




机器学习十大经典算法详解与实战应用指南

机器学习圈子里有句经典名言:“世上没有免费的午餐”——通俗点讲,没有任何一种算法能在所有任务中都表现最佳。这一原理在监督学习领域尤其突出。举个例子,你不能断言神经网络永远优于决策树,反过来也同理。模型的实际表现受多种因素影响,比如数据集的大小、分布结构等。因此,你应该根据具体问题尝试多种不同的算法,
机器学习圈子里有句经典名言:“世上没有免费的午餐”——通俗点讲,没有任何一种算法能在所有任务中都表现最佳。这一原理在监督学习领域尤其突出。
举个例子,你不能断言神经网络永远优于决策树,反过来也同理。模型的实际表现受多种因素影响,比如数据集的大小、分布结构等。因此,你应该根据具体问题尝试多种不同的算法,并通过测试集来评估性能,最终选出最合适的那一个。
当然,所选的算法必须与问题本身相匹配——这其中包含不少技巧,也正是机器学习的主要研究内容。打个比方,你要打扫房间,可能会用到吸尘器、扫帚或拖把,但绝不会拿把铲子去挖坑。
对于刚接触机器学习的新手来说,下面这份数据科学家常用的十大算法汇总,能帮你快速掌握各类算法的特性,方便后续理解和实际应用。一起来了解一下吧。
一、线性回归
线性回归大概是统计学和机器学习领域中最广为人知、最容易上手的算法之一。
由于预测建模的核心目标是最小化模型误差,有时甚至会牺牲可解释性来换取更高的预测精度,因此我们会从多个学科借用、复用甚至“借鉴”算法,其中就包含大量统计学知识。
线性回归通过一个方程式表示,借助为输入变量寻找特定权重(B),来描述输入变量(x)与输出变量(y)之间的线性关系。
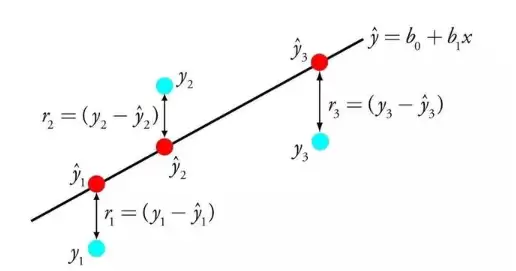
例如:y = B0 + B1 * x。给定输入x时,我们预测y,而线性回归学习算法的目标正是确定系数B0和B1的数值。
你可以通过多种技术从数据中学习线性回归模型,比如普通最小二乘法的线性代数解和梯度下降优化。线性回归已有两百多年历史,经过了广泛研究。使用时有一条经验法则:尽量剔除高度相似(相关)的变量,并从数据中移除噪声。尽管它简单,但快速有效,非常适合作为第一个尝试的算法。
二、逻辑回归
逻辑回归是机器学习从统计领域引入的另一项技术,专门用于二分类问题(即只有两个类别的任务)。
它和线性回归类似,目标也是为每个输入变量确定权重值。不同之处在于,输出的预测值需要经过一个名为逻辑函数的非线性函数进行变换。
逻辑函数的形状像大写字母S,能够将任何数值映射到0到1的范围内。这一点非常实用——我们可以根据逻辑函数的输出设定规则(例如小于0.5归为0类,否则归为1类),从而预测类别。
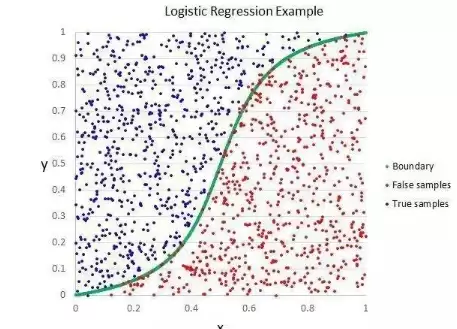
由于模型特有的学习方式,逻辑回归做出的预测还可以用来计算属于类0或类1的概率,这对需要解释原理的场景尤其有帮助。和线性回归一样,当你移除与输出变量无关的属性以及彼此高度相似的变量时,逻辑回归的效果会更好。它是处理二分类问题的快速、高效模型。
三、线性判别分析
传统的逻辑回归只适用于二分类问题。如果你面对两个以上的类别,那么线性判别分析(LDA)就是首选的线性分类技术。
LDA的表示非常简单:它由数据的统计属性构成,并且针对每个类别分别计算。对于单个输入变量来说,包括:1)每类的平均值;2)跨所有类别计算的方差。
10大基础算法汇总丨如何从算法入坑机器学习?
LDA通过计算每个类的判别值,然后选择判别值最大的类作为预测结果。该技术假设数据服从高斯分布(钟形曲线),因此最好先手动移除数据中的异常值。它是分类预测建模问题中一种简单而强大的方法。
四、分类和回归树
决策树是机器学习中非常重要的算法之一。
决策树模型可以用二叉树来表示——没错,就是算法与数据结构中的那个二叉树,没什么特殊之处。每个节点代表单个输入变量(x)以及该变量上的分裂点(假设变量为数值型)。
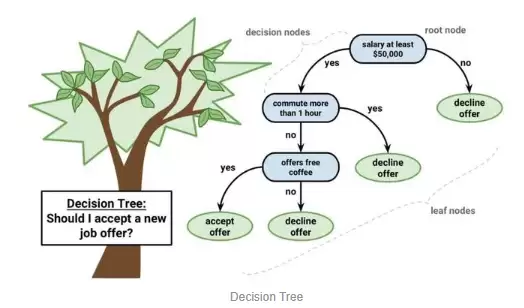
树的叶节点中存放着用于预测的输出变量(y)。预测过程就是遍历整棵树,直到抵达某个叶节点,然后输出该叶节点的类别值。决策树学习速度快、预测速度快,对许多问题也往往准确,而且你无需对数据进行特别的预处理。
五、朴素贝叶斯
朴素贝叶斯是一种简单但极其强大的预测建模算法。
该模型由两类概率组成,可以直接从训练数据中计算出来:1)每个类别的概率;2)给定每个x值时的类别条件概率。一旦计算完成,就可以通过贝叶斯定理对新数据进行预测。如果数据是数值型的,通常假设其服从高斯分布(钟形曲线),这样概率就能轻松估算。
之所以称其为“朴素”,是因为它假设每个输入变量之间相互独立——这个假设在真实数据中往往不成立,但该技术在大范围的复杂问题上依然非常有效。
六、K近邻
K近邻(KNN)算法既简单又高效。KNN的模型直接使用整个训练数据集来表示——是不是非常简单?
要预测一个新的数据点,只需搜索整个训练集中K个最相似的实例(即邻居),然后汇总这些实例的输出变量。对于回归问题,新点的预测值可能是平均输出变量;对于分类问题,新点可能是众数类别值。
成功的诀窍在于如何定义数据实例之间的相似性。如果你的属性比例相同,最简单的方法就是使用欧几里得距离,直接根据每个输入变量之间的差异进行计算。
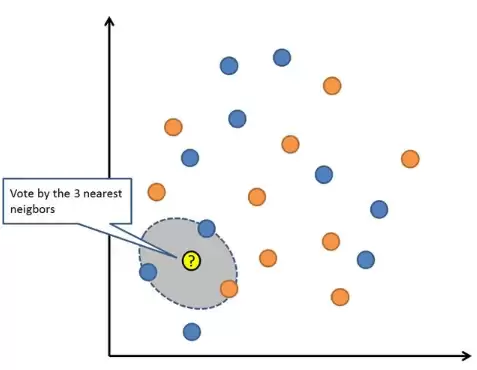
KNN可能需要大量内存来存储所有数据,但只有在需要预测时才会进行计算(或学习)。你还可以随时更新和管理训练集,以保持预测的准确性。
需要注意,距离或紧密度的概念在高维环境(大量输入变量)下会失效,这被称为“维度诅咒”。因此建议只使用与输出变量最相关的输入变量。
七、学习矢量量化
K近邻的一个不足是需要维持整个训练数据集。学习矢量量化(LVQ)是一种人工神经网络算法,它允许你只保留任意数量的训练实例,并准确学习它们。
LVQ使用一组codebook向量来表示。起初随机选择向量,然后经过多次迭代,使其适应训练数据集。学习完成后,这些codebook向量可以像K近邻一样用于预测:计算每个codebook向量与新数据实例之间的距离,找到最相似的邻居(最佳匹配),然后返回对应的类别值(或实际值)。如果将数据缩放到相同范围(如0到1之间),效果会更佳。
如果你发现KNN在你的数据集上表现不错,不妨试试LVQ,它可以降低存储整个训练集所需的内存。
八、支持向量机
支持向量机(SVM)可能是最受欢迎、讨论最多的机器学习算法之一。
超平面是一条能够分割输入变量空间的线。在SVM中,我们寻找一个超平面,将输入变量空间中的点按类别(0类或1类)分开。在二维空间里可以把它看作一条线,所有输入点都能被这条线完全分开。SVM学习算法要做的就是找出能让超平面达到最佳类别分离效果的系数。
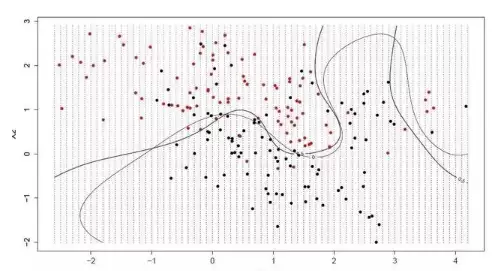
超平面与最近数据点之间的距离称为边界,拥有最大边界的超平面是最优的。而且,只有那些离超平面很近的数据点才与超平面的定义和分类器的构造有关——它们被称为支持向量,因为它们“支撑”或定义了超平面。在实际应用中,我们通过优化算法来寻找最大化边界的系数值。SVM可能是最强大的“即用型”分类器之一,值得在你的数据集上尝试。
九、Bagging和随机森林
随机森林是最流行、最强大的机器学习算法之一。它属于一类叫做Bootstrap聚合(Bagging)的集成学习方法。
Bootstrap是一种强大的统计方法,用于从数据样本中估计某个量(比如平均值)。它抽取大量样本数据,计算每个样本的平均值,然后将这些平均值再平均,从而更准确地估计真实值。
Bagging采用了同样的思路,但最常应用于决策树——而不是估计整个统计模型。具体做法是:对训练数据进行多次重采样,每份样本构建一个模型。当需要预测新数据时,每个模型都给出预测,然后将这些预测结果平均,以更好地逼近真实的输出值。
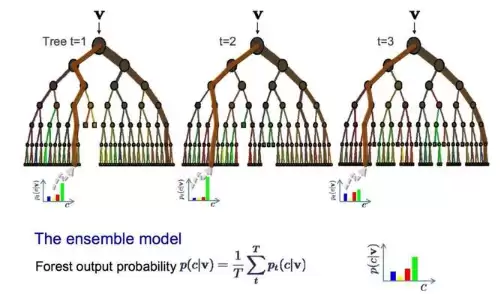
随机森林在决策树的基础上做了调整:它不再每次都选择最佳分裂点,而是通过引入随机性来实现次优分裂。这样,每个数据样本构建的模型之间的差异性更大,但每个模型本身仍然准确。组合这些预测结果,就能更准确地估计真正的潜在输出值。如果你使用高方差算法(比如决策树)已经获得了不错的结果,加上随机森林效果会更好。
十、Boosting和AdaBoost
Boosting是一种集成技术,它通过组合一些弱分类器来创建一个强分类器。具体步骤是:先根据训练数据构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误,接着不断添加新模型,直到训练集被完美预测或达到设定的数量上限。
AdaBoost是为二分类问题开发的第一个真正成功的Boosting算法,也是理解Boosting的最佳起点。目前基于AdaBoost构建的最著名算法是随机梯度提升。
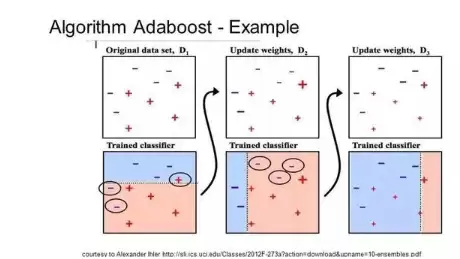
AdaBoost常常搭配短决策树使用。创建第一棵树后,每个训练实例在树上的表现决定了下一棵树对这个实例的关注程度:难以预测的训练数据会被赋予更高的权重,容易预测的则权重更低。模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习。建完所有树之后,对新数据进行预测时,会按各棵树的训练准确度来加权它们的性能。因为该算法极度重视错误纠正,所以整洁、没有异常值的数据非常重要。
写在最后
初学者在面对各种各样机器学习算法时,经常问的一个问题是:“我到底该用哪种算法?”这个问题的答案取决于很多因素,包括:(1)数据的大小、质量和性质;(2)可用的计算时间;(3)任务的紧迫性;(4)你究竟想用数据做什么。
即使是一位经验丰富的数据科学家,在真正尝试不同算法之前,也无法确定哪种会表现最好。除了上面这十种,还有更多算法值得探索,但它们是目前最受欢迎的。如果你刚接触机器学习,从这里开始,是个不错的选择。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:机器学习十大经典算法详解与实战应用指南要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点一加Turbo6X开售,含标准版与Pro版,起售价1499元,国补价1274 15元。搭载天玑7360SUPER和7400SUPER,144Hz屏,7000 8000mAh电池,主打长续航高性价比。
蔚来汽车近日上市了2026款ET5、ET5T和EC6的冠军纪念版车型。新车主打赛道竞速设计风格,提供专属外观内饰与智能座舱主题。最大的亮点在于推出了BaaS电池租用方案,ET5 ET5T租电版起售价20 5万元,EC6租电版起售价26 5万元,大幅降低了购车门槛。车辆在底盘方面进行了针对性调校,提升
微软射击游戏《战争机器:E-Day》公布PC配置要求,将于2026年10月发售。配置清单引人注目地将尚未发布的RTX5050和RX9060显卡列为最低要求,同时兼容多款现有中端显卡。游戏需130GB固态硬盘空间,最低要求12GB内存和六核CPU。官方未明确对应画质与帧数,但推测将依赖超分辨率技术
软科近日发布2026年中国大学专业排名,覆盖1132所高校的3万余个专业点。排名显示,北京大学以93个A+专业位居榜首,清华大学和哈尔滨工业大学分列二、三位。榜单同时引入“A+专业精度”指标,中国人民公安大学以93 8%的精度领先。此外,北京大学、吉林大学、武汉大学在上榜专业总数上位列前三。该排名从
- 日榜
- 周榜
- 月榜
热点快看