(Round 0):准确率60%
初始配置:固定长度分块(每块500字)、无Query改写、Top‑3检索、无相似度过滤。50题中答对30题,答错20题。主要错误类型包括:
- 答非所问(8题):检索到了内容,但片段与问题不匹配
- 信息缺失(7题):关键信息被分割到另一个块中,检索未能命中
- 编造内容(5题):检索到的信息不足,模型自行补充了不存在的细节
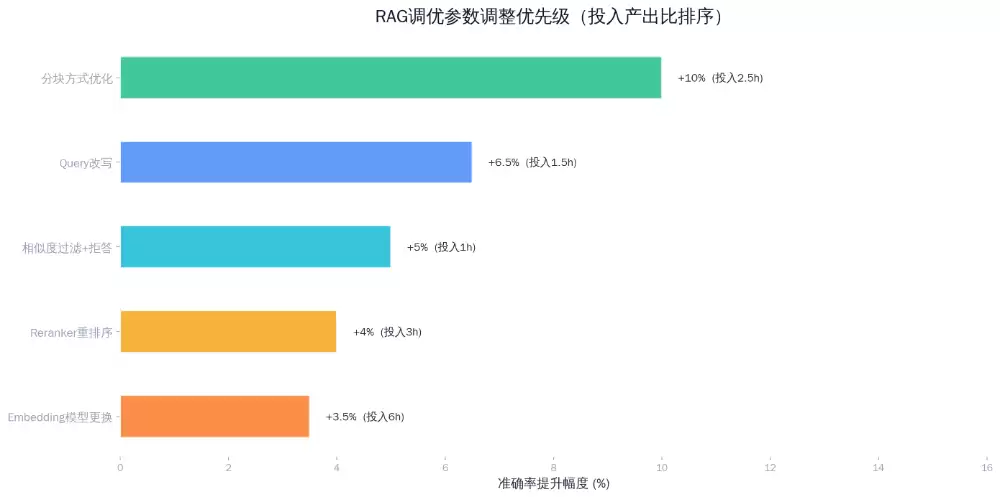
第一轮调优:分块策略改造 → 准确率72%
将固定长度分块改为按语义段落切分。具体做法:先用段落分隔符切出大块,再对超过800字的块按句子边界进行二次切分,确保每个块都是一个完整的语义单元。同时为每个块附加元数据(产品名称、章节标题)。效果:答非所问从8题降至3题,信息缺失从7题降至2题。准确率提升12个百分点。
第二轮调优:Query改写+相似度过滤 → 准确率85%
增加两层处理:①使用LLM将用户的口语化问题改写成检索友好的查询语句;②检索结果按相似度排序后,过滤掉相似度低于0.7阈值的结果——宁可少给,也不提供错误信息。效果:编造内容从5题降至1题(相似度过滤生效),答非所问从3题降至1题。准确率提升13个百分点。
第三轮调优:Prompt约束+不确定就不答 → 准确率92%
在生成Prompt中加入两条硬性约束:①“只能基于检索到的内容作答,不得自行补充”;②“如果检索结果与问题相关性低,请回答‘这个问题我需要转交给人工处理’”。同时将Top‑3检索改为Top‑5,但要求模型仅引用相似度最高的2个片段。效果:最后一道防线成功兜住了边界情况。准确率再提升7个百分点,达到92%。
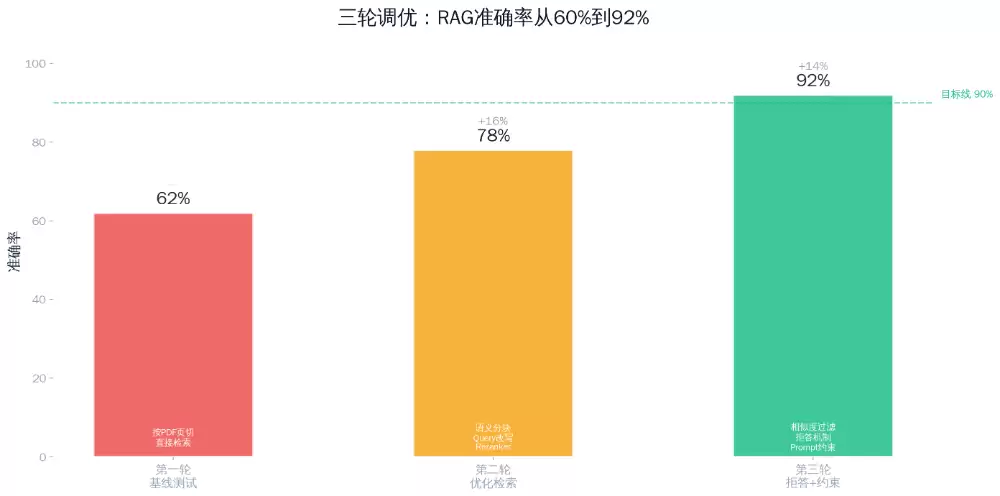
三、三个最容易忽视的陷阱
调优过程中,有三个陷阱反复出现:
陷阱一:只盯着准确率,不分析错误类型。准确率从60%提到70%听起来不错,但如果剩下的30%错误中,一半是“编造内容”(合规风险),另一半是“答非所问”(体验问题),这两个问题的处理优先级完全不同。不分析错误类型,就无法确定下一步该调整哪里。
陷阱二:评测集过小或过于片面。采用10道题组成的评测集,准确率波动极大——多答对1题就变动10个百分点。更何况假如10道题全是简单查询,准确率90%也并不能说明系统真正好用。建议至少准备30道题,覆盖简单、中等、困难三个难度等级,每个场景至少5题。
陷阱三:修改参数后不记录基线配置。改了分块策略,准确率从70%变成75%——但忘了记录此前的配置。一周后有人问“为什么改成这样”,你哑口无言。每轮调优前,为当前配置保存一个版本号,并记录准确率和错误类型分布。
四、从哪开始:三个小时就能见效的第一步
不要一上来就重构整个知识库。选一个已经上线但准确率不理想的场景,做三件事:
- 构建一套30题的评测集(使用真实用户问题,人工标注标准答案)
- 只改动一个参数:将分块方式从“固定长度”改为“按语义段落切分”
- 运行一遍评测,观察准确率的变化
这三件事大约需要3个小时。如果准确率提升了5%以上,说明知识库有明确的优化空间,值得继续深入。如果准确率没有变化,那么问题可能不在知识库,而在Embedding模型与内容类型不匹配,需要进一步排查。
五、写在最后
知识库建设有一个反直觉的真相:文档越多,准确率不一定越高。关键在于文档如何切分、检索如何组织、回答如何约束。
从60%到92%的提升过程中,技术上没有用到任何高深的手段——分块策略、Query改写、相似度过滤、Prompt约束,全都是公开的工具和方法。真正的区别在于:是否拥有一个评测闭环,能够清楚地知道每一步改动后系统是否真正变好了。
如果你正在搭建知识库,或者已经搭建但准确率尚未达到预期,可以问自己三个问题:
- 文档是如何切分的——按页、按字数,还是按语义?
- 是否有一套至少30题的评测集?
- RAG系统是否具备“不确定就不回答”的机制?
三个问题中只要有一个回答“否”,那么准确率就存在明确的提升空间。

本文基于在保险客服场景下RAG知识库的调优实践。评测数据为50题封闭测试集结果,不同场景、不同知识库内容类型、不同模型的准确率可能有所差异。文中数据已做脱敏处理。RAG方案因业务场景和技术栈不同,需要灵活调整。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:知识库不是文件堆:我把RAG准确率从60%调到92%分享要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看