




深度学习优化算法全面解析

训练神经网络时,最核心的目标是找到一组参数,使损失函数的值降到最低——这本身就是一个典型的最优化问题。然而,神经网络的优化过程极其复杂:参数空间高度非凸且维度极高,仅靠数学公式直接求得全局最小值几乎不可能;尤其是深度网络动辄包含上亿个参数,计算复杂度呈指数级增长,进一步加大了优化难度。 为了逼近最优
训练神经网络时,最核心的目标是找到一组参数,使损失函数的值降到最低——这本身就是一个典型的最优化问题。然而,神经网络的优化过程极其复杂:参数空间高度非凸且维度极高,仅靠数学公式直接求得全局最小值几乎不可能;尤其是深度网络动辄包含上亿个参数,计算复杂度呈指数级增长,进一步加大了优化难度。
为了逼近最优参数,我们依赖梯度信息:沿着梯度方向更新参数,反复迭代,逐步接近最优解。这个基础流程就是随机梯度下降法(SGD)。SGD虽然简单,但相比于毫无方向地随机搜索,已经算得上“聪明”了。
打个比方:有一位性情古怪的探险家,在一片广袤干旱的地带旅行,他的目标是找到最深的谷底(他称之为“至深之地”)。他给自己定了两条死规矩:不看地图,蒙上眼睛。在完全不知道地形、什么都看不见的情况下,怎么才能最快到达谷底呢?
神经网络寻找最优参数时,我们就像那个探险家——在黑灯瞎火的世界里,没有地图,不能睁眼,必须凭感觉在复杂地形中摸索到最深处。难度之大可想而知。
但好在还有坡度可以利用。探险家虽然看不见,但能感受到脚下地面的倾斜方向。于是他朝着当前所在位置坡度最大的方向迈步——这就是SGD的核心策略。只要重复这个动作,总有一天能走到“至深之地”。
SGD
SGD的数学更新规则如下:
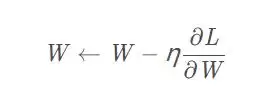
其中,W是需要更新的权重参数,∂L/∂W是损失函数对权重的梯度,η是学习率(常取0.01或0.001等固定值)。箭头表示用右边的计算结果更新左边的变量。
缺点:
(1)SGD更新过于频繁,容易导致损失函数严重震荡,形成“之”字形移动路径,效率极低。根本原因在于,梯度方向并不总指向最小值方向,特别是当函数形状非均向(例如沿某个方向延伸)时,搜索路径会变得非常低效。
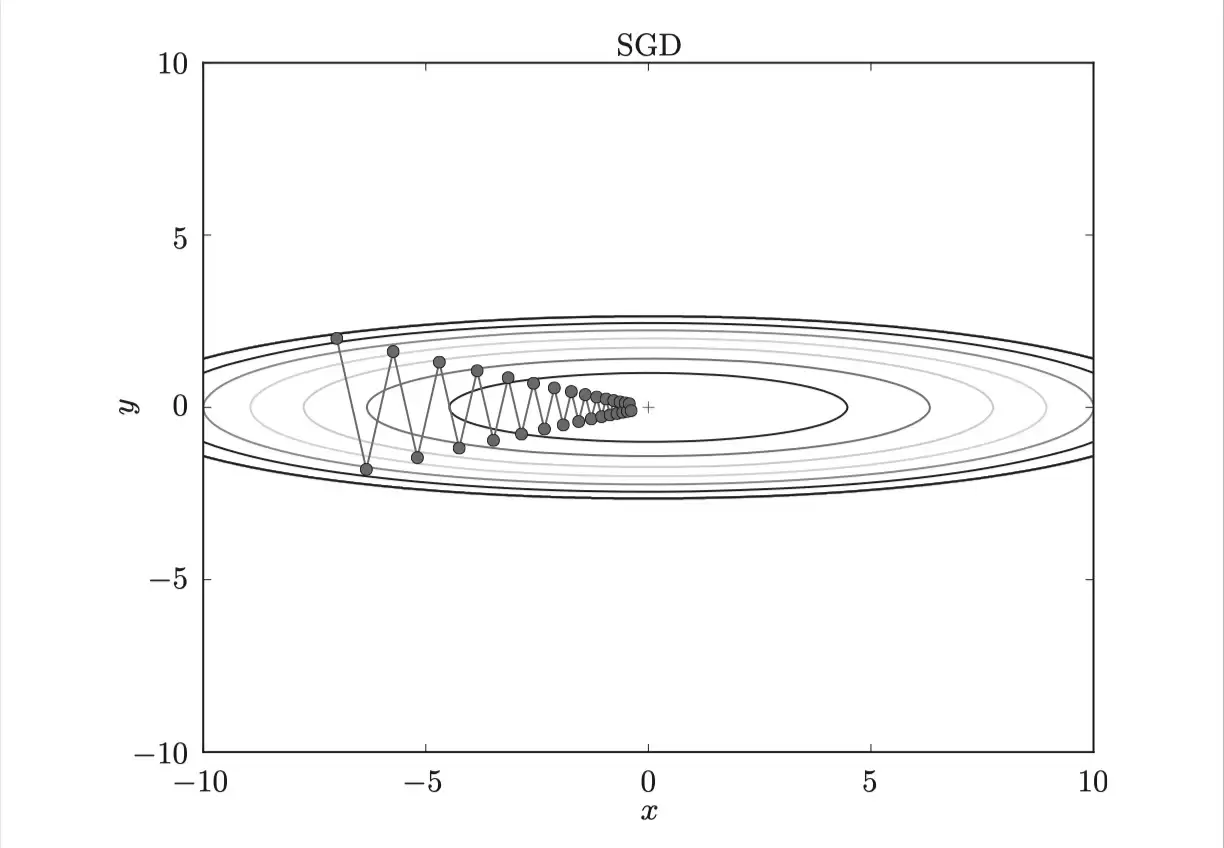
(2)SGD容易收敛到局部最优,也容易被困在鞍点。
Momentum
Momentum借用了物理中的动量概念——模拟物体运动时的惯性,更新时保留前一次的一部分方向,同时用当前梯度的微小修正来调整最终方向。这样做的好处是增加了稳定性,学习速度更快,还能在一定程度上摆脱局部最优:
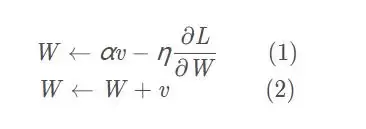
和SGD一样,W是权重,∂L/∂W是梯度,η是学习率。新增变量v对应物理中的速度。第一个式子描述了物体在梯度作用下加速的过程——就像小球在碗中滚动。第二个式子中的αv项(α通常设为0.9)负责在没有外力时让速度逐渐衰减,模拟地面摩擦或空气阻力。

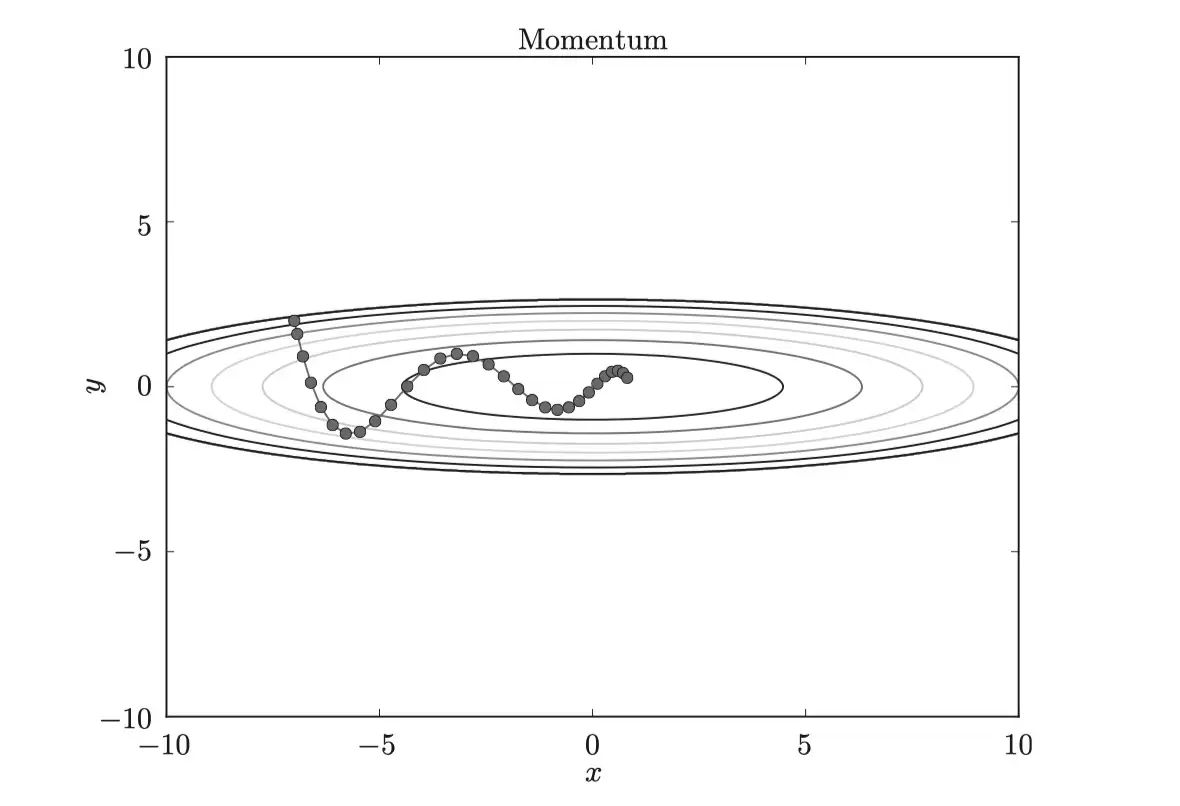
与SGD相比,Momentum的“之”字形程度明显减轻。原因是:在x轴方向虽然受力很小,但方向始终一致,逐渐累积加速;而在y轴方向受力虽大,但正反向交替,互相抵消,导致速度不稳。于是整体更快地朝向x轴移动,减少了震荡。
AdaGrad
学习率的选择至关重要:太小则训练耗时太长,太大则可能导致发散。一个常用的技巧是学习率衰减——随着训练推进,逐步降低学习率。一开始多学,后面少学。
AdaGrad把这个思想向前推进一步:它不只是对全体参数统一衰减,而是为每个参数“量身定制”学习率——根据该参数的历史梯度大小动态调整。名称中的Ada来自Adaptive(自适应)。
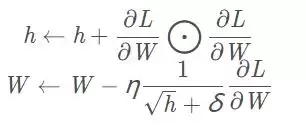
这里,h是梯度累积变量,保存了过去所有梯度的平方和(初始为0)。⨀表示逐元素相乘,η是学习率,δ是一个极小值(防止分母为0)。更新时,用1/√h来缩放学习率——也就是说,过去被大幅更新的参数,其学习率会变小。这样便实现了参数级别的学习率衰减。
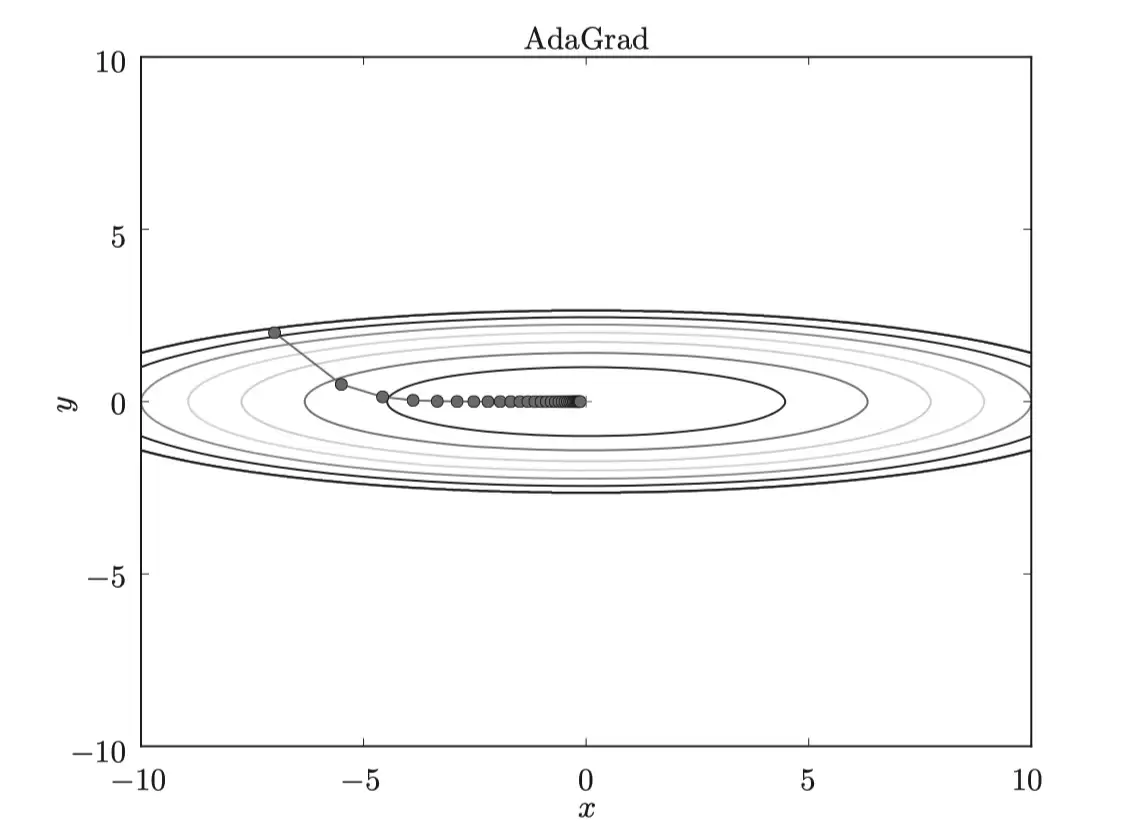
从图中可以看出,函数值高效地移向最小值。y轴方向梯度较大,初期变动明显,但随后根据历史累积进行比例调整,更新步长逐渐减小,从而削弱了“之”字形震荡。
RMSProp
AdaGrad有一个明显问题:它会记录所有过去梯度的平方和,导致学习越深入,更新量越小,最终完全停止。为了改进这一点,RMSProp不再对过去所有梯度一视同仁,而是逐渐“遗忘”旧梯度,让新梯度的信息占据更大比重。这种操作在专业上称为指数移动平均——用指数函数的方式减小过去梯度的影响。
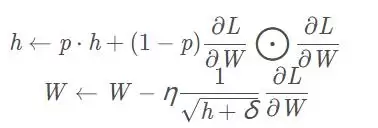
其中参数p通常取0.9,其他设置和AdaGrad一致。
Adam
Momentum模拟小球在碗中滚动,AdaGrad为每个参数自适应调整步长。如果把两者融合会怎样?Adam就是这种思路的产物——它结合了Momentum的动量机制和AdaGrad的自适应学习率,同时加入了超参数的偏置校正。这样一来,Adam既善于处理稀疏梯度(Adagrad的优点),又能应对非平稳目标(RMSprop的优点)。
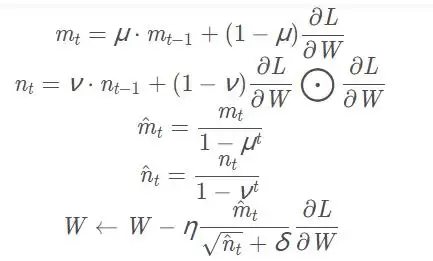
直接对梯度进行矩估计,不需要额外内存,动态调整步长。而且公式中的−m̂t/(√n̂t+δ)对学习率η构成了一个明确的动态约束,范围可控。
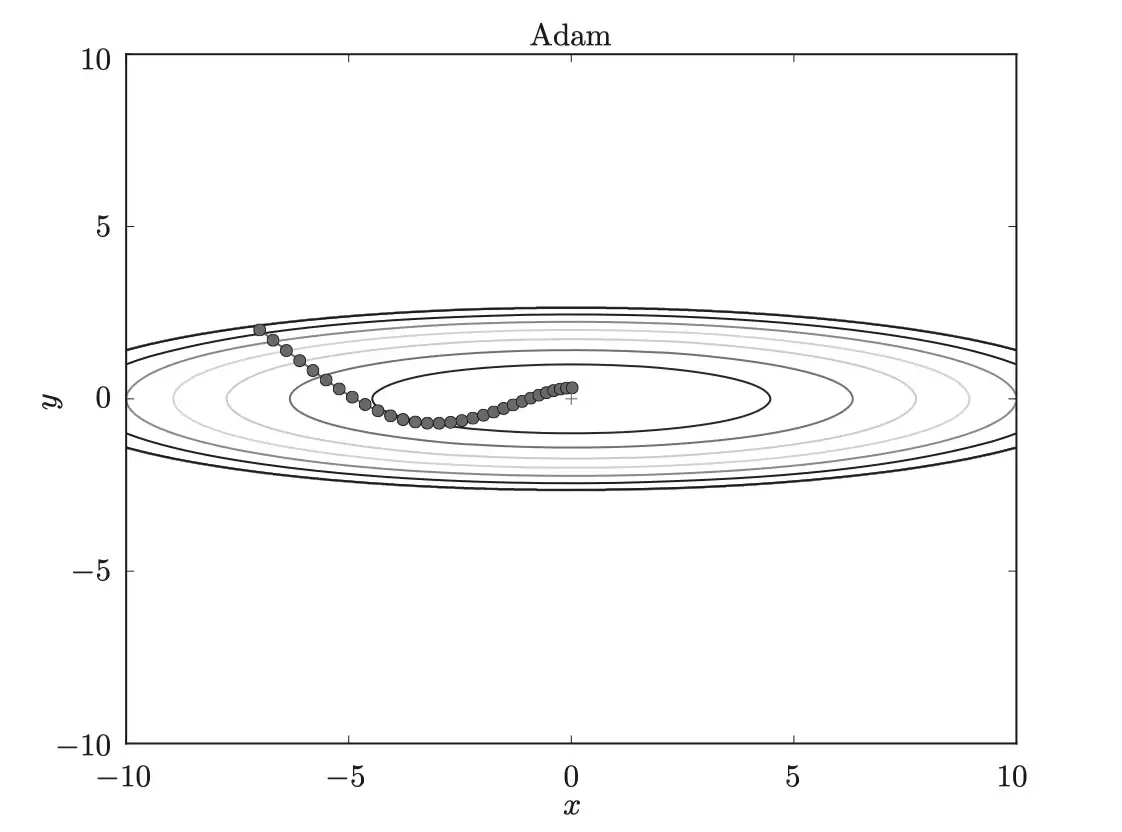
从图上看,Adam的更新路径同样像小球滚动,但和Momentum相比,左右摇晃的程度更轻——这正是因为学习率被合理调整了。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:深度学习优化算法全面解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看