




DeepSeek三大关键版本核心技术10分钟速览

DeepSeekV2采用混合专家系统与多头潜在注意力机制,大幅降低推理成本。V3引入FP8精度与多Token预测,提升计算效率。R1通过强化学习与监督微调结合,性能比肩OpenAIo1,并开源蒸馏模型,推动行业推理大模型发展及国产芯片生态完善。
DeepSeek模型凭借深度思考、极致性价比和开源特性,迅速在中国AI圈引发了现象级关注。如今,是否了解DeepSeek甚至成了划分人群的一个新标尺。那么,它的爆发背后,技术层面到底发生了什么?今天我们从技术视角,拆解DeepSeek三个关键版本的核心能力与优势,聊聊以下三个部分:第一,技术视角如何看待DeepSeek出圈的原因;第二,不同版本模型的核心技术优势;第三,它对AI圈的影响与未来趋势。

技术视角如何看待DeepSeek出圈的原因
DeepSeek的出圈始于春节期间,不仅AI从业者在关注,连身边朋友家人也都聊起了它。发展到全民热度,这个事件是怎么一步步发生的?
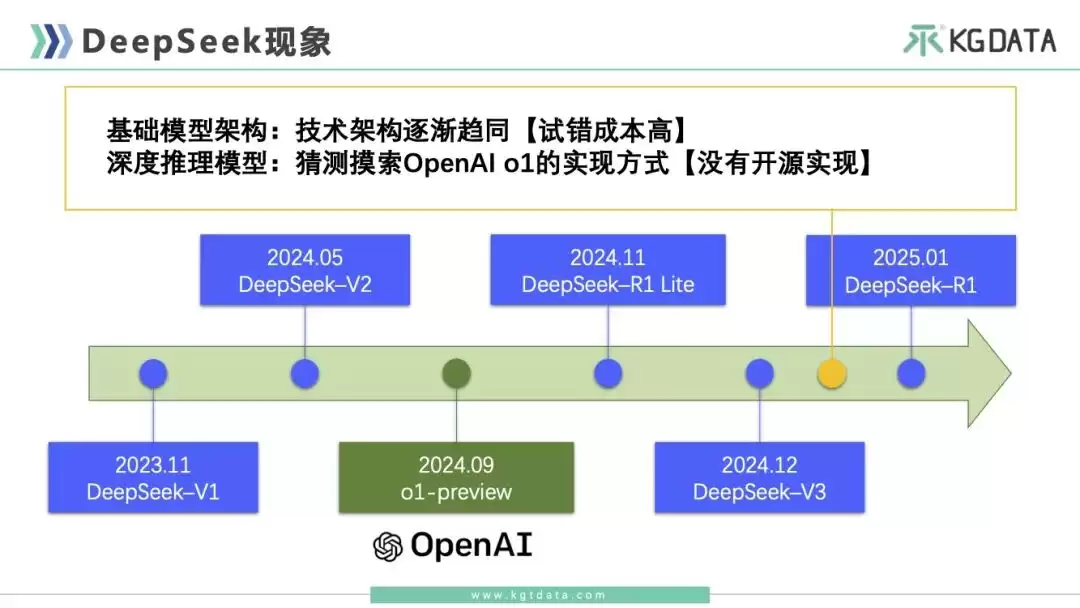
我们先梳理一下DeepSeek不同版本产品的时间线。2023年11月,DeepSeek发布了V1版本,当时知道的人非常少。2024年5月,DeepSeek V2发布,这个版本挺重要,因为它引发了第一场Token价格战。2024年11月,推理模型R1 Lite上线,我们12月初开始试用,当时它已经具备一定的数学和编程思考能力。2024年12月,DeepSeek V3发布,这是非常重磅的发布,在效率和性能方面表现突出,但此时还没引起AI界特别多的关注。直到2025年1月R1发布,才真正引发了全民出圈。
这里还要提一个重要背景:OpenAI o1预览版在2024年9月发布,这是业界第一个推理模型,其惊艳效果对整个大模型行业影响巨大。大家普遍认为,类似o1的后训练方式是未来方向。但问题在于,OpenAI始终没有公布足够的技术细节,之后很长一段时间里,没有哪家公司能复现和o1同等效果的模型。AI界苦苦等待了4个月。当DeepSeek R1出现并开源时,全球范围自然引起了巨大轰动。
从技术层面来看,DeepSeek R1引发轰动的原因有两点。第一,当时大模型技术架构逐渐趋同,每家企业在模型上的沉没成本很高,试错成本高,很难再用特别革命性的东西调整方向。第二,大家探索了很久,模型界也没出现任何能与OpenAI o1匹敌的产品,都处于混沌状态,猜测o1是如何实现的。所以当R1出现后,技术圈、企业圈引发了全球讨论,并逐步发酵出一些连带影响。
从多个角度观察,R1出圈的根本原因是效果好。一方面在榜单对比上效果很好,另一方面在业务实际使用中也非常出色。其次是极致的性价比,可以说它是大模型界的“小米”——效果优秀的同时,价格更便宜。同时它是开源的推理大模型,对整个大模型生态影响非常大,各家公司都可以用同样方式开发自己的推理模型或行业模型。最后是芯片卡脖子问题,DeepSeek提出的新架构,有可能让这个问题得到缓解。正是基于这些原因,DeepSeek成功取代了Meta,成为开源世界新的领头羊。
DeepSeek三大关键版本的核心技术分享
1、DeepSeek V2模型
先看DeepSeek V2的模型信息:总参数量236B,单个token推理激活参数量21B。参考下图右侧的坐标图,横坐标是单个token推理的激活参数量,纵坐标是效果。整体来看,DeepSeek远超大部分模型。与LLaMA 3 70B对比,每个token推理激活参数量不到其一半,效果却基本持平。和通义千问1.5 72B相比,参数量也是大幅减小。这就是DeepSeek打出第一波价格战的底气——把模型token价格降到极低水平。
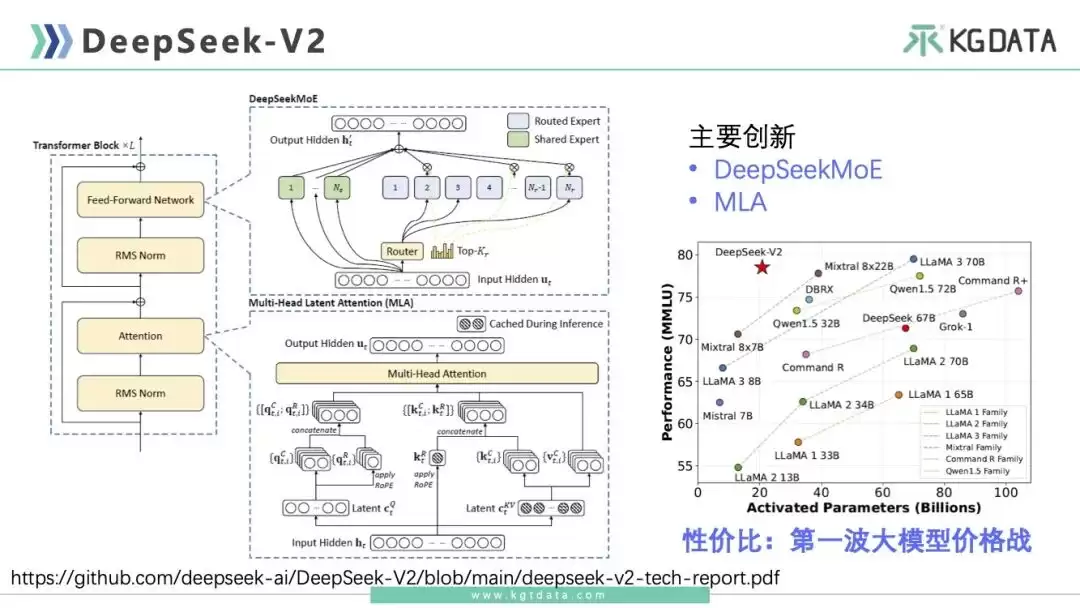
从DeepSeek V2发布的技术报告中,可以发现两大核心技术点创新:DeepSeek MoE和MLA。这两项技术都延续到了V3版本。
第一个创新点是MoE,即混合专家系统。它由多个专家组成,通过门控网络决定每个数据该由哪个专家训练,从而减轻不同类型样本间的干扰。模型做单次推理时,可以选择是否激活每个专家——全部激活就是稠密MoE,只挑选几个就是稀疏MoE。当前大部分MoE模型都采用稀疏方式。那么DeepSeek MoE有什么特点?它和Mistral MoE有哪些区别?
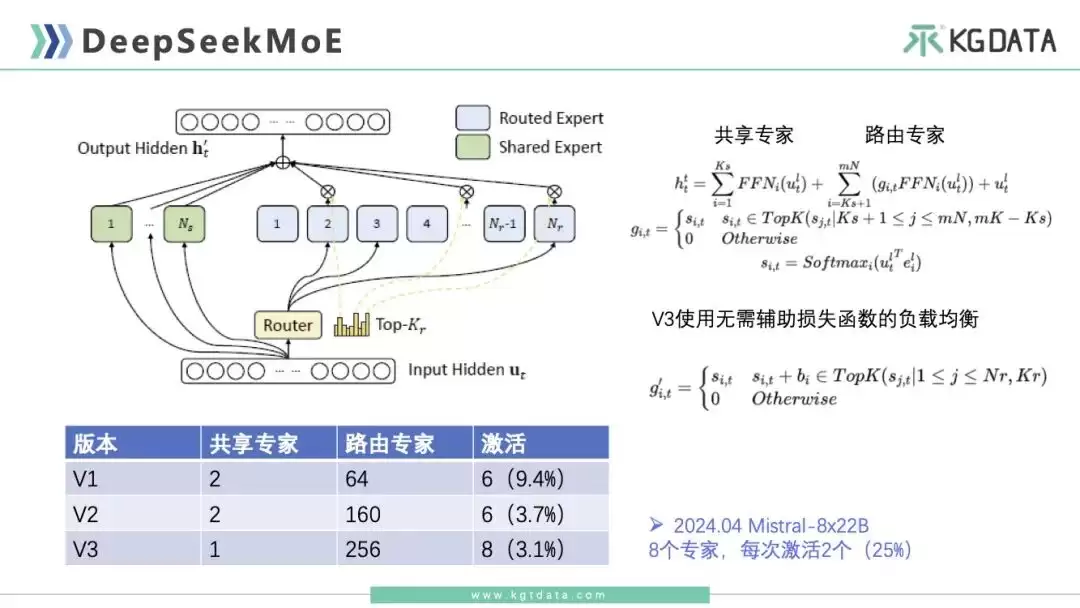
DeepSeek的专家分为两类:共享专家和路由专家。共享专家(图中绿色部分)每次推理固定激活;路由专家(图中蓝色部分)每次从中挑选几个激活。最终推理由两者共同完成。由于路由专家每次需要挑选,如果专家数少相对容易控制,但专家数多了会出现负载均衡问题。例如Mistral 8x22B有8个专家,每次挑选2个;而DeepSeek的路由专家数非常多,V3时大约有256个,每次从中选8个。如果没有严格控制,可能导致部分专家激活概率不均衡,造成信息过载或训练不足。所以负载均衡是MoE大模型要解决的核心问题。
DeepSeek MoE提出了一种相对创新的方法:采用无需辅助损失函数的负载均衡。借助这种方式,DeepSeek在V1阶段有2个共享专家、64个路由专家,每次激活6个,整体激活率9.4%;V2阶段增加到160个路由专家,每次激活6个,激活率降至3.7%;V3阶段只有1个共享专家、256个路由专家,每次激活8个,激活率仅有3.1%。比例一直在下降,模型效率逐步提升。相比之下,Mistral 8x22B从8个专家中激活2个,激活率25%,MoE比较稠密,推理效率不如DeepSeek高。
第二个技术创新点是MLA,即多头潜在注意力机制,由DeepSeek原创。这项技术可以提高Transformer模型在处理长序列时的效率和性能。通过MLA,DeepSeek将KV-cache缓存减少了93.3%,效果非常显著。
2、DeepSeek V3模型
DeepSeek V3除了包含V2的创新,还有三个新的技术点:第一是工程架构、系统架构层面,有很多软硬结合或纯硬件的创新;第二是FP8模型;第三是MTP多Token预测。
关于FP8,可以看下图左上角部分。FP8通过降低精度来极致提升模型计算性能。最深的色表示位数:FP32是32位,FP16是16位,FP8是8位。FP8的8位分为符号位、指数位和尾数位,一般有E4M3和E5M2两种方式。DeepSeek V3使用的是E4M3,即4位指数位和3位尾数位。精度最高的当然是FP32,因为小数位数多,表达数字更精确,计算误差小,但占空间大。FP8只占8位,是FP32的四分之一,所需空间显著减少,但位数少,精度会有影响。为了平衡精度和误差,DeepSeek在使用FP8模型时,对很多中间结果用FP32和FP16表示,涉及不少升维和降维的转换工作,详细内容可以看DeepSeek发布的技术报告。
关于MTP,就是多Token预测,可以看下图左下角。以前的Token预测是用户输入一句话后,只预测下一个Token。而MTP是一次预测多个Token:预测第一个Token后,结合它再预测第二个Token。比如一次预测三个Token,之后做验证,逐个判断每个Token是否正确,直到遇到错误,就把前面连续正确的部分输出。例如连续预测三个Token,主干网络认为前两个是对的,就会直接一起输出。
3、DeepSeek R1模型
接下来是业界关注最多的DeepSeek R1。从上图右侧众多测评集来看,DeepSeek R1的效果与OpenAI o1基本持平,有些场景甚至更好。
关于训练部分,看上图左侧。R1分为两个版本:R1 Zero和R1。R1 Zero纯用强化学习训练,R1则结合了强化学习和SFT。R1 Zero的训练中没有采用人类反馈的强化学习(RLHF),因为加入人类反馈过程慢、成本高,而是直接使用多轮强化学习迭代训练推理模型。但R1 Zero也存在一些问题,比如语言表达人类难以理解,语种使用混乱。所以DeepSeek在R1 Zero基础上做了优化:为了让强化学习效果更好,先做了一轮SFT,得到第一阶段模型;基于它再进行类似Zero的纯强化学习训练,同时加入语言一致性奖励,得到第二阶段模型;在此基础上再做一次SFT,这次的数据一部分是R1 Zero生成的60万COT数据,另一部分是非COT数据,共80万,得到第三阶段模型;最后基于第三阶段模型做全场景自动强化学习,最终得到DeepSeek R1。未来各大大模型公司会基于这个范式,对推理模型有更多新探索。
那么,没有人类参与的强化学习如何设置奖励模式?重点考虑两点:第一是准确性,直接看answer部分。因为奥数和算法编程都有标准答案,可以自动对比输出和标准答案判断是否正确,不需要人工标注。第二是输出格式,需要稳定输出“think”加“answer”的结构,以获得稳定推理结果,所以对格式也做了奖励。上图关于奖励部分有清晰的公式计算,最终得出每个结果是正向奖励还是负向奖励。由于DeepSeek公开了这些信息,可以看到这个模式非常清晰,未来在行业落地层面很有参考价值。
什么是“蒸馏模型”?简单来说,就是用前面提到的80万训练数据,在其他开源模型上做SFT,得到的模型就是R1的蒸馏模型。
如果把一个小模型分别用强化学习和蒸馏训练,效果差别有多大?例如同样针对千问32B,分别用R1 Zero的方式做纯强化学习训练和直接用蒸馏方式训练,效果差异非常明显。下图可以看到,蒸馏方式的效果远好于强化学习。
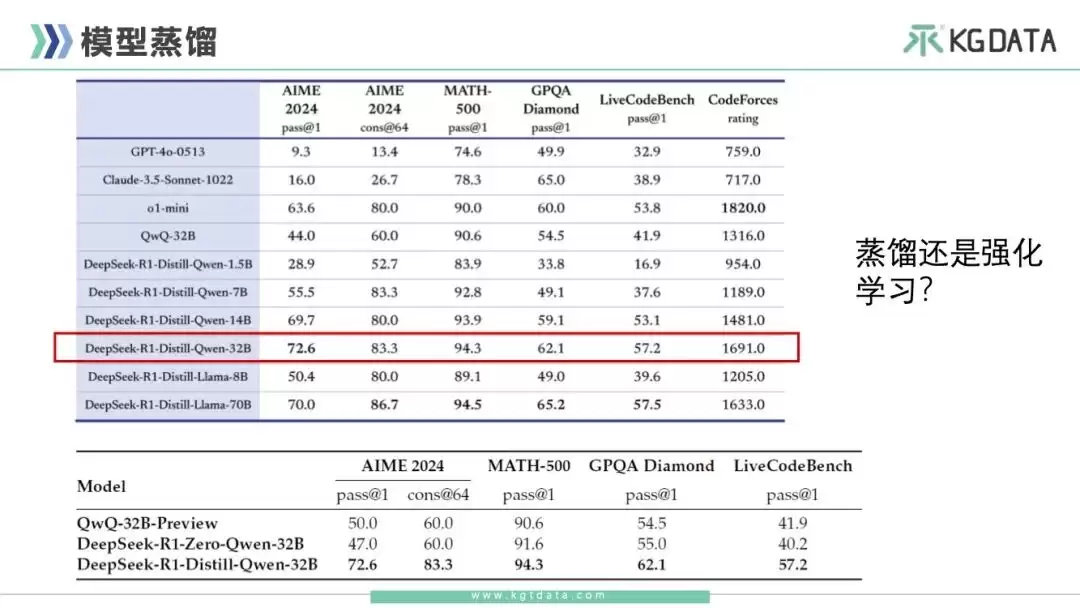
所以,未来大家在训练行业推理模型时,选择蒸馏还是强化学习,需要综合考量。目前最快的方式是蒸馏。但如果R1本身也无法得到准确回答,那一定也蒸馏不出好的小模型,这时就需要使用R1类似的训练方式。如果是私有化部署R1蒸馏模型,非常推荐DeepSeek-R1-Distill-Qwen-32B,综合性价比很高。部署成本也是大家比较关心的问题,除了网上公开信息,这里也有一份不同模型部署信息的整理图供参考。
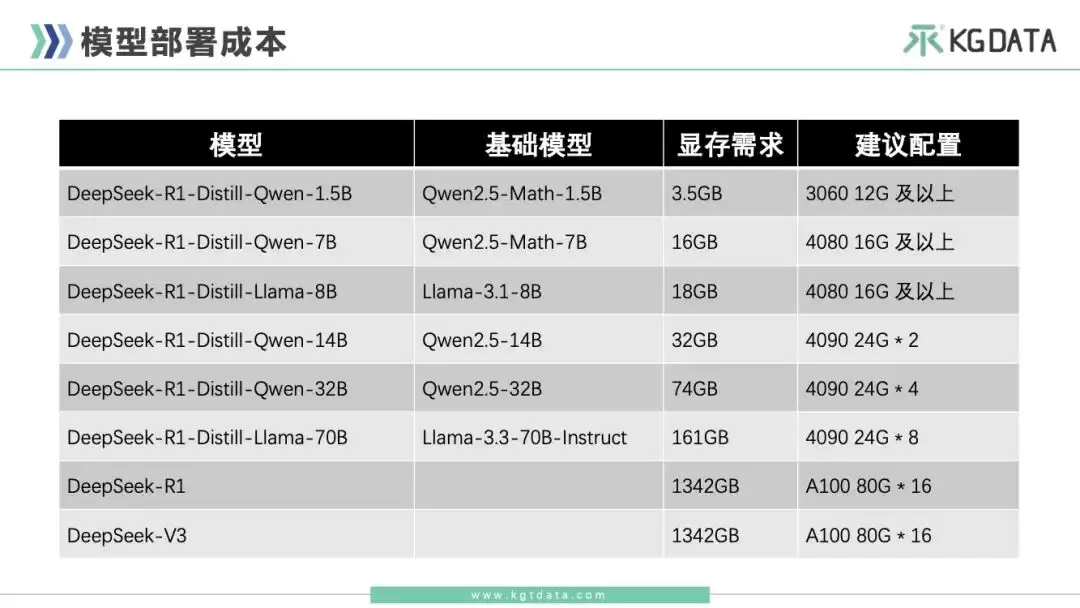
如果企业内部要私有化部署,一定要按需选择。目前单次投入的硬件成本非常高,满血版部署性价比最高的是8张H20(141GB版本)。
DeepSeek后续的影响
DeepSeek的出现无疑让AI技术又向前迈了一大步。关于AI落地,需要从应用端、模型端、生态端分别考量。
应用端,要考虑token变得廉价这件事。token成本显著降低,使得以前不挣钱的生意现在变得有利润了。商业模式会发生很大改变,或者说商业模式的估值发生了很大变化。典型的就是以消耗大量token为代价的商业模式,比如情感陪伴聊天类企业,会明显受益。
模型端,要考虑行业大模型该怎么训练。2024年等行业大模型主要还是在做基模,用行业数据做预训练和微调,但没有行业的推理大模型。现在有了DeepSeek的样板,会推动行业推理大模型的蓬勃发展,这应该是一个非常大的机会。
生态端,要考虑国产替换的问题。目前已经有很多国产芯片支持了DeepSeek,可以看到国产生态正在飞快地发展和完善。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:DeepSeek三大关键版本核心技术10分钟速览要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点GoogleMeet是面向商业与企业的视频会议服务,支持屏幕共享、实时字幕及与GoogleWorkspace集成,适用于项目讨论、网络研讨和线上教学等多种会议场景,具备扎实的安全与隐私保护。
Lanter是Chrome扩展,利用AI将YouTube视频语音转为带时间戳的文字笔记,支持一键抓取高光、自动标点排版、书签管理、全局搜索及每日邮件汇总,方便高效回顾视频关键内容。
一款AI驱动的Chrome扩展音频笔记应用,支持录音自动转文字、标签分类与全文搜索,将语音转化为可检索的数字资产,显著提升信息定位与管理效率。
专为GoogleMeet设计的AIChrome扩展,实时转录会议内容,自动生成摘要并提取行动项与决策,无缝同步至Google文档、任务及Gmail,省去手动整理时间,显著提升协作效率。
- 日榜
- 周榜
- 月榜
热点快看