




解密腾讯基于机器学习数据迁移方法专利

腾讯提出基于机器学习的数据迁移方法,通过获取多个终端迁移过程数据,训练迁移模型,实现服务器向终端精准匹配并迁移所需数据,解决终端数据量不足及人工匹配效率低的问题,提升迁移准确性与效率。
在具体的应用场景中,比如智能客服,系统能够基于终端侧积累的用户对话记录,分析出用户的兴趣、习惯乃至语言模式——这听起来很理想。但现实是,终端侧积累的数据量往往少得可怜,根本无法支撑模型训练,智能客服自然也就无法真正以符合用户特征的方式去交互。这时候,从服务器侧向终端迁移数据、训练模型的技术,就成了破局的关键。
传统做法是:在服务器上将所有终端的匿名数据汇总,训练出几个通用模型,再通过人工匹配的方式,从这些模型里挑出最符合终端需求的,然后把相关数据迁移过去。这么做确实能缓解终端数据量小的问题。但问题在于,通用模型是建立在海量终端数据之上的,它不可能和某个特定的终端完美适配,迁移过去的数据精度自然大打折扣。更何况,靠人工去匹配模型,效率低不说,人力成本也高得吓人。
正是为了攻克这些痛点,腾讯在2019年7月15日提交了一项名为“基于机器学习的迁移数据确定方法、装置、设备及介质”的专利申请(申请号:201910637116.9)。根据专利公开的资料,我们来看看这项技术到底是怎么做的。
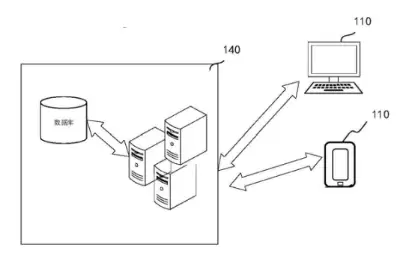
上图是整个数据迁移系统的结构框图。它包括终端和数据迁移平台,两者通过无线或有线网络相连。终端上运行着支持数据迁移的应用,而数据迁移平台则负责提供后台服务——可以是一台服务器,也可以是多台、云计算平台或虚拟化中心。平台和终端既可以单独处理数据,也能协同配合,实现更高效的组合。
这项专利的核心在于“迁移数据”。还是以智能客服为例:云服务器先确定一个迁移模型,基于这个模型,向终端迁移与它高度匹配的数据。终端把本地数据和迁移来的数据结合起来,通过机器学习对智能客服进行训练。最终,每个用户都能拥有一个专属于自己的智能客服——当你发起对话时,它会用你感兴趣的方式、符合你习惯的语言风格来回应你。
上图展示了如何利用前N个终端的迁移过程数据,来向第N+1个终端迁移数据。所有需要迁移的数据都存储在云服务器侧。针对不同终端的需求,系统从云服务器中确定出对应的数据并迁移过去。关键点在于,云服务器会基于每一次向终端进行数据迁移的过程数据进行分析,用以训练模型,使其最终能够针对特定终端精准地迁移数据。
具体来说,系统首先获取已经向N个终端(N≥1)进行数据迁移的迁移过程数据。基于这些数据,对云服务器的模型进行训练。训练完成后,这个模型就被应用到向第N+1个终端的数据迁移过程中。在获取到多个迁移过程数据后,系统会分析每个过程中的数据迁移性能指标,基于这些指标来训练待训练模型,最终获得一个成熟的迁移模型。有了这个模型,服务器就能从通用数据中精确地定位出目标终端需要的数据,并响应终端的迁移请求。
接下来,我们具体看看这个方案的流程图。
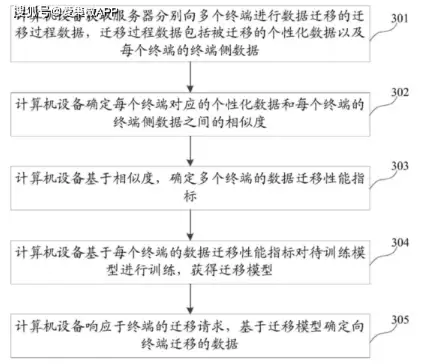
如上图所示,流程并不复杂。首先,计算机设备获取服务器分别向多个终端进行数据迁移的迁移过程数据。这个数据包括了被迁移的个性化数据,以及每个终端的终端侧数据。举个例子,在图片识别场景中,如果把猫的图片特征迁移到狗的图片识别模型上,那么两者共有的“眼睛部位”或“鼻子部位”图像数据,就是关键的迁移内容。
接着,系统计算每个终端对应的个性化数据和终端侧数据之间的相似度。理想情况下,被迁移的个性化数据应当与终端侧数据有高度重合的共同特征。相似度越高,就说明这次迁移过程的质量越好,这些高质量的数据就可以作为后续模型训练的基础。
然后,系统基于计算出的相似度,确定多个终端的数据迁移性能指标。再基于这些指标,对服务器侧的待训练模型进行训练,最终获得迁移模型。一旦终端发出迁移请求,系统便基于这个训练好的迁移模型,决定向该终端迁移哪些数据。
训练后的迁移模型内部包含多个已经优化好的神经网络层。把终端的终端侧数据输入进去,这些神经网络层会分析出终端的特征数据,然后到云服务器的通用数据库里进行精准匹配。这样一来,迁移过去的数据一定是该终端真正需要的,真正实现了“千人千面”的定制化模型,精准地满足了用户需求。
最后,我们来看看这个迁移模型具体是怎么训练出来的。
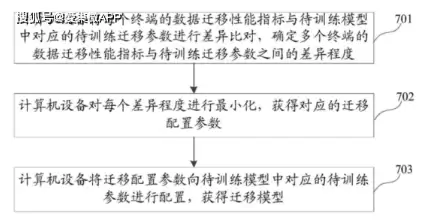
流程也很清晰。第一步,系统将每个终端的数据迁移性能指标,与待训练模型中对应的待训练迁移参数进行差异比对,计算出两者之间的差异程度。第二步,系统对每个差异程度进行最小化处理,从而获得对应的迁移配置参数。这个过程基于之前积累的N个迁移过程数据来训练待训练模型。最后,系统把这些迁移配置参数配置到待训练模型的对应参数中,从而得到一个成熟的迁移模型。
这个通过机器学习训练出来的迁移模型,本质上存储了一整套“迁移学习的技巧”——面对什么样的用户终端数据,应该从服务器端迁移什么样的知识。可以说,这是整个系统的逻辑核心。
以上就是腾讯发明的基于机器学习的迁移数据确定方法。通过获取服务器向多个终端迁移数据的过程数据,并基于机器学习对模型进行训练,最终得到了一个能够为终端“量身定制”的迁移模型。基于这个模型,服务器可以高效、精准地向终端迁移所需数据。不仅大幅提高了迁移的准确性和效率,也把从繁琐的人工匹配中解放出来——这才是关键所在。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:解密腾讯基于机器学习数据迁移方法专利要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看