




LTOFusion:多模态图像融合新视角(顶刊TIP 2026)

多模态图像融合长期占据计算机视觉领域的研究热点——如何将不同传感器捕获的图像信息有效整合,生成一张既保留结构层次、又富含纹理细节,同时突出显著目标的融合图像。看似简单,实际挑战重重。现有深度学习方法大多依赖神经网络直接学习从输入到输出的黑箱映射,这种直接映射虽然直观,但无监督优化空间过于复杂,且领域偏差容易压缩模型的有效解空间,导致局部细节与显著结构难以兼顾。
近期,来自重庆邮电大学、重庆师范大学和广安理工学院的研究团队在IEEE TIP上发表了创新成果:LTOFusion: A Learning-To-Optimize Framework with Flow Matching for Unsupervised Image Fusion。他们提出了一种全新思路——不再简单采用“直接映射”,而是将融合过程转化为多阶段的状态优化问题。简单来说,就是让网络学会如何逐步将初始融合结果“修正”为更优状态,而非一次性生成最终结果。这样一来,学习难度显著降低,融合质量自然更有保障。


论文标题:LTOFusion: A Learning-To-Optimize Framework with Flow Matching for Unsupervised Image Fusion
发表期刊:IEEE Transactions on Image Processing
研究机构:重庆邮电大学、重庆师范大学、广安理工学院
作者信息:贺丹,杨利建(共同一作),王国芬,黄渝萍,舒禹程*,李伟生*
一、论文概述:从“直接映射”迈向“逐步优化”
这项工作的核心贡献可从三个层面概括:
- 提出一种学习-优化融合范式。 不再追求一步到位,而是引导网络学习如何对三元组融合状态进行渐进式演化,形成可显式建模的融合轨迹。
- 设计像素变化流(Pixel Varying Flow, PVF) 作为潜在图像算子。通过限制决策空间并构建连续转换函数,实现平滑连贯的融合轨迹,避免跳跃式变化带来的伪影。
- 引入带回放记忆的训练策略。 缓存中间融合状态,将其作为额外训练样本复用,既增强模型鲁棒性,又避免递归网络中常见的梯度爆炸或消失问题。
实验结果表明,该方法在医学数据上训练后,无需微调即可直接泛化至其他任务,在边缘保真度和结构完整性等关键指标上提升明显,并能有效促进多模态语义分割下游任务。一句话总结:这项工作将图像融合从“直接映射生成”转向“可学习的逐步优化”,为无监督图像融合开辟了新视角。
二、关键理论
1. 可学习优化融合范式
从元学习角度出发,“学习如何学习”比“学习如何映射”更为高效,尤其针对像素级高维回归问题。因此,更理想的训练范式是:让模型学会如何从当前状态产生更优结果,这类似于传统优化问题思路。
基于三元组的LTO。 受此启发,作者将融合问题拆解为多个阶段,强制模型在每个阶段只做局部优化,逐步细化当前融合结果。为减少模型预测空间规模,他们引入潜在变量描述每一时刻对融合图像执行的操作,最终推导出可控链模型:源图像对与中间融合结果共同用于构建融合轨迹。
流匹配启发的受限状态转移。 为进一步降低学习难度,作者设计了受流匹配启发的受限状态转移函数——模型预测一个从当前融合状态指向目标更新方向的图像流场,即像素变化流(PVF)。整个融合轨迹通过状态转移逐步构建,神经网络通过可学习参数估计当前状态约束下的流场。
概念验证。 在二维图像域设计了两个合成实验。他们构造了已知的“目标融合流形”(由明确融合图像实例化),施加不同退化算子合成两个互补伪模态。所有方法仅在融合映射组织方式上有所区别:单步直接回归、扩散式迭代演化,或基于LTO的动态优化。这样能隔离融合范式本身的影响,直接比较其有效映射能力与轨迹行为。
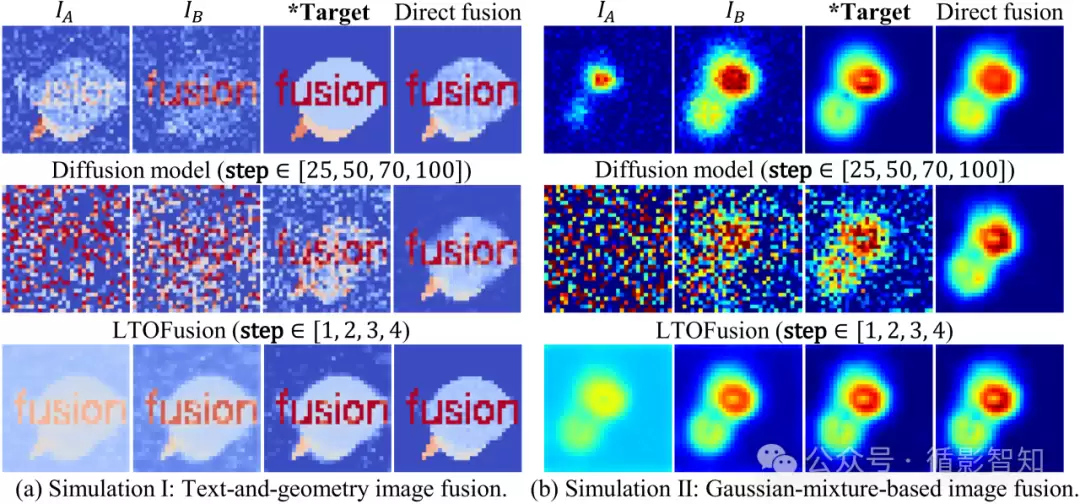
图1 基于已知目标流形的人工合成图像融合概念验证
结果非常直观(如图1所示):直接映射基线无法还原峰值的正确数量与形态;扩散式模型收敛缓慢且残留大量伪影;而LTOFusion沿迭代轴展现出清晰的由粗到细演化过程——早期状态先捕捉主要峰值的近似位置,后期逐步锐化局部模式,最终与目标图像紧密对齐。
2. 实施细节
基于上述状态转移,通过递归方式逐步优化融合结果,形成动态融合过程。整个融合轨迹长度为 T,数学表达简洁。工作流程见图2。为避免多层递归网络训练中的梯度不稳定,每次迭代的中间融合结果被缓存到内存池,随机采样形成新训练批次——该策略本质上是一种稳定长时域状态转换的记忆重放机制。网络架构采用类U-Net评估每步需要调整的像素流。
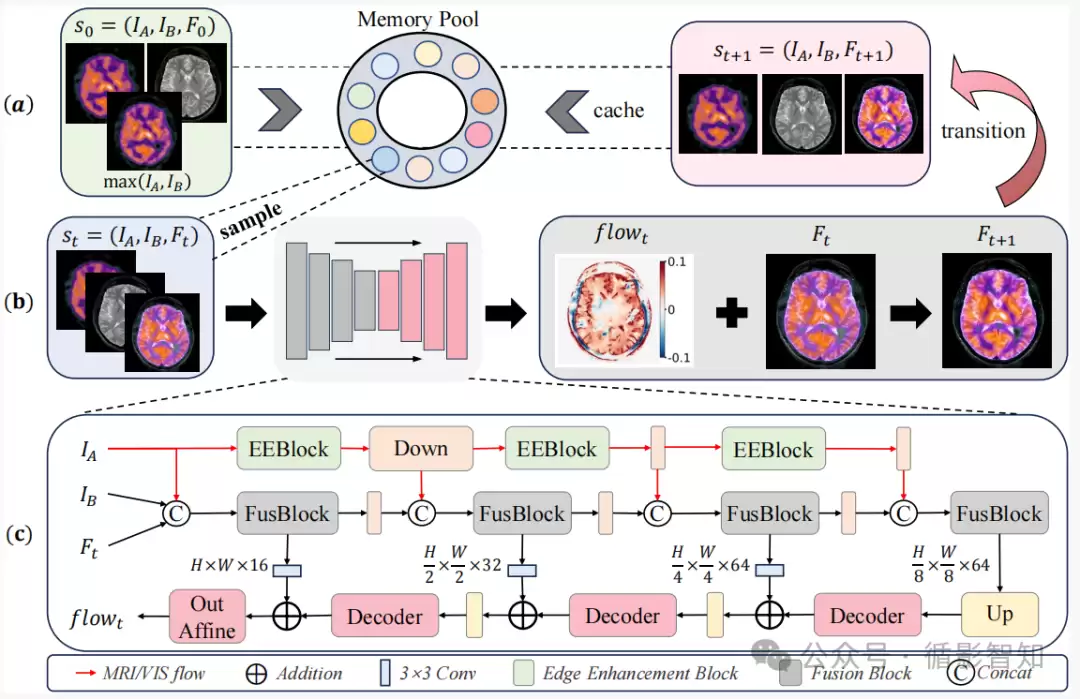
图2 LTOFusion的整体框架
三、局限性分析与未来展望
1. 局限性讨论
终止策略的初步探索。 文中简要讨论了一种基于阈值的自适应终止策略——自动判断图像对难度,动态选择迭代步数,避免固定步长对简单样本的冗余计算。但问题在于,无监督融合中单一指标难以全面刻画感知或任务层面的收敛性,且量化融合难度本身颇具挑战。未来可探索多指标联合与任务自适应的终止准则,构建更有理论依据的迭代停止机制。
训练策略的局限性。 该训练策略核心是构建“小步长、多迭代”的通用优化器。但其本质上是步数无关的——面对复杂图像对时,难以在初期实现较大增幅并快速达到性能增益收敛。如图3所示,在部分复杂图像对的前两步中,模型学到的PVF偏向“平均”,导致需要更多迭代后性能增益才接近收敛。这意味着在有限步长内,部分融合结果仍为次优。因此,未来可考虑将时间步显式嵌入网络,实现有限步数内的更快收敛。
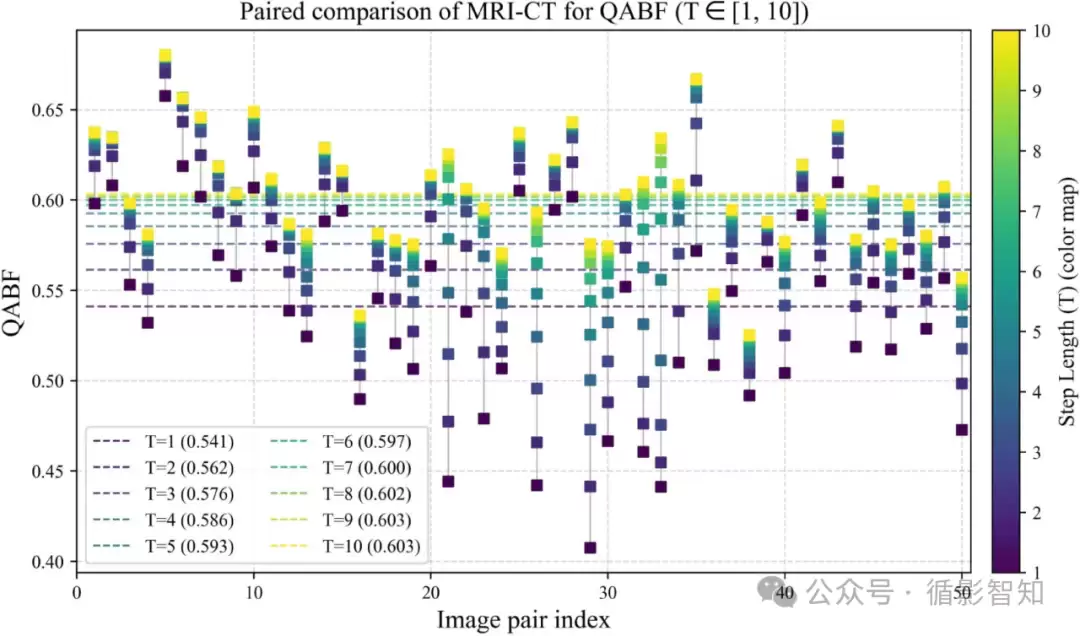
图3 不同图像对的每步增益
2. 未来展望
LTOFusion框架为图像融合提供了新视角,但仍有较大优化空间。未来工作可聚焦于三个方面:
- 设计步数相关的网络架构与训练策略,缓解当前“步数无关”带来的次优性问题,在有限步数内实现更快收敛。
- 进一步量化分布差异,探索“多指标联合”的自适应终止准则,克服定义复杂任务时的单一性。
- 将框架拓展至更具挑战性的场景,例如将迭代融合机制与几何形变建模相结合,解决模态间的空间错位问题。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

批处理BAT入门教程第一篇
提供13个批处理实战技巧,覆盖全盘查找并删除文件夹或文件、拷贝移动文件、创建畸形文件夹及设置隐藏属性等场景,可一键完成系统维护与文件管理工作,极大提升自动化操作效率和便捷性。

从零开始批处理命令For循环详解与实战案例
批处理For命令支持 d、 l、 r、 f四个参数。 d仅列出当前目录下的目录名; r递归搜索指定路径及其子目录中的文件; l生成数值序列; f可解析文件、字符串或命令输出,通过delims、tokens、skip、eol等选项灵活处理内容。

批评你的人是你生命中的贵人
批评你的人往往最值得珍惜,因为他们关注你、助你成长。面对批评应包容反思,用行动改进而非辩解。接受批评是自我完善的过程,能让人少走弯路,避免重复犯错。这样的人正是生命中的贵人,值得感恩与珍惜。

测试人员角色定位与职责详解
测试人员角色经历了从找问题、保证质量到分析风险的转变,最终核心职责是提供关键信息,协助团队创造优秀产品。这包括识别问题、评估风险及帮助团队了解项目状态,而非单纯把关或追求完美。

经营成功测试生涯的实用方法与策略
一、测试生涯的起点 1989年,我在田纳西大学攻读研究生时,意外地从软件开发人员转行成为一名软件测试工程师。这并非我主动选择,说起来还有些戏剧性——某个早晨,教授质问我为何缺席那么多开发会议,我解释说这些会议总是安排在周末早上,对我这个第一次离家、刚入学的学生来说实在不便。结果呢?等待我的不是解聘通








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
