




阿里开源实时全双工多模态模型Wan-Streamer

阿里达摩院开源Wan-Streamer,一种端到端实时全双工多模态基础模型。其统一因果Transformer架构整合文本、音频、视频Token,实现亚秒级双向视频交互,模型响应延迟200毫秒,端到端总延迟550毫秒,稳定输出25FPS同步音视频。支持实时打断、多模态输入理解及长对话一致性。
Wan-Streamer是什么
简单来说,Wan-Streamer是阿里达摩院开源的一个端到端实时全双工多模态基础模型。它最大的特点,就是通过一个统一的因果Transformer架构,把文本、音频、视频这些不同模态的输入输出Token全部整合到同一条因果序列里。这意味着它能实现真正的亚秒级实时双向视频交互——模型侧响应延迟只有200毫秒,端到端总延迟控制在550毫秒,稳定输出25FPS的同步音视频。听起来很抽象?没关系,接下来我们把它的方方面面拆开看。
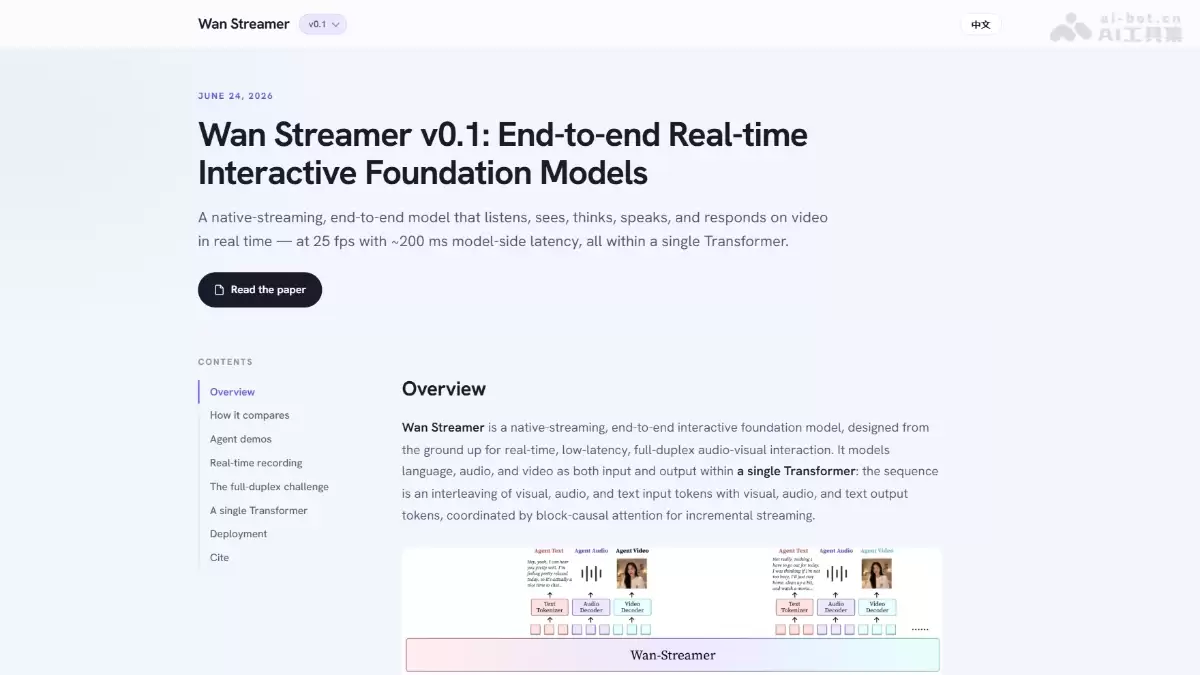
Wan-Streamer的主要功能
- 实时音视频对话:支持用户与AI数字人进行双向视频通话,AI能同步输出语音和面部表情,而不是干巴巴地只说话。
- 全双工交互:这可不是那种“你问我答、等你说完”的半双工模式。用户可以随时打断,AI也能主动提问,对话节奏和自然度都接近真人。
- 多模态输入理解:真正意义上的“眼观六路耳听八方”——能同时理解用户的视频画面、语音和文字输入,信息维度更丰富。
- 流式分片生成:采用160ms的短时流式分片,边接收信息边生成反馈,不需要等全帧数据都拿到才开始处理。
- 长时序一致性:通过全局KV上下文缓存,保证在长时间对话中,数字人的人物形象、语气都能保持稳定统一,不会聊着聊着就变了一张脸。
Wan-Streamer的技术原理
当然,要实现上面的功能,技术底子必须扎实。几个关键设计值得重点关注:
- 统一单Transformer流式架构:把用户的画面、人声、文字输入和AI的语音、表情、字幕输出,全部交错排列成一条因果Token流。文本部分采用自回归预测,音视频部分则通过流匹配条件联合生成。
- 全因果技术栈设计:从编码器、解码器、VAE到注意力层,整个技术栈都遵循因果约束,只使用历史时序信息来预测下一个单元,核心块的因果注意力限制了未来Token不可见,确保了信息处理的实时性。
- 三段式训练流程:多任务预训练阶段混合图文语音对话数据;全双工微调阶段学习倾听、插话、停顿等交互行为;流式蒸馏阶段则将大教师模型轻量化,并采用滚动自强制策略优化小模型。
- Thinker-Performer双GPU推理:一个叫Thinker,负责处理用户音视频编码与上下文更新;另一个叫Performer,负责执行流匹配音视频去噪生成。两者共享上下文,并行执行,各司其职。
如何使用Wan-Streamer
需要注意的是,截至当前,Wan-Streamer仅发布了论文与项目官网的演示Demo,完整的代码和模型权重尚未开源,所以暂时还无法进行本地部署。耐心等待后续更新吧。
Wan-Streamer的核心优势
- 超低延迟:模型侧200ms响应,端到端仅550ms,远低于行业普遍1秒以上的水平。你可能会问,200ms有多快?这么说吧,从一个问题脱口而出到AI开始回应,几乎在同一瞬间。
- 端到端一体化:单一模型完成感知、理解、生成全流程,不再需要ASR、LLM、TTS、渲染等多个模块拼凑拼接,架构简洁,问题也少。
- 全双工实时交互:支持边听边回应、中途打断,交互的自然度完全可以媲美真人对话。
- 音视频同步:语音与面部动作是同步约束生成的,不需要后期再去对齐修复,口型零错位,这才是真正意义上的“从声音到表情,一步到位”。
- 长对话稳定性:全局KV上下文保证了人物容貌与语气在长时间对话中不漂移,不会出现聊到一半就变了个人。
Wan-Streamer的项目地址
- 项目官网:https://wan-streamer.com/
- arXiv技术论文:https://arxiv.org/pdf/2606.25041
Wan-Streamer的同类竞品对比
从技术指标来看,Wan-Streamer和目前市面上另一款典型产品——GPT-4o Realtime,存在不少差异。直接上一张对比表会更直观:
| 对比维度 | Wan-Streamer | GPT-4o Realtime |
|---|---|---|
| 开发方 | 阿里达摩院 | OpenAI |
| 视频输入 | ✅ 支持 | ✅ 支持 |
| 同步视频输出 | ✅ 数字人视频 | ❌ 仅语音 |
| 全双工交互 | ✅ 实时打断/插话 | ⚠️ 部分支持 |
| 端到端架构 | ✅ 单一Transformer | ❌ ASR+LLM+TTS 拼接 |
| 模型响应延迟 | 200ms | 230ms |
| 端到端总延迟 | ~0.55s | ~0.8s |
| 渲染延迟 | 含端到端内 | 不含(仅语音) |
| 口型同步 | ✅ 原生同步生成 | ❌ 无视频输出 |
| 长时序一致性 | ✅ 全局KV缓存 | ⚠️ 依赖外部系统 |
| 当前分辨率 | 192p(原型) | 无视频输出 |
从表格能看出来,Wan-Streamer在全双工交互、视频输出与口型同步方面有明显优势,尤其在多模态视频对话的一致性上领先。当然,GPT-4o Realtime在纯语音场景下仍然有它的积累。
Wan-Streamer的应用场景
- 虚拟客服:银&行、电商等场景可以部署一个面对面的实时视频咨询助手,而不是冷冷的语音菜单。
- 直播互动:AI主播可以实时回应观众弹幕与语音提问,互动体验提升不止一个档次。
- AI陪伴:情感陪伴数字人支持实时视频聊天,在远程陪伴或心理疏导领域有很大想象空间。
- 游戏NPC:交互式游戏角色能够与玩家进行实时视频对话,游戏沉浸感自然更强。
- 在线教育:AI虚拟教师进行实时视频答疑与个性化辅导,远胜于冷冰冰的文字答疑。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:阿里开源实时全双工多模态模型Wan-Streamer要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点RAG落地的关键在于数据检索而非大模型。直接大模型、微调与RAG各有适用场景。检索效果受分块粒度、排序策略及混合检索影响。常见误解包括认为RAG总是更优、简单余弦检索足够、更多文档效果更好。应注重数据质量,采用渐进式部署和用户反馈闭环。
微软推出AutoGenStudio低代码工具,业务人员可通过可视化拖拽组装模型、技能和记忆组件,构建智能体工作流。工具集成实时监控、调试评估功能,支持导出JSON配置文件进行部署,降低开发门槛。
英国国民保健署正将人工智能引入医疗体系,智能手机可居家监测肾脏疾病,穿戴贴片实时捕捉心律不齐,AI加速乳腺癌筛查分析。这些技术有望改善筛查、癌症治疗和中风护理,但全面应用仍需长期推进。
近年来,人工智能、云计算与大数据无疑是科技领域最受瞩目的三大趋势。其中,人工智能技术已深入渗透到各行各业,成为名副其实的核心驱动力。其背后的原因并不难理解——它不仅能带来实实在在的效益,更关键的是,正大力推动制造业向智能化方向转型升级。 众多学者同样对人工智能的发展前景给予了高度评价。他们认为,未来
- 日榜
- 周榜
- 月榜
热点快看