




OpenAI o1大进步小技巧新思路详解

历经长达近一年的等待,从神秘的Q*到代号“草莓”,再到AGI与GPT-5的传言频频涌现,核心团队成员陆续变动,OpenAI终于在2024年9月12日推出了全新的推理模型o1。此次同时发布了预览版o1-preview和轻量级版本o1-mini。这款备受瞩目的产品,其意义远非一次常规的版本迭代——它所带来的深远影响,需要从技术、商业与未来趋势等多个维度进行深度剖析。

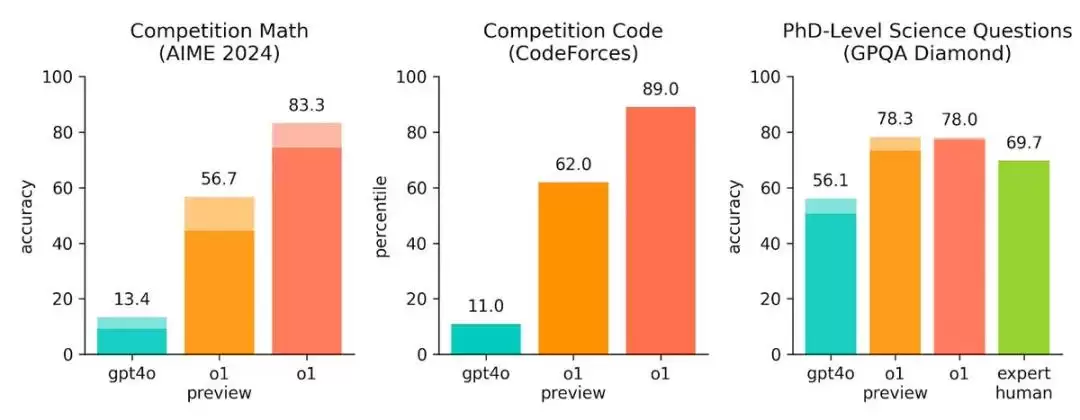
实事求是地说,这是模型能力的显著跃升。与GPT-4o相比,o1-preview在数学与编程领域的性能提升了超过5倍,而尚未完全释放的完整版o1更是实现了8倍以上的增长。在博士级别的科学题目测试中,其准确率已超越人类专家水平。在国际数学奥林匹克资格考试中,GPT-4o的正确率仅为13%,而新的推理模型一举达到了83%。在Codeforces编程竞赛中,它的表现超过了89%的人类参赛者。面对如此惊人的数据,便不难理解奥特曼此前对实现通用人工智能(AGI)所展现出的坚定信心。
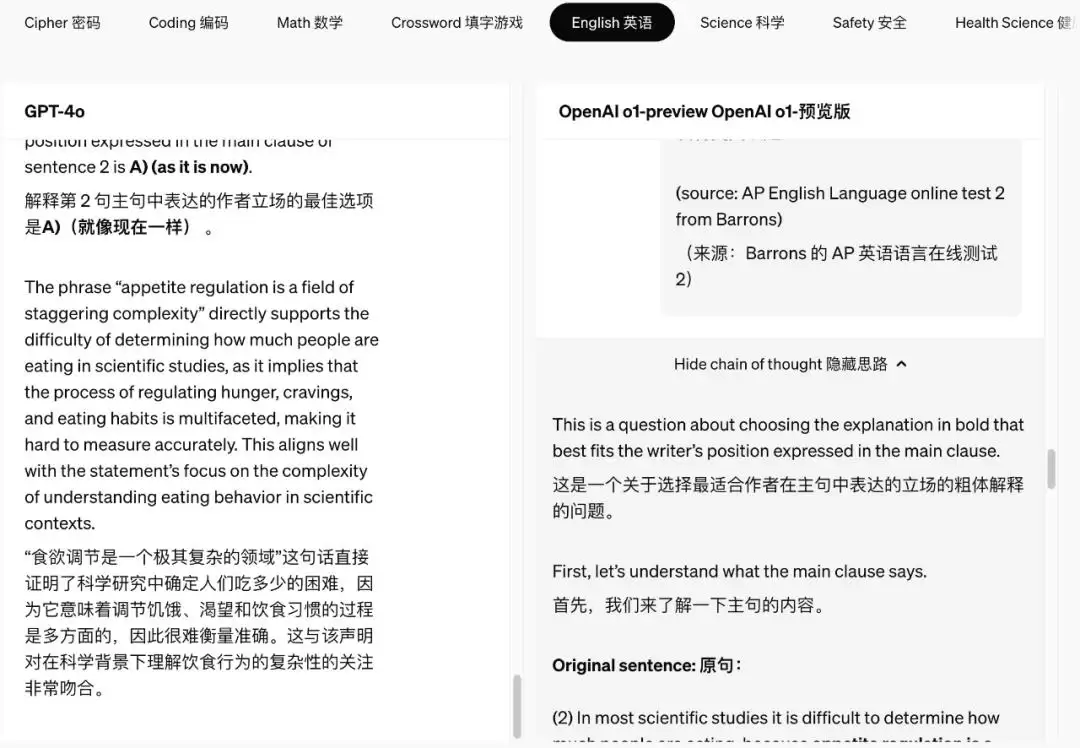
在实际操作中,模型的推理过程与以往截然不同。界面上新增了一个可开关的“显示思路”(Show chain of thought)框,完整呈现了模型的思考链条。这类似于人类面对复杂问题时先深思熟虑的步骤——o1会将问题拆解,逐步推敲,每一步都进行反复校验,一旦发现错误便另辟蹊径继续探索。这种“慢思考”模式,极大地增强了其推理能力。
在这些令人振奋的性能数字背后,一系列被业界长期猜测和讨论的技术突破,终于得到了官方验证。
1、思维链
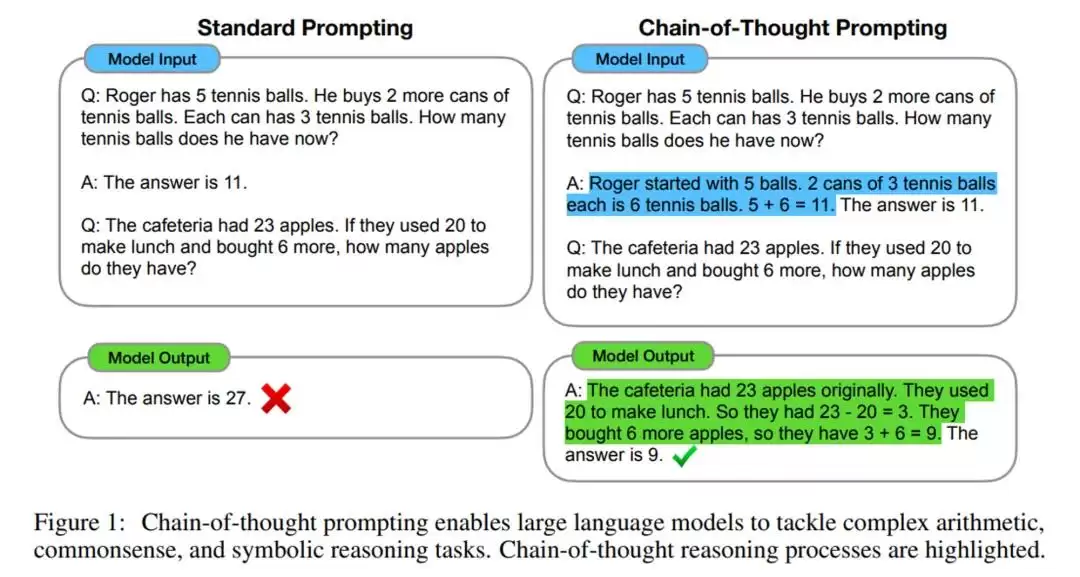
思维链(Chain of Thought,CoT)这一技术,早在两年前就在数篇经典论文中展现了其强大潜力。其核心思想简洁明了:在向大模型提问之前,先在提示词中嵌入几个包含完整思考过程的问答示例(Manual CoT),模型便能在推理任务上实现显著的性能飞跃。
随后,论文《Large language models are zero-shot reasoners》进一步提出,只需在提示词开头加入一句“Let's think step by step.”(即后来广为人知的“一步一步慢慢来”咒语),模型便能够自主生成推理过程(Zero-shot CoT)。

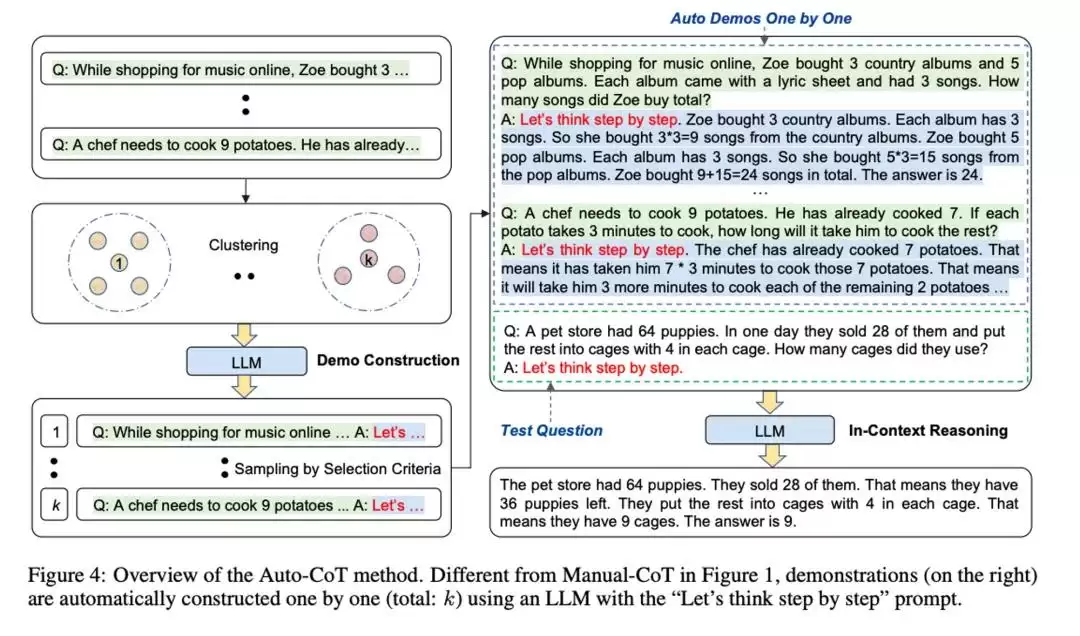
再后来,《Automatic Chain of Thought Prompting》巧妙地将两者融合:先使用咒语生成推理过程,再将这些过程作为示例嵌入提示词中,既节省了人工成本,又保障了推理效果的可靠性。
此后,CoT衍生出众多变体,但其核心逻辑始终未变:通过精妙的提示词设计,引导模型进行分步思考。于是,一个自然而然的追问随之而来:我们能否让大模型自主学习并内化这种推理方法?
2、强化学习和自学推理
这就引出了强化学习——如同当年的Alpha-Zero,强化学习使机器通过与环境的互动及对结果的观察,不断调整自身的行为策略。然而,此前这一方法论难以应用于语言模型。直到2022年,斯坦福大学提出了“自学推理”(STaR)方法:首先向模型提供一系列例题的详细解法,然后让它尝试解答更多问题,若解答正确,则将该解法补充进例题集,形成新的训练数据,再对原始模型进行微调。
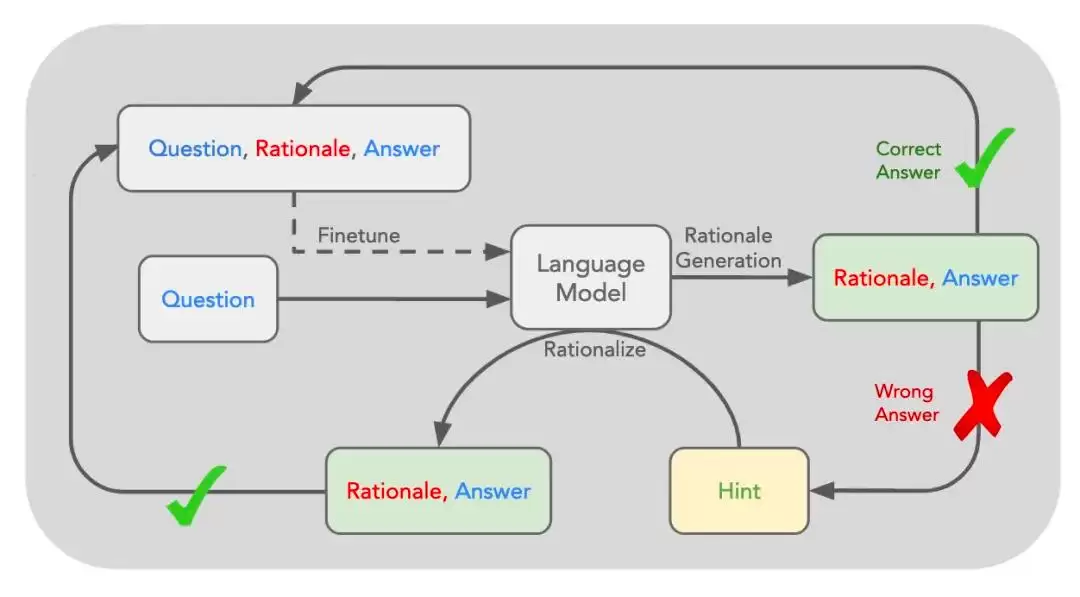
在此基础上,进一步进化出了“安静的自学推理”(Quiet-STaR),也就是传闻中的Q*。其核心思路是:在每个输入的token之后插入一个“思考”步骤,让模型生成内部推理,系统再评估这些推理对预测后续文本是否有帮助,并据此调整模型参数。这使得模型在处理各类文本时,都能进行隐含的推理,而不仅仅局限于回答问题。
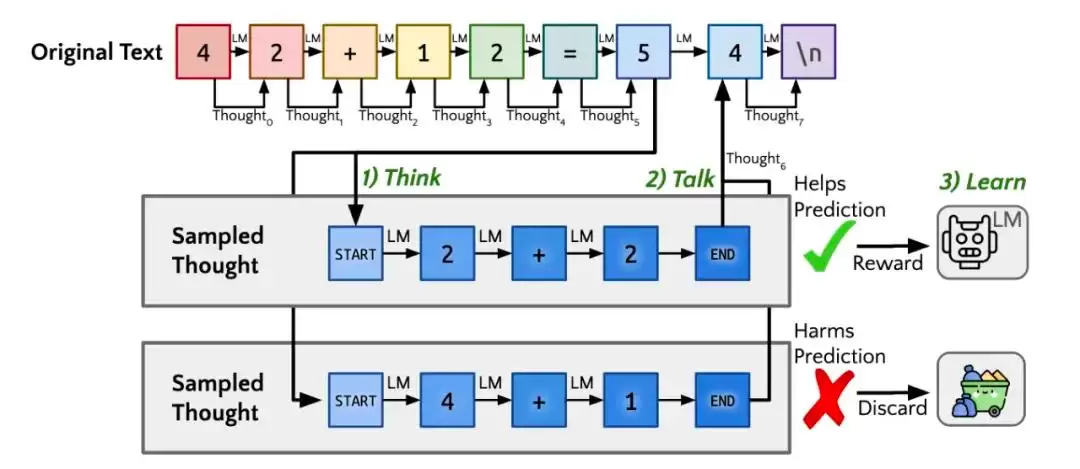
通俗地讲,这相当于在训练大模型时就教授它一系列“解题套路”——当然,这些套路也是模型自身生成并优化筛选的。在思考时,它会根据问题类型直接选择相应套路,进行问题分解、按步骤执行、反复审核,一旦失效便切换策略。这与教授小学生奥数的思路颇为相似。然而,这种自学习机制由于奖励模型较为复杂,目前主要在数学和代码领域表现出色。
3、Scaling Law的延伸
上述技术的结合,带来了一个显著变化:预训练阶段的算力投入相对稳定,但推理阶段的计算量大幅增加。原本追求“快思考”的模式,现在转变为有意放慢速度,以换取更精确的结果。
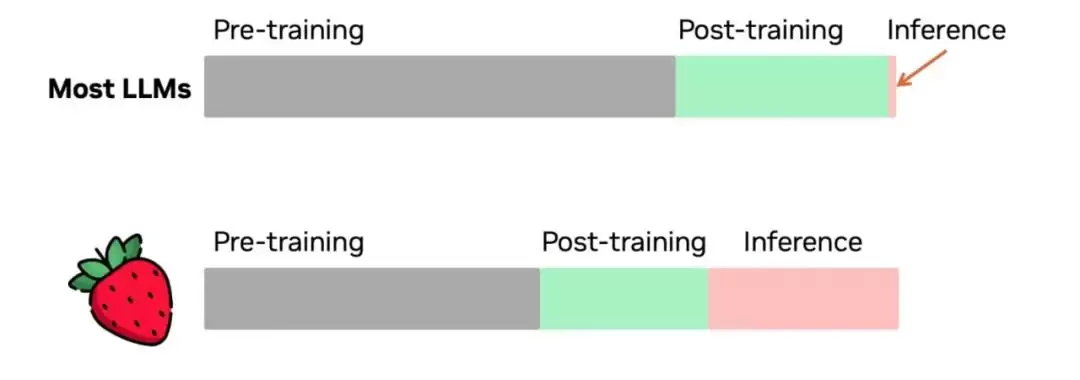
OpenAI在训练过程中观察到,随着强化学习(训练时计算)和思考时间(推理时计算)的增加,o1的性能能够持续提升。
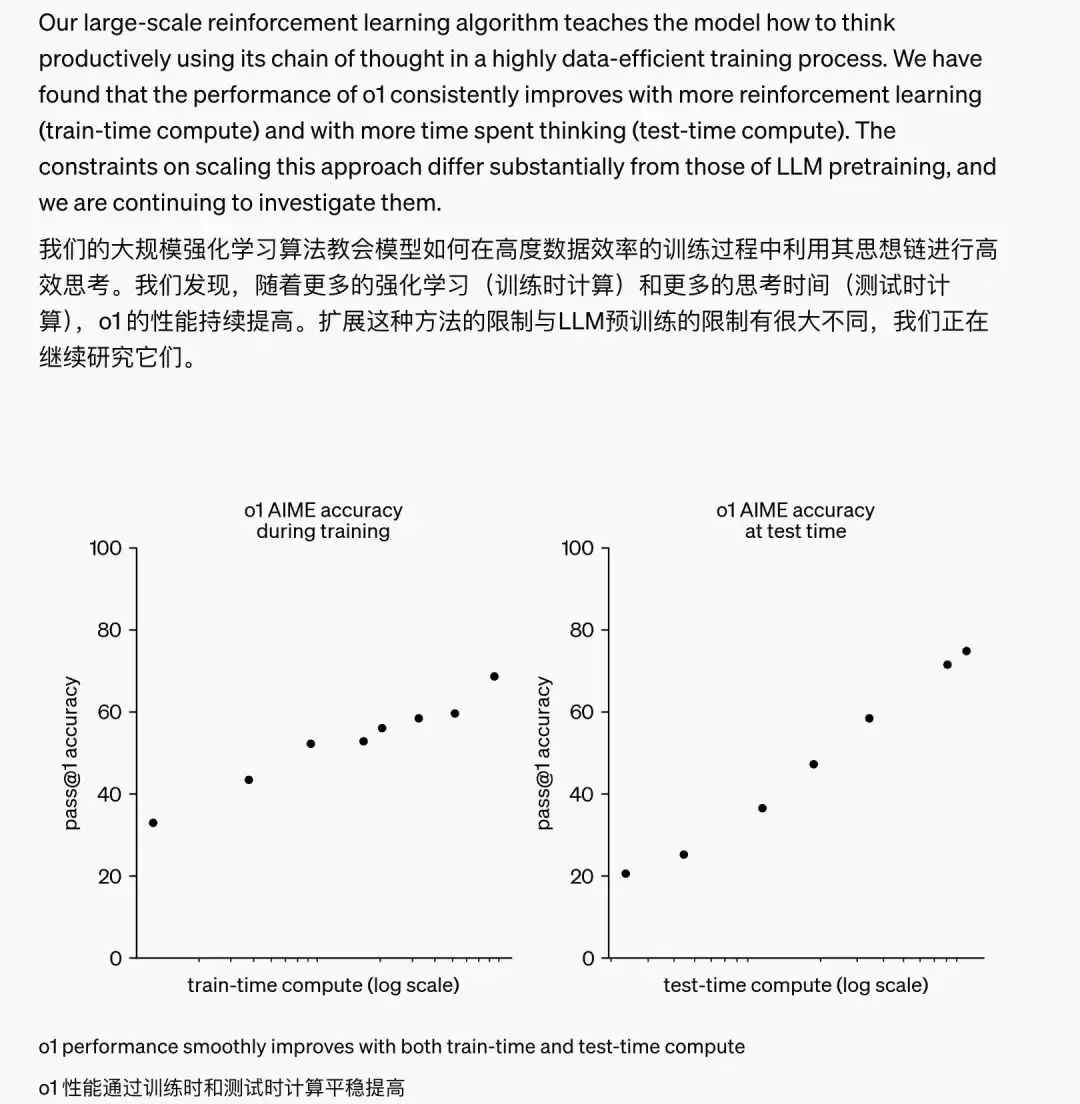
英伟达人工智能研究领导者Jim Fan在X平台上点评道:模型不再仅仅遵循训练层面的Scaling Law,还拥有了推理层面的Scaling Law。两条曲线共同增长,将突破此前大模型所面临的能力瓶颈。他感慨:“此前,无人能够将AlphaGo的成功复制到大模型上——即通过增加计算量让模型迈向超人能力。如今,这一页已经翻过去了。”
可以预见,在预训练边际成本逐渐下降的背景下,基于强化学习的推理增强将愈发受到重视,也会有更多算力被投入到推理环节。全球人工智能芯片与算力的需求,将持续攀升。
二、小技巧
不可否认,o1代表了人工智能领域的一次重要进步。然而,回顾过去一年奥特曼的言行,以及OpenAI组织架构与核心团队的变动,不免引发一些疑虑:这个故事是否被过度渲染?是否存在一系列技巧性操作,用以维持公司估值的增长与资源的获取?
1、技术壁垒
无论是Sora还是o1,本质上都是基于已有科研成果的工程创新,并未构筑起难以逾越的技术壁垒。OpenAI最大的贡献,仍然在于坚定且不计成本地率先进行大规模实践。与Sora类似,一旦方向得到验证,工程复现大概率只是时间问题。而OAI要在所有方向上保持全球领先,几乎是一项不可能完成的任务。更何况,从近几周全网的测试反馈来看,模型效果只能说表现尚可,在许多场景下甚至不如其他工程手段下的思维链结果(例如Claude3.5),有时仅仅是概率稍高的“抽卡”行为,其实际应用价值仍有待商榷。此外,或许是为了防止友商窥探与抄袭,或是因为开放的思维过程存在安全隐患,OpenAI并未向用户开放完整的思维链细节。然而,已有研究者在很短时间内宣称复现了类似的推理能力。
可以预见,后续各大厂商都将开始围绕推理能力展开竞争,陆续推出“深思熟虑”版的模型,快速拉齐技术水平。如果OpenAI后续再无真正的底牌,依然难以扭转本轮模型竞赛中可能面临的增长瓶颈。
2、成本
去年已基本完成的模型之所以拖延至今才面世,除了众所周知的安全原因外,很可能是因为o1与Sora一样,算力消耗过于巨大,尚不具备大规模商业化的可行性。面对这一挑战,奥特曼团队一直在尝试寻求解决方案。他们等待了相当长的时间,期待算力成本能随技术进步而下降,同时在全球范围内积极融资,购买或租赁更多的计算资源。然而即便如此,最终推出的产品单次推理往往需要数分钟甚至数十分钟,单价是4o的数倍,token消耗也经常成倍增长。
这导致了一个尴尬的局面:其科研贡献暂时远大于商业价值。在此背景下,OpenAI的行业地位与估值能否维持,变得充满不确定性。高昂的研发与运营成本,加上商业化进程受阻,可能会影响投资者的信心与市场预期。
3、方法论
如果说前两点商业视角的质疑对一路引领行业的OAI有些不公平,那么这种方法是否真的如其所说,能够达到甚至超过各STEM领域的“博士水平”?这同样值得深入探讨。从原理上看,这种思路仍然是在“大力出奇迹”的Scaling Law基础上继续叠加buff——引入类似蒙特卡洛树搜索的暴力方法,进行多路径尝试推理。某种意义上,这是用文科式的广度探索来解决理科问题。类似于早期的AutoGPT类应用,面对复杂问题,如果不对思维链的搜索空间进行严格限制和引导,可能会陷入无边无际的发散,消耗大量算力却仍无法得到有效结果。
正如前文提到的,这种方法有些类似于面向普通学生的“普奥”中常用的套路式教学——更多依赖记忆与模式匹配,而非对问题本质的深刻理解与创造性思维。以“9.11和9.8哪个大”这类简单问题为例,它还需要琢磨半天,且有相当概率答错。由此培养出的AI,恐怕更像一个只会刷题与刷分的“小镇做题家”,而非真正具备洞见与创新能力的“博士”——毕竟“做题”过程的训练数据更容易获取。
诚然,现实中的大量科研工作确实涉及重复性、机械性的任务,这部分如果由AI承担,将能极大提高效率。但科研的核心在于创新,在于对未知问题的探索与新知识的发现。这需要灵感、创造力与逻辑推理能力,而非单纯的计算能力。
正如论文《Large Language Monkeys: Scaling Inference Compute》所指出的:仅仅通过增加生成样本来扩展推理计算,本质上并未改变大型语言模型的基本属性——它仍然是一个基于统计概率“打字”的“猴子”。要实现真正的通用人工智能,实现在科学领域的突破性进展,我们可能需要在算法与架构上寻求更加本质的创新,而非简单地堆砌算力。
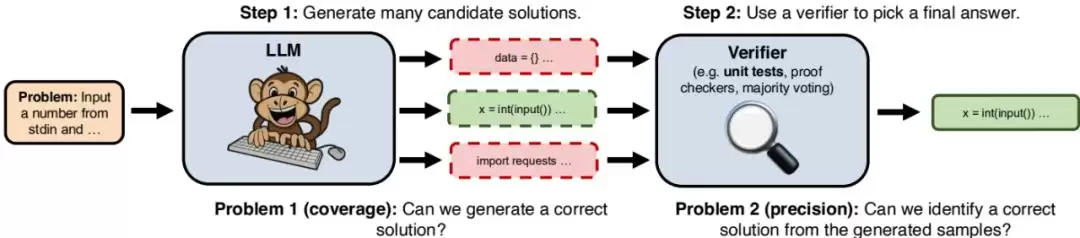
三、新思路
前面既给予了肯定,也指出了不足。但从更深层面看,这些都不是o1最重要的价值。虽然OpenAI官方可能并未重点强调,但在材料中多次提及一个关键点:o1更适用于科学、编码、数学这类复杂问题中的繁琐工作,尤其是多步归纳或演绎推理。例如,“医疗保健研究人员可以用o1注释细胞测序数据,物理学家可以用o1生成量子光学所需的复杂数学公式,所有领域的开发人员可以用o1构建和执行多步骤工作流程。”
此前,我们对人工智能的期待,往往是一个模型既具备知识,又拥有智力,甚至还要融入情感与创意——结果是模型参数量和算力不断攀升。但或许这些目标需要用不同的方法去分别解决,有些甚至需要非技术手段。o1的未来或许确实会以某种方式提升多模态模型的世界理解能力,但其核心价值,恰恰在于它是一个与世界知识大幅解耦的推理模型。这一点在o1-mini上体现得更为彻底:作为低成本小模型,它尤其擅长编程这类不需要过多世界知识、但依赖多步骤严谨推理的任务。
人类学习的过程,通常是先大量吸收知识,通过神经元的广泛激活与连接形成智力,而具体的细节知识往往会随时间被淡忘——这有点像张无忌学习太极拳的过程。在解决不同问题时,除了语言理解和逻辑推理能力,我们还需要可信知识的查阅引用、灵感创意的涌现、情感的人际连接与感应……人工智能的未来也不会只是一个单一的大模型,而将变得越来越“稀疏”、灵活,甚至演变为一套人机协同的全新机制。“做题”能力无疑是必要的,但掌握了做题,距离真正解决实际问题,仍有相当长的路要走。
o1的出现,或许预示着这样一个“能力稀疏化”的趋势。未来的人工智能,将从一个单一的大模型,逐步演化为知识、推理、创意、情感等不同能力模块的灵活组合,并与人类形成更紧密、高效的协作。o1只是一个开始,期待百花齐放的未来。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Claude Token节省十大实用技巧方案
通过编辑而非追加消息、每15-20条消息开新对话、合并问题、利用Projects缓存、预设记忆、关闭附加功能、按任务选择模型、分散时段、避开高峰及开启超额使用,能有效减少上下文重读,节省Token。

硅基流动冲刺Token工厂第一股亏损反更值钱?
硅基流动冲刺港交所“Token工厂第一股”,2025年营收5533万元,净亏损3 45亿元,毛利率-24%。两条业务线分化:公有云服务亏损严重,本地部署毛利率达82 5%。依赖中立第三方定位吸引资本,但面临原厂降价、大厂竞争及供应链风险,估值77亿背后存隐忧。

AI Agent的真正价值在于长在业务流程中
AIAgent需嵌入企业业务流程,而非仅作聊天工具。以零售品类管理为例,通过趋势识别、选品与货架规划,预计可带来2%—5%销售提升及10%P&L改善。设计需模块化、可整合,确保可解释性,重新界定人、AI与工具的关系。

后张雪峰时代大厂抢滩AI志愿填报
AI高考志愿填报工具在大厂推动下普及,能快速整合信息、生成方案,但存在数据幻觉、同质化风险。它无法替代张雪峰式实用主义建议和信誉责任,志愿填报仍需个性化判断与深度信息。

阿里禁用Anthropic全系产品的理性风控决策
阿里自7月10日起全员禁用Anthropic全系产品,因其ClaudeCode被发现存在隐蔽身份识别与隐写标记机制,且Anthropic曾指控阿里进行模型蒸馏。此举源于安全信任崩塌、中美AI博弈加剧,阿里同步换装自研工具Qoder,推动国产AI编码工具替代。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 06:48
2026-07-04 06:48
热门教程
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 06:48
2026-07-04 06:48
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
