




基于人工智能的图像分类算法

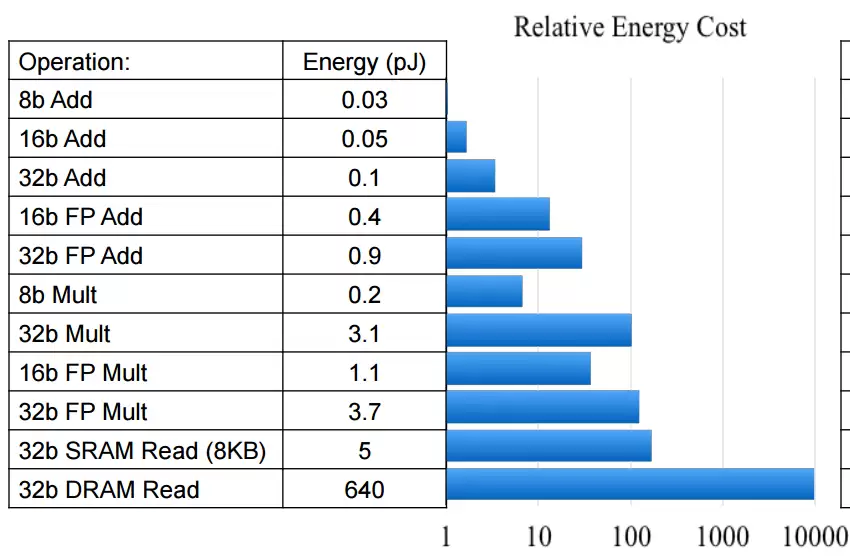
上一篇文章铺垫了几个高阶问题,其实都是在为“如何优化翻跟斗”做铺垫。话不多说,先抛一个尖锐的现实问题:我们用一个非常基础的图像分类算法,来算一笔计算成本和功耗的账。 借鉴 Mark Horowitz 公开的数据,可以对比不同空间限制下图像分类器的相对功耗。你可能会注意到,Mark 的能耗估算基于 4
上一篇文章铺垫了几个高阶问题,其实都是在为“如何优化翻跟斗”做铺垫。话不多说,先抛一个尖锐的现实问题:我们用一个非常基础的图像分类算法,来算一笔计算成本和功耗的账。
借鉴 Mark Horowitz 公开的数据,可以对比不同空间限制下图像分类器的相对功耗。你可能会注意到,Mark 的能耗估算基于 45nm 工艺节点,但业界普遍认为,这些数据按比例缩放后依然适用于更先进的工艺。换句话说,无论芯片是 45nm 还是 16nm,INT8 运算的能量成本都比 FP32 运算低一个数量级——这个比例关系基本保持不变。
功耗的计算公式很简单:
| 功耗 = 能量(J)/运算 × 运算/s |
等式中只暗示了两条路:要么降低每次运算消耗的能量,要么减少总运算次数——或者双管齐下。
拿 ResNet50 来说,这是个经典的目标网络,近乎达到了最先进的图像分类性能,同时参数(权重)比同等性能的其他网络少很多。部署它进行单次推断,大约需要 77 亿次运算。换句话说,每分类一张图,就产生 7.7 × 10⁹ 的“计算账单”。
假设一个高容量推断场景:每秒处理 1000 张图像。用 Mark 的 45nm 能耗数据算一下:
| 功耗 = (4pJ + 0.4pJ)/运算 × 7.7B运算/图像 × 1000图像/s = 33.88W |
这是 FP32 全精度下的结果。33.88W 放在服务器上还能接受,但如果是嵌入或边缘设备,这个数字恐怕就不太友好了。
优化的第一个维度:量化。将网络从 FP32 压缩到 8 位整数运算,功耗直接降了一个数量级以上。训练阶段 FP32 的高精度对反向传播很有帮助,但推断阶段处理像素数据时,这种精度几乎不创造价值。大量研究早已证明,可以逐层分析权重分布并量化,同时将预测精度保持在合理范围内。
更深入的研究显示,8 位整数值对像素数据来说是相当好的“通用解”,甚至很多内层可以压到 3–4 位,精度损失微乎其微。赛灵思研究实验室(由 Michaela Blott 领导)多年来在二进制神经网络(BNN)上做出了令人瞩目的成果(感兴趣的话可以去看看 FINN 和 PYNQ 项目)。
就我们当前的 DNNDK 方案而言,重点是将网络推断量化到 INT8。这并不是巧合:现代赛灵思 FPGA 中的单个 DSP 片可以在一个时钟周期内完成两个 8 位乘法。16nm UltraScale+ MPSoC 系列超过 15 种器件变型,DSP 片数量从几百到几千不等,且保持应用/OS 兼容性。16nm DSP 片的最大时钟频率可达 891MHz——这意味着中等规模的 MPSoC 器件已经是一台强劲的计算翻跟斗。
从 FP32 切换到 INT8,数学上会变成这样:
| 功耗 = (0.2pJ + 0.03pJ)/运算 × 7.7B运算/图像 × 1000图像/s = 1.771W |
Mark 在演讲中提出一个观点:要解决计算效率问题,就得用专门构建的翻跟斗。这一思路完全适用于机器学习推断。
此外,量化之后还能带来一个附加收益:FP32 的外部 DDR 流量至少减少四倍。外部存储器访问的功耗比内部存储器高得多,这个事实很多人都知道。Mark 的数据显示,访问一次 DRAM 大约消耗 1.3–2.6 nJ,而 L1 存储器的访问成本只有 10–100 pJ。换句话说,与赛灵思 SoC 内部的 BlockRAM 和 UltraRAM 相比,外部 DRAM 访问的能量成本高出一个数量级还不止。
除了量化,网络剪枝也能进一步削减推断所需的计算量。用赛灵思 Vitis AI 优化器,在 ILSCVR2012(ImageNet 1000 类)上训练的分类模型,计算负载可以减少 30–40%,同时精度损失不到 1%。如果减少预测类别的数量,还能继续提升性能。在真实场景中,大多数分类网络只处理有限数量的类别——这就给了剪枝更大的发挥空间。举个例子,我们有一个剪枝后的 VGG-SSD,只在四个类别上训练,计算量从原始网络的 117 GOP 降到了 17 GOP,精度没有任何损失。谁说 VGG 不够内存效率?
就算只按 ILSCVR2012 的 1000 类来估算,剪枝通常也能降低 30% 的计算负载。于是:
| 功耗 = (0.2pJ + 0.03pJ)/运算 × 7.7B运算/图像 × 0.7 × 1000图像/s = 1.2397W |
把这个数字和最初的 33.88W 放在一起,差距一目了然。
虽然这个简化分析忽略了很多混合因素,但优化潜力已经非常明显。所以当大家还在苦苦等待“解决计算饱和的万能药”时,不妨想想吴恩达那句名言:“AI 是新电能”。注意,他并不是说 AI 需要更多电能,而是强调 AI 的价值和影响力。因此,对机器学习推断这事,没必要盲目跟风,更不必为了高性能推断急着给设备上液冷散热。
下一篇文章,我们将探讨专门构建的“高效”神经网络模型,以及如何在赛灵思平台上利用它们获得更大的效率增益。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:基于人工智能的图像分类算法要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点对于视频创作者来说,音频往往是最耗费精力的后期环节——不仅要寻找合适的音效、搭配情绪氛围,还得反复试听与剪辑。而Adorno AI的出现,正好击中了这一痛点。它本质上是一个专为视频内容打磨音频的AI平台,能够自动分析你上传的视频画面,随后提供量身定制的声音推荐,并直接生成高品质音频素材。节省了大量手
先来快速认识一下 Ogimi:这是一款基于 AI 技术的 Chrome 扩展,能够根据你的具体需求实时生成个性化引导冥想。简单来说,它让冥想不再千篇一律,而是真正为你量身打造,成为专属的冥想教练。 什么是 Ogimi ai chrome 扩展程序 插件? Ogimi 的核心价值在于“AI 定制”——
在合同处理这件事上,大多数人要么自己动手拼凑模板,要么咬牙花高价找律所。现在多了一个选项——一个直接嵌入 Microsoft Word 的 AI 插件,专门用来起草、修改和审查法律协议。这就是 Tynal 在做的事。 什么是 Tynal? Tynal 是一个运行在 Microsoft Word 环境
在区块链开发领域中,智能合约的编写往往是技术要求最高的环节之一——不仅需要开发者精通 Solidity 语法,还要时刻警惕各种隐蔽的安全漏洞。近期一款名为 SmartPress 的工具备受关注,其核心定位非常明确:将自然语言提示直接转换为可部署的合约代码。更值得关注的是,它还能自动修复其他 AI 工
- 日榜
- 周榜
- 月榜
热点快看