




GPT-4o mini更小更强 AI模型未来不再越大越好

我们也曾揭秘负责运作苹果智能的幕后功臣,其中经过微调的 3B 小模型专用于摘要、润色等任务,在经过适配器的加持后,能力优于 Gemma-7B,适合在手机终端运行。

有意思的是,前 OpenAI 大神 Andrej Karpathy 最近也做出了一个判断:模型尺寸的竞争将会“反向内卷”——不是越变越大,而是比谁更小、更灵活。
小模型凭什么以小胜大
Andrej Karpathy 的预测并非空xue来风。
在当下这个数据为王的时代,模型正以惊人的速度变得庞大和复杂。经过海量数据训练出来的超大模型(比如 GPT-4),其实大部分算力都用来“死记硬背”那些无关紧要的细节了。
反观经过微调的小模型,反而能在特定任务上实现“以小胜大”,好用程度不输给那些庞然大物。
Hugging Face 的 CEO Clem Delangue 也曾放话:多达 99% 的使用场景都可以用小模型来解决,他甚至预测 2024 年会是小型语言模型的天下。
要理解这里面的门道,得先科普一些知识。
2020 年,OpenAI 在一篇论文中提出了一个著名的定律:Scaling law。简单说就是,模型越大,性能越强。随着 GPT-4 等模型的推出,这一点也确实得到了验证。
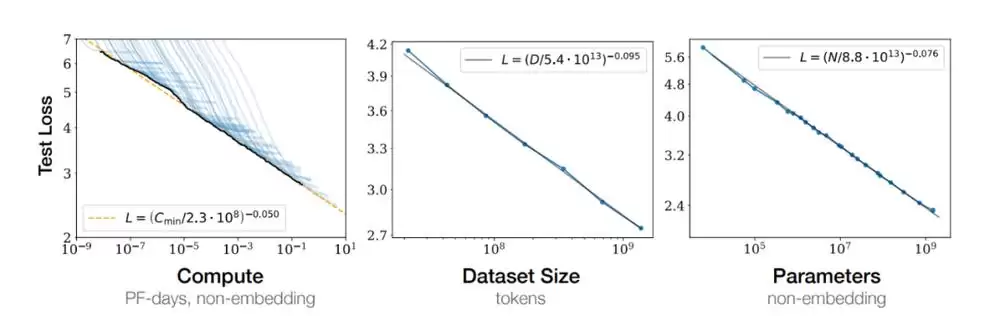
很长一段时间里,AI 领域的研究者和工程师笃信,只要不断增加参数数量,模型的学习能力和泛化能力就能持续提升。于是,我们见证了模型规模从几十亿参数跃升至几千亿,甚至朝着万亿大关一路狂奔。
不过,模型的规模真的是衡量智能的唯一标准吗?
答案是否定的。一个设计精巧的小型模型,通过优化算法、提升数据质量、采用先进的压缩技术,完全可以在特定任务上达到与大型模型匹敌甚至更优的效果。这种“以小博大”的策略,正成为 AI 领域的新风向。而提高数据质量,就是其中一条关键路径。
Coalesce 的首席技术官兼联合创始人 Satish Jayanthi 这样形容数据对模型的作用:
“为了产出高质量的结果,大型语言模型需要接受针对特定主题和领域的高质量、有针对性的数据训练。就像学生需要优质的教材一样,LLM 也需要优质的数据源。”

不再一味信奉“大力出奇迹”的暴力美学,清华大学计算机系长聘副教授、面壁智能首席科学家刘知远提出了一个很有意思的概念——大模型时代的“面壁定律”:模型的知识密度正以平均每 8 个月翻一倍的速度提升。
知识密度 = 模型能力 / 参与计算的模型参数。
刘知远打了个比方:如果给你 100 道智商测试题,你的得分不仅取决于答对多少,更取决于你完成这些题目动用了多少“神经元”。用更少的神经元完成更多任务,才叫真聪明。
这正是知识密度的核心理念。举个例子:相比 OpenAI 2020 年发布的 1750 亿参数的 GPT-3,2024 年面壁智能推出的 MiniCPM-2.4B,在实现同等性能的前提下,参数仅为 24 亿,知识密度提高了大约 86 倍。
多伦多大学的一项研究也表明,并非所有数据都是必要的。从大型数据集中识别出高质量的子集,不仅更容易处理,还能保留原始数据集的全部信息和多样性。即便去掉高达 95% 的训练数据,模型在特定分布内的预测性能也不会受到显著影响。

近期最典型的例子当属 Meta 的 Llama 3.1 大模型。Meta 在训练 Llama 3 时,喂了 15T tokens 的数据,但负责训练的 Meta AI 研究员 Thomas Scialom 却直言:网络上的文本充满了无用信息,基于这些冗余数据进行训练,纯粹是浪费计算资源。
除了数据质量,“知识蒸馏”也是小模型“以小胜大”的重要法宝。
所谓知识蒸馏,就是用一个大型的“教师模型”去指导一个小型的“学生模型”训练,从而将大模型的强大性能和泛化能力,迁移到更轻量级、运算成本更低的小模型身上。

Llama 3.1 发布后,Meta 的 CEO 扎克伯格也在长文中着重强调了微调和蒸馏小模型的重要性。业内普遍认为,Llama 3.1 的 8B 和 70B 版本,正是由超大杯版本的模型蒸馏而来,这才实现了整体性能的显著跃迁和效率提升。
另外,模型架构本身的优化也至关重要。比如 MobileNet,它的设计初衷就是在移动设备上实现高效的深度学习模型。
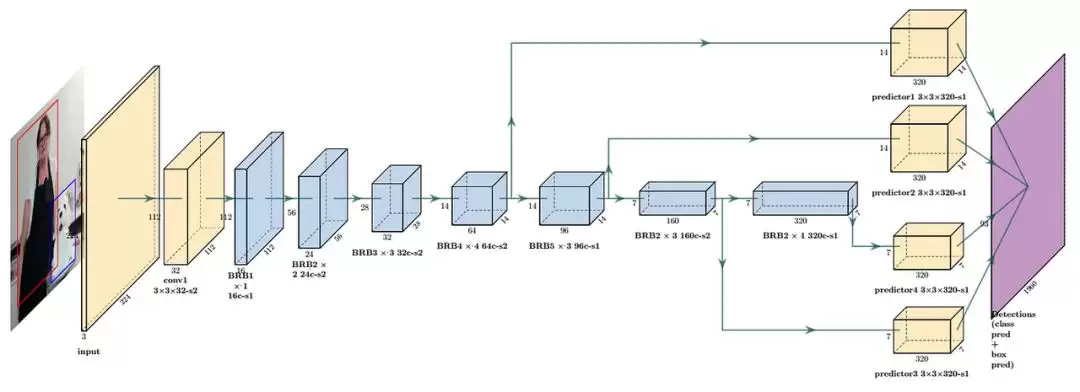
MobileNet 通过深度可分离卷积,大幅减少了参数数量。对比之下,MobileNetV1 的参数比 ResNet 少了约 8-9 倍。参数少了,计算自然更高效,这对于资源受限的环境,比如手机,意义非凡。
尽管技术层面不断进步,AI 行业本身仍然面临着长周期投入、高成本和回报周期长的挑战。
据《每日经济新闻》不完全统计,截至今年 4 月底,国内共推出了约 305 个大模型,但截至 5 月 16 日,仍有大约 165 个大模型尚未完成备案。百度创始人李彦宏也公开批评,认为当前众多基础模型的存在是对资源的浪费,主张应将更多资源用于探索模型与行业结合的可能性,以及开发下一个潜在的超级应用。

这正是当前 AI 行业的核心矛盾:模型数量激增,与实际应用落地之间很不匹配。
面对这种局面,行业的焦点逐渐转向加速 AI 的落地应用。而部署成本低、效率高的小模型,自然成了更合适的破局点。
一些专注于特定领域的小模型也开始涌现,比如烹饪大模型、直播带货大模型。这些名头虽然听起来有点唬人,但方向是对的。
简而言之,未来的 AI 不会是单一、庞大的存在,而是会更加多样化、个性化。小模型的崛起,正是这一趋势的体现。它们在特定任务上展现出的卓越性能,证明了一件事:“小而美”同样值得尊重和认可。
One more thing
如果你想在 iPhone 上提前跑模型,不妨试试 Hugging Face 推出的那款名为“Hugging Chat”的 iOS App。
借助合适的网络环境和外区 App Store 账号下载该 App 后,你就可以访问和使用各种开源模型了,包括 Phi 3、Mixtral、Command R+ 等。
温馨提醒一下,为了获得更佳的体验和性能,建议用最新一代的 Pro 版 iPhone。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Claude Token节省十大实用技巧方案
通过编辑而非追加消息、每15-20条消息开新对话、合并问题、利用Projects缓存、预设记忆、关闭附加功能、按任务选择模型、分散时段、避开高峰及开启超额使用,能有效减少上下文重读,节省Token。

硅基流动冲刺Token工厂第一股亏损反更值钱?
硅基流动冲刺港交所“Token工厂第一股”,2025年营收5533万元,净亏损3 45亿元,毛利率-24%。两条业务线分化:公有云服务亏损严重,本地部署毛利率达82 5%。依赖中立第三方定位吸引资本,但面临原厂降价、大厂竞争及供应链风险,估值77亿背后存隐忧。

AI Agent的真正价值在于长在业务流程中
AIAgent需嵌入企业业务流程,而非仅作聊天工具。以零售品类管理为例,通过趋势识别、选品与货架规划,预计可带来2%—5%销售提升及10%P&L改善。设计需模块化、可整合,确保可解释性,重新界定人、AI与工具的关系。

后张雪峰时代大厂抢滩AI志愿填报
AI高考志愿填报工具在大厂推动下普及,能快速整合信息、生成方案,但存在数据幻觉、同质化风险。它无法替代张雪峰式实用主义建议和信誉责任,志愿填报仍需个性化判断与深度信息。

阿里禁用Anthropic全系产品的理性风控决策
阿里自7月10日起全员禁用Anthropic全系产品,因其ClaudeCode被发现存在隐蔽身份识别与隐写标记机制,且Anthropic曾指控阿里进行模型蒸馏。此举源于安全信任崩塌、中美AI博弈加剧,阿里同步换装自研工具Qoder,推动国产AI编码工具替代。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 06:48
2026-07-04 06:48
热门教程
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:54
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 14:53
2026-07-04 06:48
2026-07-04 06:48
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
