




漫画混合专家MoE模型技术原理与应用解析

混合专家(MoE)通过组合多个子模型提升大语言模型性能,核心组件包括专家和路由器。专家是前馈神经网络子模块,路由器为输入选择最合适的专家。稀疏层仅激活部分参数,实现高效计算。负载均衡和专家容量机制确保专家使用均衡,提升训练稳定性。
深入探索大型语言模型中的关键技术——混合专家模型(MoE),通过50余张可视化内容,全面解析其核心原理与应用场景。
主要内容包括:
1. 混合专家(MoE)技术的定义与工作机制
2. MoE两大核心组件——专家与路由器的功能及作用
3. MoE如何借助稀疏层与功能模块提升LLMs的性能与效率
如果你最近关注过大语言模型(LLMs)的发布动态,一定会频繁看到“MoE”这个关键词。它究竟代表什么?为什么众多模型纷纷采用这一技术?
在这份视觉化指南中,我们将深入拆解这一关键组件——混合专家模型(MoE)。借助超过50张图示,带你逐步理解其运行逻辑。
本指南将聚焦MoE的两大核心组成部分:专家与路由器,并展示它们在典型大模型架构中的具体运作方式。
什么是混合专家(MoE)?
混合专家(MoE)本质上是一种通过组合多个子模型(即“专家”)来提升大模型性能的技术方法。
MoE由两个基本要素构成:
专家 —— 每一层前馈神经网络(FFNN)现在都拥有一组“专家”,每次仅从中挑选一个子集参与计算。这些“专家”本身通常也是FFNN。
路由器(或称网关网络) —— 负责决定将哪个输入token分配给哪个专家。
在采用MoE的大模型中,每一层都包含一群(某种程度上)各具专长的专家:
注意,“专家”并非真正擅长“心理学”或“生物学”等学科。最多只是对词汇的某些特征较为敏感:
更准确地说,它们的专长体现在处理特定上下文中的特定token上。
而路由器,则扮演着为给定输入挑选最合适专家的“调度员”角色:
请记住,每一位专家都不是完整的大模型,它只是大模型架构中的一个子模块。
专家(Expert),MoE中的核心元素
要理解专家是什么以及如何工作,首先需要了解MoE所要取代的对象——密集层。
密集层(Dense Layer)
一切要从大模型中基础且关键的部分说起——前馈神经网络(FFNN)。
标准的解码器Transformer架构,在完成层归一化之后,会接入一个FFNN:
FFNN的作用是让模型利用注意力机制生成的上下文信息,进一步提炼数据中更复杂的关系。然而,FFNN的规模会迅速增长。为了学习这些复杂关系,它通常会将输入映射到更高维的空间:
稀疏层
在传统Transformer中,这个FFNN被称为“密集模型”,因为它的所有参数(包括权重和偏置)都会被激活。没有闲置资源,所有计算单元都为最终输出贡献力量。
仔细观察密集模型会发现,输入信号会激活几乎全部参数:
相比之下,稀疏模型仅激活总参数中的一部分。这正是混合专家模型的核心思想。
打个比方,我们可以将一个密集模型“分割”成若干块(即“专家”),然后重新训练它,使其在任意时刻只激活其中一组专家:
背后的逻辑是,每个专家在训练过程中都学会了不同的信息。到了推理阶段,就只调用与当前任务最相关的专家。
例如,当模型被问及某个问题时,它可以挑选出最擅长处理这类问题的专家来作答:
专家究竟学到了什么?
正如我们所看到的,专家学到的是比“整个领域”更加细粒度的信息。因此,有时“专家”这个称呼其实并不完全准确,容易引起误解。
编码器模型在ST-MoE论文中呈现的专家专业化情况。
解码器模型中的专家,似乎并未表现出如此明显的领域专长。但这并不意味着所有专家都是等同的。
一个很好的例子来自Mixtral 8x7B的论文。他们将每个token用其被分配的第一个专家的颜色标记出来:

这张图也暗示,专家似乎更关注语法层面的特征,而非特定的知识领域。
因此,尽管解码器专家没有明确的领域标签,但它们似乎总是被固定用于处理某些特定类型的token。
专家架构
虽然把专家想象成从密集模型中“切”出来的隐藏层块很直观,但它们本身通常就是一个完整、自成一体的前馈神经网络(FFNN):
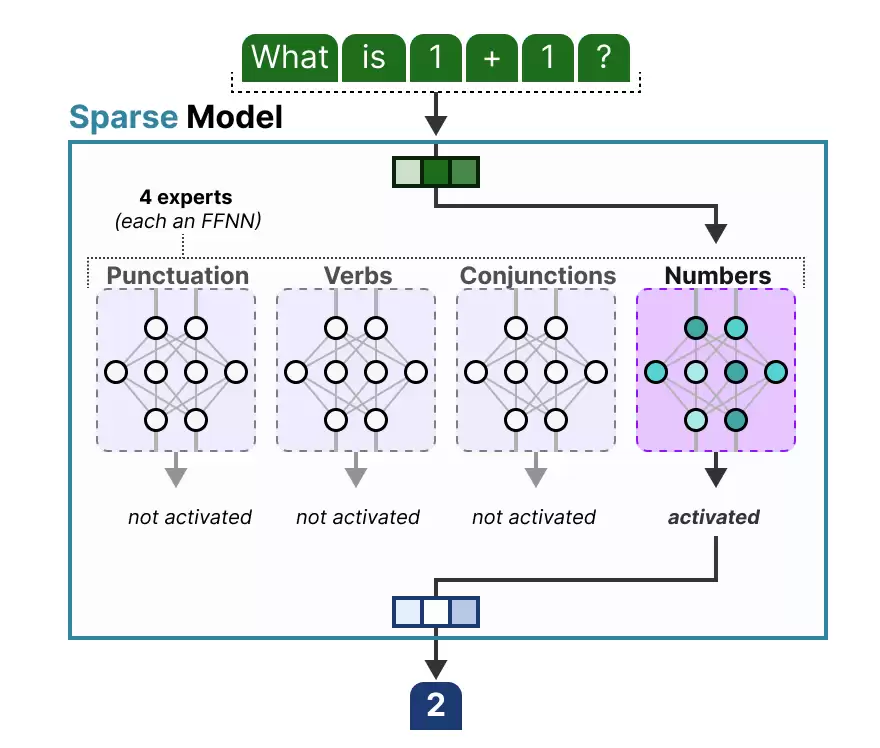
由于大模型通常包含多个解码器块,所以一个给定的文本在生成过程中会依次通过多个不同的专家:
而且,不同token被选中的专家可能不同,这导致token在模型中会走不同的“路径”:
如果我们更新一下解码器块的内部结构图,它现在不再是只有一个FFNN,而是包含了多个FFNN(每个对应一个专家):
解码器块现在拥有多个FFNN(每个都是一个“专家”),推理时模型从中挑选一部分使用。
路由机制
现在我们有了众多专家,那模型如何知道该用哪一个?
在专家们登场之前,会先经过一个路由器(也称网关网络)。这个路由器也是经过训练的,其任务是为给定的token挑选最合适的专家。
路由器
路由器(或网关网络)本身也是一种前馈神经网络(FFNN),它的职责是根据特定的输入来选择专家。它会输出一个概率分布,然后依据这个概率挑选匹配度最高的专家:
专家层最终返回的结果,是所选专家的输出乘以一个“门值”(即选择该专家的概率)。
路由器,加上那些(被选中的少数)专家,共同构成MoE层:
一个MoE层有两种形态:稀疏混合专家和密集混合专家。
两者都使用路由器来选择专家,但区别在于:稀疏MoE仅选择少数几个,而密集MoE会选中所有专家,只是给它们分配不同的权重。
例如,对于一组token,密集MoE会将token分配给所有专家,而稀疏MoE只会选其中一小部分。
在当前大模型语境下,当你看到“MoE”这个缩写时,通常默认指的就是稀疏MoE。因为它只使用专家子集,计算成本更低,这对大模型来说是至关重要的特性。
专家选择
门控网络是任何MoE系统中最重要的组件,没有之一。它不仅决定推理时选哪个专家,在训练阶段也扮演着关键角色。
在最基本的形式中,我们将输入(x)乘以一个路由权重矩阵(W):
然后,对输出的结果应用SoftMax函数,为每一个专家生成一个概率分布 G(x):
路由器就用这个概率分布,来选择与当前输入匹配度最高的专家。
最后,我们把每个路由器的输出与对应的专家输出相乘,再将结果累加起来。
让我们将整个过程串联起来,看看一个输入是如何流经路由器和专家的:
路由的复杂性
这个简单的函数有个大问题:路由器往往会“偷懒”,总是选择相同的几个专家,因为有些专家可能比其他专家学得更快。
这不仅会导致选中的专家分布不均衡,更糟糕的是,有些专家可能根本没有得到充分的训练。这在训练和推理时都会引发问题。
理想情况下,我们希望所有专家在训练和推理中保持同等的重要性——这被称为负载均衡。从某种意义上说,这是为了防止模型对某一个专家过度依赖和过拟合。
负载均衡
为了让专家的重要性保持平衡,我们需要把路由器当作核心组件,精心设计它在何时选择哪个专家。
保持Top-K
一种实现负载均衡的路由方法,是通过一个名为KeepTopK的简单扩展。通过引入可训练的(高斯)噪声,可以防止路由器总是选择相同的专家:
然后,除了你想激活的前k个专家(例如2个)之外,其余专家的权重都会被设置为负无穷(-∞):
将这些权重设为-∞之后,这些权重经过SoftMax计算得到的概率就会变成0:
KeepTopK策略虽然简单,但它仍然是许多大模型还在使用的策略。当然,KeepTopK也可以在不添加额外噪声的情况下使用。
Token选择
KeepTopK策略会将每个token路由到少数几个选定的专家。这种方法被称为Token Choice,它既可以把一个特定token只发送给一个专家(这叫Top-1路由):
也可以发送给超过一个专家(这叫Top-K路由):
这样做最大的好处是,允许模型在专家的不同意见之间进行权衡和整合。
辅助损失
为了让训练过程中专家的分布更均匀,我们会在常规的损失函数之外,额外加上一个辅助损失(也叫负载均衡损失)。
这个损失的作用,就是给模型加一个约束,迫使各个专家拥有同等的重要性。
这个辅助损失的第一步,是计算整个批次中,每个专家被路由器选中的概率之和:
这样我们就得到了每个专家的“重要性得分”。这个得分反映了,不管输入是什么,这位专家被选中的可能性有多大。
我们可以用这个得分来计算变异系数(CV),它能告诉我们所有专家的重要性分数之间的差异有多大。
举个例子,如果重要性得分差异很大,那么CV值就会很高:
反过来,如果所有专家的得分都差不多,CV值就会很低(而这正是我们想要的结果):
利用这个CV值,我们可以在训练过程中更新辅助损失,目标就是尽可能地让CV值降低(从而让每个专家都拥有同等的重要性):
最终,这个辅助损失会作为一个独立的损失项,参与模型的优化。
专家容量
不均衡的问题不只存在于“哪些专家被选中”这件事上,也体现在发送给专家的token分布上。
比如,如果输入中的token不成比例地全都涌向某个专家,而别的专家却门可罗雀,那也会导致欠训练:
这里的问题关键不仅是“该用谁”,更是“他们被用了多少次”。
这个问题的解决方案是,给每个专家能处理的token数量设一个上限,这被称为专家容量。一旦某个专家达到了它的容量上限,后续分配给它的token就会被送到下一个专家那里:
如果两个专家都满了呢?那这个token就不会被任何专家处理,而是直接被“溢出”,送到下一层去。这被称为Token溢出。
简化版MoE:Switch Transformer
Switch Transformer是第一个基于Transformer架构,但专门为了解决MoE训练不稳定问题(比如负载均衡)而设计的模型。它大大简化了架构和训练流程,同时提高了训练的稳定性。
切换层
Switch Transformer是一种T5模型(编码器-解码器),它用所谓的“切换层”取代了传统的FFNN层。切换层是一个稀疏MoE层,它为每一个token只选择一个专家(Top-1路由)。
路由器在选择专家时没有什么特殊花招,就是把输入和专家的权重矩阵相乘,然后取SoftMax(和我们之前做的一样)。
这种架构(Top-1路由)的假设是:路由器只需要一个专家,就能学会如何对输入进行路由。这就和我们之前以为的“应该把token路由到多个专家(Top-K路由)来学习路由行为”的假设不太一样了。
容量系数
容量系数是一个很重要的值,它决定了每个专家最多能处理多少个token。Switch Transformer进一步引入了直接影响专家容量的容量系数:
专家容量的计算公式非常直接:
如果我们提高容量系数,每个专家就能处理更多的token。
但如果容量系数设得太大,就会造成计算资源的浪费。相反,如果容量系数太小,又会有大量token溢出,导致模型性能下降。
辅助损失
为了进一步防止token丢失,Switch Transformer还引入了一个简化版的辅助损失。
用不着计算复杂的变异系数了。这个简化的损失函数,衡量的是分配到每个专家的token比例,与路由器分配给每个专家的概率分数之间的差异:
因为我们的目标是让N个专家的token分配均匀,所以我们希望向量P和f的值都接近1/N。
这里的α是一个超参数,我们可以用它来微调这个损失函数在训练过程中的重要程度。如果α值设得太高,它会压倒主损失函数;如果太低,对负载均衡又起不了太大作用。
专家混合模型(视觉版)
MoE可不是语言模型的专利。像ViT(视觉Transformer)这样的视觉模型,也利用了基于Transformer的架构,所以它们同样有潜力用上MoE。
简单回顾一下,ViT是一种将图像切分成一个个小块(Patch)的架构,这些小块会被当作类似token的东西来处理。
这些图像块(或者叫token)接着会被投射成嵌入向量(再加上位置嵌入),然后送入一个标准的编码器中:
这些图像块一进入编码器,就被当作token一样处理了。这种特性,使得ViT架构天然适合引入MoE。
Vision-MoE
Vision-MoE(V-MoE)是在图像模型中最早实现MoE的方法之一。它的做法很简单:把我们上面看到的ViT编码器里的密集FFNN,替换成稀疏的MoE。
这样一来,原本尺寸通常比语言模型小的ViT模型,就可以通过增加专家,实现更大规模的扩展。
由于图像通常包含大量图像块,为了减少硬件的限制,每个专家都使用了一个较小的、预设的专家容量。然而,容量设小了,又会导致很多图像块被丢弃(类似于token溢出)。
为了在低容量的情况下依然能保留重要信息,网络会给每个图像块分配一个“重要性分数”,然后优先处理那些分数高的块。这样,即使有溢出,溢出的也往往是不太重要的块。这就是所谓的批量优先路由。
所以,即使最终处理的token比例下降了,我们依然能看到那些重要的图像块被优先处理。
优先路由通过抓住重点,允许模型处理更少的图像块。
在V-MoE中,优先级评分器帮助区分出重要程度不同的图像块。但问题是,图像块是逐个分配给每个专家的,那些未被处理的图像块中的信息就丢失了。
软MoE旨在解决这个问题。它通过混合图像块,从离散的(图像块/token)分配,转向了一种“软”分配。
第一步,我们把输入x(图像块的嵌入向量)和一个可学习的矩阵Φ相乘。这为我们提供了路由信息,告诉我们某个token与特定专家的相关程度。
接着,对路由信息矩阵(按列进行)应用SoftMax操作,我们就更新了每个图像块的嵌入。
更新后的图像块嵌入,实际上变成了所有图像块嵌入的加权平均值。
从视觉上看,就好像所有的图像块都被混在了一起。这些“混合”后的图像块,再被发送给每个专家。在专家生成输出后,又会再次与路由矩阵相乘。
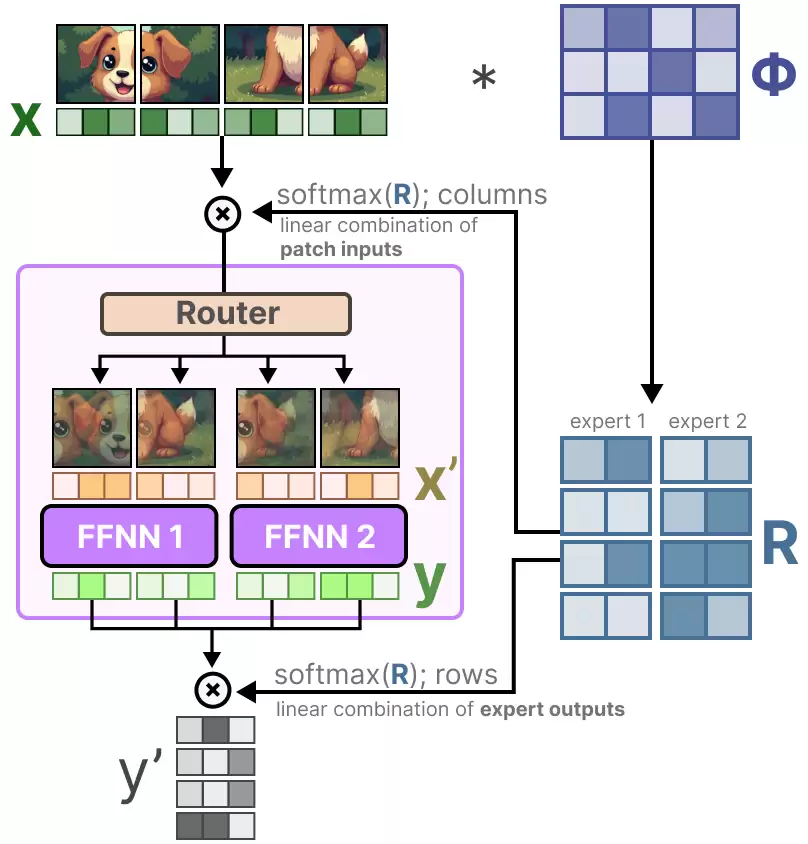
路由矩阵既影响了输入端(token级别),也影响了输出端(专家级别)。
因此,我们最终得到的是“软”的图像块/token,而不是处理离散的输入。
从Mixtral 8x7B看:激活参数与稀疏参数
MoE之所以如此引人入胜,一个很大的原因在于其独特的计算模式。由于在任意时刻只使用专家的一个子集,我们实际上可以访问比实际计算中用到的多得多参数。
尽管一个给定的MoE模型有更多的参数需要加载到内存里(这些是稀疏参数),但因为推理时我们只用少数专家(这些是激活参数),所以实际参与计算的参数反而更少。
换句话说,你仍然需要设备加载整个模型(包括所有专家)到显存里(这是稀疏参数),但在做推理时,只需要用其中的一个子集(激活参数)。所以MoE模型需要更大的显存来加载所有专家,但推理时的运行速度却更快。
让我们通过一个具体的例子来看看稀疏参数和激活参数的数量差异——以Mixtral 8x7B为例。
这里需要注意的是,每个专家的大小其实是5.6B,而不是7B(尽管模型有8个专家)。
我们必须加载8x5.6B(也就是46.7B)个参数(包括所有共享参数),但在推理时,我们只需要用到2x5.6B(也就是12.8B)个参数。
结论
到这里,我们对混合专家模型的探索之旅就告一段落了!希望这篇指南能让你对这项有趣技术的潜力有更深的理解。如今,几乎每个模型家族都至少有一个MoE版本,感觉它已经成了一个“常住居民”。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:漫画混合专家MoE模型技术原理与应用解析要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点与AI高效协作这件事,最近有个挺有意思的切入点——谷歌和瑞士邮政旗下的Digitalidag联合办了一场提示词比赛,让选手们编写指令,比如让AI制定一份详细的学习计划。亚军得主Joakim Jardenberg赛后接受了专访,分享了不少实操心得。下面这几个核心判断,值得每一位与AI共事的人反复琢磨。
物联网已成为继智能手机热潮之后,半导体芯片领域最大的应用增长引擎。根据IDC的市场分析报告,中国物联网市场规模增长潜力巨大,预计2022年将超越美国,成为全球最大的物联网市场,占据世界物联网总规模的四分之一以上。按照这一趋势推算,到2025年中国物联网市场规模至少将达到3918亿美元。物联网的核心应
在生成式AI技术迅猛发展的背景下,Dify作为一款面向开发者的开源大语言模型应用开发平台,正在深刻改变AI应用的构建方式。它诞生于2023年前后,核心目标非常明确:通过低代码化与模块化设计,使开发者无需从零搭建复杂架构,即可快速部署生产级AI应用。随着大语言模型(LLM)技术的普及,Dify逐渐成为
这次咱们来拆解一个实际项目:如何基于 TypeScript 构建一个完整的 MCP 服务器。别担心,整个过程会一步步拆开揉碎了讲,从环境搭建到代码实现,再到集成 Claude Desktop 进行测试,一条龙说清楚。 为了不让这个教程显得太干,我们会用一个非常接地气的场景——**天气查询服务**——
- 日榜
- 周榜
- 月榜
热点快看