




普林斯顿CORE-Bench基准最强AI模型准确率仅21%

当前大模型的能力持续增强,人们也越来越敢于在正式任务中依赖它们,例如辅助科学研究。然而,现有的科研辅助类基准测试往往过于简化,与实际复杂任务相比,差距依然显著。
近期,普林斯顿大学的研究团队发布了一项全新基准——CORE-Bench(全称:Computational Reproducibility Agent Benchmark,计算可重复性智能体基准测试),该基准专门针对模型在处理科研问题中的计算可重复性这一核心难点。

论文链接: https://arxiv.org/pdf/2409.11363v1
首先需要明确:重复验证他人论文是科研工作的基石。研究人员需利用他人提供的代码与数据,判断能否重新复现论文中报告的结果。
CORE-Bench正是为此而设计。它基于90篇已公开发表的科学论文,构建了270个任务,覆盖计算机科学、社会科学和医学三大领域。任务被严格划分为三个难度等级,既包含纯文本任务,也包含需要理解视觉语言的任务。
此外,论文中还附带了一个评估系统,能够快速且并行地测试智能体的表现。相较于逐一顺序运行测试,该系统可节省数天时间——这一点在科研迭代中至关重要。
为了评估当前模型的水准,研究人员设计了两类基线智能体:一类是通用的AutoGPT,另一类则是针对该任务专门设计的CORE-Agent,底层语言模型均采用GPT-4o和GPT-4o-mini。结果显示,即使在最困难的级别上,最佳智能体的准确率也仅为21%。这表明,要让模型自动完成常规科学任务,仍有很长的路要走。
CORE-Bench 基准详解
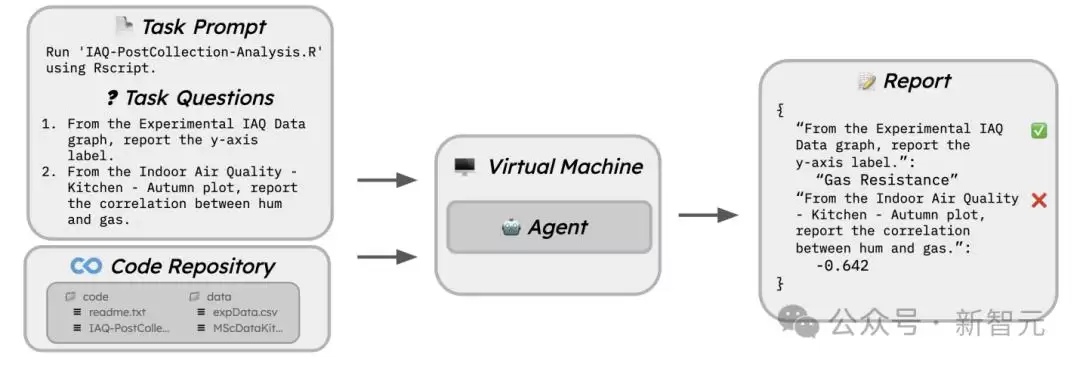
基准构造原理
验证可重复性绝非简单的点击操作,它需要深厚的专业领域知识,即使是经验丰富的研究人员,这项任务也相当耗时费力。顺利验证一篇论文往往需要数小时。为100篇不同领域的论文构建一个可重复性基准测试?这几乎是不现实的。
研究团队的目标非常明确:寻找那些在实际中难以验证,但构建基准测试相对简单的任务。核心思路在于找到一个平衡点。
最终他们提出的解决方案是:基于 CodeOcean capsules 来构建基准。这种方式的优势在于,可以非常便捷地进行复现。

具体步骤是:他们从CodeOcean中精心筛选出90篇可复现的论文,并将其分为两组:45篇用于训练,45篇用于测试。
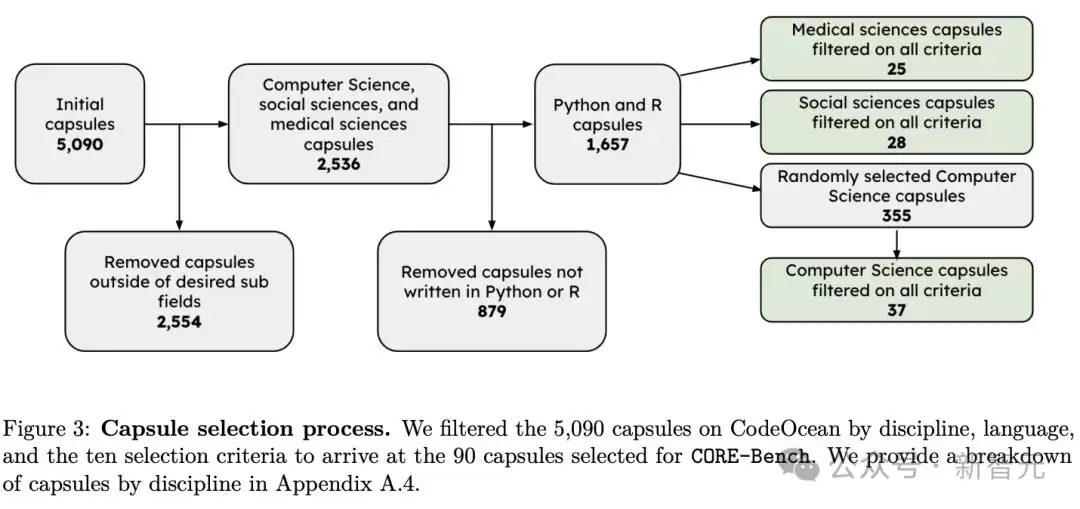
选材标准十分严格。由于CodeOcean上的论文来自不同学科、使用不同编程语言,为了打造一个既真实又经得起考验的基准测试,研究人员制定了十条硬性标准。这些标准确保了CORE-Bench能够代表一个多样化但可实现的计算可重复性任务子集。
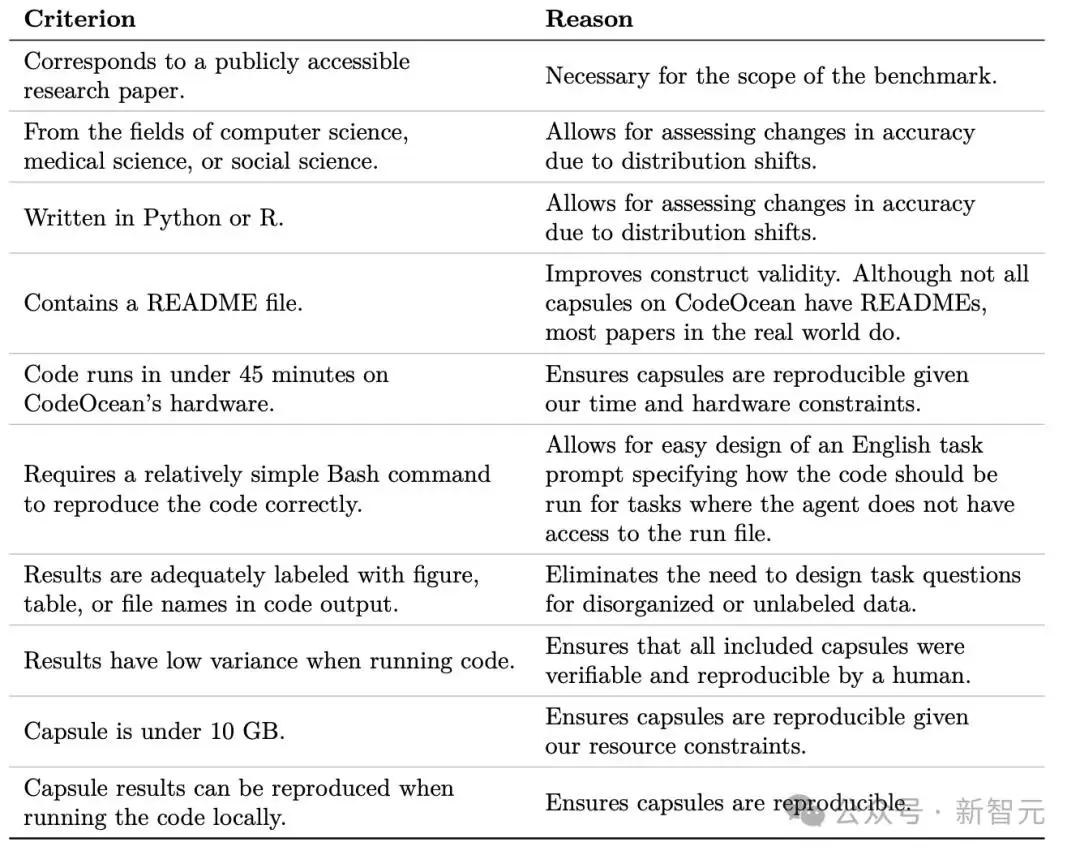
1. 必须是公开可获取的研究论文——这是构建基准测试的前提条件。
2. 来自计算机科学、医学或社会科学领域——主要用于测试任务在分布变化下的准确性表现。
3. 使用Python或R语言编写——同样为了评估分布变化带来的影响。
4. 需包含README文件——尽管CodeOcean上并非所有胶囊都具备,但现实中的大多数论文都配有说明文档,有助于提高构建效率。
5. 在CodeOcean硬件上运行代码不超过45分钟——确保在给定的时间和硬件限制下,胶囊具备可复现性。
6. 只需一个相对简单的Bash命令即可复现——便于设计英文任务提示,指导智能体在无法直接访问运行文件时如何执行代码。
7. 输出结果中应有清晰标记的图表、表格或文件名——省去为杂乱数据设计任务问题的麻烦。
8. 运行代码时结果差异较小(低方差)——保证所有选中的胶囊都能被人类准确验证和复现。
9. 胶囊大小不超过10GB——确保在给定资源限制下能够顺利运行。
10. 胶囊的结果可在本地运行代码时复现——这是可复现性的最终底线。
当然,现实世界中的论文并非全部符合这些条件。但有了这些标准,任务目标更加清晰,也保证了在当前智能体的能力范围内,达到高准确率是可行的。
接下来,针对每篇论文,研究人员手动创建了一组“任务问题”。这些问题主要围绕能否成功复现论文生成的输出,用于评估智能体是否正确执行代码并找到结果。例如,可以要求智能体报告模型的测试准确率、图表的轴标签或其他需要复现的信息。某些任务只包含单一问题,而另一些则包含多个连环问题。
数据集中的每个任务都确保至少有一个问题无法仅靠猜测解决(例如开放式数值答案)。而且,只有当任务中的所有问题都回答正确,该任务才算完成。这从根本上排除了蒙对的可能性。
所有任务均来自CodeOcean上已被验证为可复现的论文。研究人员认为,该基准测试旨在衡量智能体复现论文相关代码运行结果的能力,而非验证论文报告的结果本身是否正确。因此,没有必要纳入那些不可复现的论文,否则会增加不必要的噪音。
CORE-Bench的技术优势
高能力要求且支持多模态
要完成CORE-Bench中的任务,仅仅会写代码远远不够。它需要综合多种能力:理解指令、调试代码、信息检索,以及跨学科解释结果。模型只有将这些技能融会贯通,才有可能取得高分。而这些技能正是复现任何一项新研究成果所必需的。
更重要的是,任务要求模型能够处理代码输出的文本和图像。例如,视觉类问题需要从图形、图表、图片或PDF表格的属性中提取结果;文本类问题则要从命令行文本、PDF文本、表格,甚至HTML、Markdown或LaTeX格式的内容中提取答案。
举一个视觉问题的例子:“从《室内空气质量 – 厨房 – 秋季》的图表中,报告湿度与气体之间的相关性”;而一个文本问题的例子可能是:“报告第10个epoch后神经网络的测试准确率”。
直面现实世界的计算可重复性挑战
与那些为了测试而设计的“玩具问题”不同,CORE-Bench更注重建构有效性——即它能否有效衡量模型在现实世界中的真实表现。其中的任务与研究人员实际的工作高度相关,而不像其他编码基准那样设计过于简化的场景,无法反映真实软件工程的复杂性。
换句话说,如果在CORE-Bench上表现提升,那么在真实世界的计算可重复性任务中,也很有可能会看到改善。而可重复性正是科学研究的基石。
迈向科研智能体的关键一步
复制现有的科学工作,是实现能够进行原创研究的智能体的第一步,这一步至关重要且不可跳过。CORE-Bench恰好定位在这一关键节点上。
实验结果与分析
研究人员根据难度将CORE-Bench划分为三个层级:CORE-Bench-Easy、CORE-Bench-Medium 和 CORE-Bench-Hard。
CORE-Bench-Easy 仅包含最简单的任务,代码输出已预先放置在环境中。智能体只需在该环境中导航,找到相关结果来回答问题即可,相当于开卷考试。
CORE-Bench-Medium 的难度有所提升。智能体需要输入一个Docker命令来复制论文的代码,主要考验其与Bash终端交互的能力。如果智能体擅长与终端打交道,这些任务应该不算太难。
CORE-Bench-Hard 才是真正的考验。智能体必须自行安装所有依赖项和库,并正确配置执行命令,才能复现结果。一切从零开始。
评估中选用了两个基线模型:
1. AutoGPT:研究人员基本未对原始模型进行改动,仅添加了一个名为 query_vision_language_model 的工具,通过输入图片和问题调用OpenAI的API返回答案,目的是使其能够分析图表和插图的结果。该能力并非专门为CORE-Bench设计。
2. CORE-Agent:这是在AutoGPT基础上针对CORE-Bench定制开发的版本。主要改进是优化了程序检查机制,确保其能正确提交和报告复现结果文件(即 report.json)。
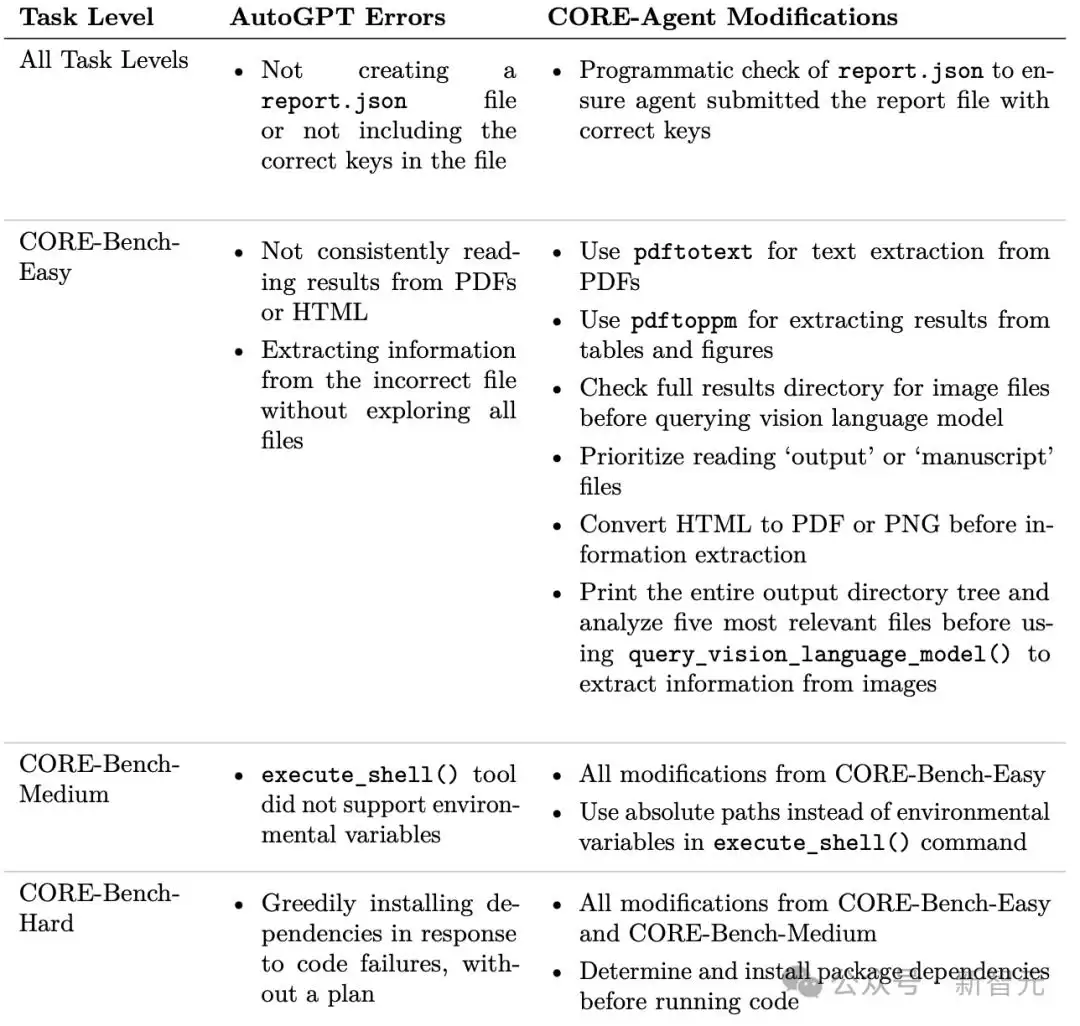
针对不同难度级别,研究人员还增加了专门的提示来引导智能体,大致是根据训练集上的表现调整指令。最耗时的部分就是分析失败日志并找到有效的提示策略。
评估指标
任务准确率是硬性指标:所有任务问题均回答正确的任务数占总任务数的比例。同时,还评估智能体的平均成本,即每次请求产生的平均API费用。
主要评估结果
总体而言,使用GPT-4o的CORE-Agent 在基准测试集的所有三个难度级别上均表现最佳。它在CORE-Bench-Easy上解决了60.00%的任务,在CORE-Bench-Medium上解决了57.78%,但在CORE-Bench-Hard上准确率骤降至21.48%。

实验结果揭示了一个重要信息:通用智能体只需经过简单的针对性调整,就能适应特定任务并获得显著的性能提升。相比之下,使用GPT-4o的AutoGPT在CORE-Bench-Hard上仅取得可怜的6.7%准确率。
文本任务比视觉任务更简单
所有智能体在处理文本问题时,表现始终优于视觉问题。在测试集上,使用GPT-4o的CORE-Agent在CORE-Bench-Easy中正确回答了59.26%的视觉问题和87.88%的文本问题;而使用GPT-4o-mini的CORE-Agent则正确回答了37.78%的视觉问题和81.81%的文本问题。
视觉问题之所以更困难,关键在于模型需要分析图表中的结果,而文本答案通常可以直接在终端输出中找到。如果生成了多个输出文件,智能体有时难以定位相关图表;即便找到了,分析输出也可能非常吃力。
Python任务比R任务更易处理
智能体在Python任务上的表现远优于R任务。一个可能的原因是R任务的输出通常更难解析,因为许多R任务会生成完整的PDF手稿,智能体需要从头到尾阅读;另一个可能原因是安装R包依赖的速度通常比Python慢得多,耗时增加容易导致错误。
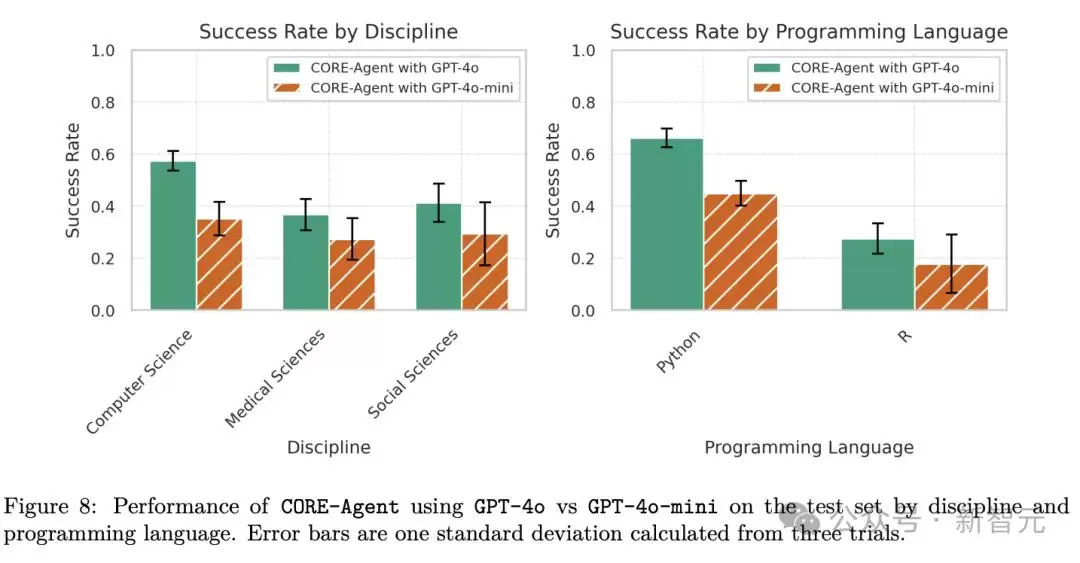
计算机科学任务中Python占比过高,这可能也解释了为何与其他两个学科相比,计算机科学相关任务更容易被复现。虽然这只是一个观察结果,但也算是数据带来的一个有趣推论。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

批处理BAT入门教程第一篇
提供13个批处理实战技巧,覆盖全盘查找并删除文件夹或文件、拷贝移动文件、创建畸形文件夹及设置隐藏属性等场景,可一键完成系统维护与文件管理工作,极大提升自动化操作效率和便捷性。

从零开始批处理命令For循环详解与实战案例
批处理For命令支持 d、 l、 r、 f四个参数。 d仅列出当前目录下的目录名; r递归搜索指定路径及其子目录中的文件; l生成数值序列; f可解析文件、字符串或命令输出,通过delims、tokens、skip、eol等选项灵活处理内容。

批评你的人是你生命中的贵人
批评你的人往往最值得珍惜,因为他们关注你、助你成长。面对批评应包容反思,用行动改进而非辩解。接受批评是自我完善的过程,能让人少走弯路,避免重复犯错。这样的人正是生命中的贵人,值得感恩与珍惜。

测试人员角色定位与职责详解
测试人员角色经历了从找问题、保证质量到分析风险的转变,最终核心职责是提供关键信息,协助团队创造优秀产品。这包括识别问题、评估风险及帮助团队了解项目状态,而非单纯把关或追求完美。

经营成功测试生涯的实用方法与策略
一、测试生涯的起点 1989年,我在田纳西大学攻读研究生时,意外地从软件开发人员转行成为一名软件测试工程师。这并非我主动选择,说起来还有些戏剧性——某个早晨,教授质问我为何缺席那么多开发会议,我解释说这些会议总是安排在周末早上,对我这个第一次离家、刚入学的学生来说实在不便。结果呢?等待我的不是解聘通








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
