




有监督与无监督机器学习关键区别对比

若要在当今科技领域中挑选出最热门的关键词,那必定是“人工智能”。而人工智能之所以能够展现出“智能”特性,其根本支撑正是机器学习。简而言之,机器学习是人工智能的一种重要实现方式,它通过海量数据和经验,让计算机自主掌握完成任务的能力,而非依赖程序员逐一编写规则。实际上,我们几乎每天都在享受着机器学习算法
若要在当今科技领域中挑选出最热门的关键词,那必定是“人工智能”。而人工智能之所以能够展现出“智能”特性,其根本支撑正是机器学习。简而言之,机器学习是人工智能的一种重要实现方式,它通过海量数据和经验,让计算机自主掌握完成任务的能力,而非依赖程序员逐一编写规则。
实际上,我们几乎每天都在享受着机器学习算法带来的“服务”。刷社交媒体时,信息流中的推荐内容由它掌控;浏览视频网站时,推荐列表同样源自它的计算;甚至连音乐App每周为你精心推送的“歌单”,背后都是机器学习在分析你的偏好,并努力预测你可能喜欢的歌曲。
然而,在机器学习这个“大帽子”之下,不同类型的算法风格迥异。本文将重点剖析两大主要类型:监督学习和无监督学习。它们各自拥有许多实用的算法,但面临的任务场景却截然不同。
机器学习基础概念速览
在深入探讨之前,先为后续内容打个基础——机器学习究竟在做什么?当今的AI系统,本质上完成的任务很简单:将输入转化为输出。例如,一个图像分类器:你给它一张图片或一帧视频,它能判断出里面是猫还是狗;一个欺诈检测算法:输入一笔交易数据,它能够评估该交易存在问题的概率;一个下棋AI:看到当前棋盘布局,便能计算出下一步的最佳走法。
在机器学习出现之前,传统开发方式较为“硬核”,要求程序员手动编写所有规则。例如识别猫,就需要将“猫有尖耳朵、长胡子、会喵喵叫”等规则全部写入系统。这种方法在规则明确的场景下确实有效,但面对计算机视觉、语音识别或自然语言处理等输入形式千变万化的问题时,传统方法几乎无能为力。
机器学习则换了一种思路:开发者不再“告诉”计算机具体规则,而是搭建一个通用框架,并提供海量样本让它自行“领悟”。这些样本可以是标注过的图片、历史棋局,或是用户的历史购买记录。算法自主分析数据、调整内部参数,最终实现了从“见多识广”到“举一反三”的进化。
监督学习详解
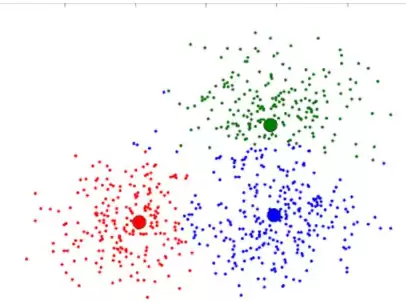
如果你关注过AI相关资讯,一定听说过“人工标注”这个术语。许多AI模型在训练之前,都需要大量带有标签的样本,这正是监督学习的核心特征——你必须事先明确输入与输出之间的对应关系。
举个具体例子:假设你想训练一个能够识别猫、狗、马图片的AI。首先需要收集大量这些动物的照片。但仅仅收集还不够,还必须为每张图片标注标签,例如将“这是猫”的文件放入指定文件夹。这种标注工作既耗时又费力,直白地说,就是典型的“苦力活”。
一旦获得标注好的数据,算法(如卷积神经网络、支持向量机)便会开始“学习”,逐步构建一个能够自动将新图片分类到正确类别的数学模型。只要训练样本足够丰富、质量足够高,该模型最终面对一张从未见过的图片,也能准确判断出它是猫、狗还是马。
监督学习主要解决两类问题:分类与回归。刚才的例子属于典型的分类——将输入对象归入特定类别,类似判断一段语音说的是“是”还是“否”也属于分类问题。而回归问题则不同,其输出是一个连续数值,例如预测用户愿意为某商品支付的价格,或者明天的降雨概率。
常见的监督学习算法包括:
- 线性回归与逻辑回归
- 朴素贝叶斯
- 支持向量机
- 决策树与随机森林
- 人工神经网络
无监督学习详解
再看另一种场景。假设你是一家电商平台的负责人,拥有成千上万的客户购买记录。你希望了解哪些客户在购物偏好上相似,以便为他们提供更精准的商品推荐。但问题在于——你并未事先为任何客户贴上类别标签,比如“喜欢跑步鞋”或“喜欢厨房小家电”。这种情况下,监督学习的方法行不通。
这正是无监督学习的用武之地。它不依赖任何预先定义的标签,而是自动“观察”数据,发现其中的天然结构,并将数据划分为若干类别。既然你无法直接告诉它谁是谁,它便自行“琢磨”:把购买行为高度相似的客户归为同一群体。聚类之后,你可能会发现:原来有一群人特别喜欢在周末购买零食,另一群人则始终只购买母婴用品。这些发现,正是无监督学习的价值所在。
K-means 是最经典的聚类算法之一。不过它面临一个挑战:你需要事先确定“分几类”?类别太少会使得不相关的样本被强行聚合,类别太多则会导致结果过于复杂,难以理解甚至准确度下降。
除聚类之外,无监督学习还有一个重要功能:降维。当数据包含过多特征(例如100列信息)时,处理起来非常棘手。特征越多,要获得良好模型往往需要更大样本量,并且容易“过拟合”——即模型只会死记硬背,在新数据上表现不佳。无监督学习算法能够帮助分析哪些特征实际价值不大,从而果断移除它们,在简化模型的同时不丢失关键信息。例如,客户数据中的“年龄”和“家庭住址”两列可能对销售预测贡献甚微,降维算法可以自动识别并剔除它们。
主成分分析(PCA)是降维领域中非常常用的算法之一。安全分析师有时也会借助它进行异常检测,在网络组织中找出不太“正常”的活动。
无监督学习最大的优势在于省去了数据标注这一最耗费人力的步骤。但万事有利也有弊:它的效果很难用统一标准来衡量。相比之下,监督学习的准确率很容易评估——只需将输出与真实标签进行对比即可。而无监督学习的结果往往具有开放性,判断其“好”或“不好”,通常需要看它实际带来了多少商业价值,这更多依赖于经验判断。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:有监督与无监督机器学习关键区别对比要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点在招聘这个行业中,数据录入的繁琐程度相信大家都有切身体会。每天需要从各类网页、社交平台、招聘站点中搜寻候选人信息,再手动一条条录入系统,既耗时费力又容易出错。今天要介绍的这款Kwal Chrome插件,正是为了彻底解决这一痛点而设计的。什么是 Kwal Chrome 扩展程序 插件?该插件的定位十分
网红经济正在进化——Twinning AI带来的玩法是:粉丝可以直接跟你的人工智能分身聊天,而你,每次互动都能收到真金白银。它集成了专业的声音克隆、文本和语音消息,以及数据分析能力,让粉丝互动变得既有趣又能变&现。 什么是Twinning AI? 简单来说,Twinning AI允许网红创建一个属于
在跨境电商和全球业务快速发展的今天,发票与财务管理工具的重要性日益凸显。AI技术的加入,让这些原本繁琐的流程实现了质的飞跃。Invoicemint 正是这样一款专注全球企业的智能发票与财务管理软件——它不只是一个简单的发票生成器,而是一套覆盖从开票、对账到税务合规、催款的全链路解决方案。 什么是In
想象一下,你随时都能找到一个倾听者——不带任何偏见,不会感到疲惫,而且完全匿名。这听起来像科幻小说里的情节,但现在已经成为现实。MyWhy 就是这样一款 AI 心理治疗应用,它将专业的情感支持装进你的口袋,让心理健康服务不再是奢侈品,而是像打开手机一样触手可及。什么是MyWhy?简单来说,MyWhy
- 日榜
- 周榜
- 月榜
热点快看