




学习GLM-5.2:专注编程与长程任务

2026年6月,智谱AI正式推出GLM-5.2,这是一款专注于代码生成(Coding)与长程任务的大型语言模型,官方将其性能定位为“与Claude Opus 4.7-4.8处于可比区间”。更值得关注的是,它采用MIT开源协议,开发者可以自由下载、部署甚至用于商业用途。
本文并非仅做表面介绍。我们将深入剖析围绕GLM-5.2的三个关键开源项目,以及它们在智谱技术路线图中的真实位置。通过这些细节,可以清晰看到GLM-5.2的能力边界与工程哲学。
01 slime:支撑GLM全系列的RL训练基础设施
GitHub上的slime项目(github.com/THUDM/slime,目前已获6700星)在README中明确指出,它是GLM-5.2、GLM-5.1、GLM-5、GLM-4.7、GLM-4.6、GLM-4.5这六代模型背后的训练框架。
核心设计目标十分明确:解决强化学习(RL)训练在大规模部署中面临的工程效率难题。其创新点在于一套“异步生成-训练流水线”,能显著提升训练吞吐量与效率,使模型可以经历多次精细化的后训练迭代。GitHub原文描述为:“a novel asynchronous RL infrastructure that substantially improves training throughput and efficiency”。
从技术视角看,slime的存在揭示了一个重要事实:GLM从4.5到5.2的迭代,并非每次都从零开始重新训练,而是在同一套RL基础设施上持续优化。这正是智谱能够快速迭代的核心工程资产。
02 AgentRL:多轮Agent RL的完整框架
相关论文发表于arXiv(编号2510.04206,2025年10月),标题为《Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework》。配套的GitHub仓库为github.com/THUDM/AgentRL。
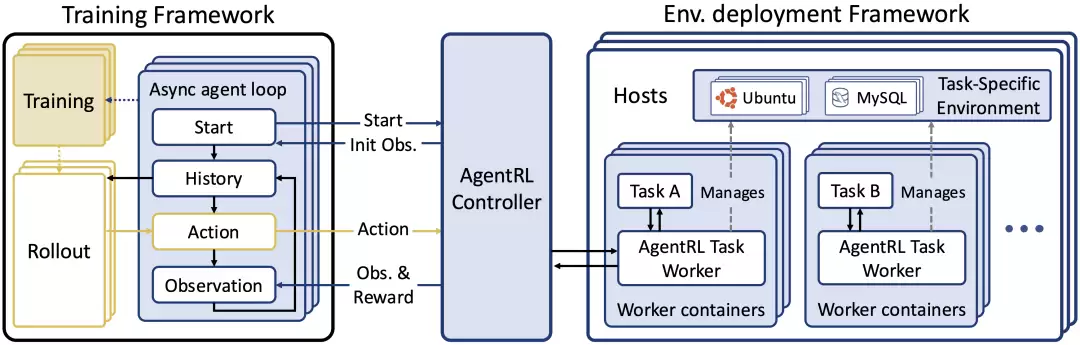
多轮Agent训练,核心难点在哪儿?论文指出两大痛点:一是可扩展基础设施的缺失。多轮RL需要异步生成-训练流水线,但现有框架缺乏稳定的多任务支持。二是训练稳定性问题。多任务场景下,不同任务的reward(奖励)方差巨大,若缺少跨任务的优势函数归一化,极易导致策略崩溃。
针对这些问题,论文提出一套组合方案:
- 三池架构:包括Rollout Worker Pool、Actor Worker Pool和Reference Worker Pool,通过Ray Cluster统一调度。
- Cross-Policy Sampling:在多轮设置中,考虑多个策略分布,对被忽略的行动路径给予额外探索权重。
- Task Advantage Normalization:对不同任务的优势函数进行归一化,从根本上解决reward scale差异导致的训练不稳定问题。
实验结果颇具说服力。论文原文指出:“AgentRL, trained on open LLMs across five agentic tasks, significantly outperforms GPT-5, Clause-Sonnet-4, DeepSeek-R1, and other open-source LLM agents. Multi-task training with AgentRL matches the best results among all task-specific models.”(注:arXiv原文中的"Clause-Sonnet-4',应为'Claude-Sonnet-4')。更重要的是,AgentRL的算法与框架已被直接用于构建智谱的自主Agent产品——AutoGLM。
03 DeepDive:知识图谱驱动的深度搜索Agent
另一篇值得关注的论文是《Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL》(arXiv编号2509.10446,2025年9月),GitHub仓库为github.com/THUDM/DeepDive。其目标非常清晰:解决开源LLM在深度搜索任务上落后于闭源模型的问题。
数据合成管线的设计颇具巧思:
- 第一步,知识图谱随机游走。从KILT和AMiner知识图谱出发,生成多跳路径(跳数k=5-9),k值越大,推理复杂度越高。
- 第二步,实体模糊化。由LLM自动生成需要深度搜索才能还原的“模糊实体”,全程无需人工标注。
- 第三步,难度筛选。只保留连前沿模型都全部失败的题目,确保训练数据难度足够“硬核”。
核心算法方面,采用GRPO with Normalized Advantages(带归一化优势的GRPO),旨在解决稀疏reward场景下的梯度问题。同时加入Redundancy Penalty(冗余惩罚),对相似的重复查询施加惩罚,鼓励模型探索更多样化的路径。
实验结果同样亮眼。论文原文提到:“DeepDive-32B achieves a new open-source competitive result on BrowseComp, outperforming WebSailor, DeepSeek-R1-Browse, and Search-o1.” 这验证了一条关键路径:知识图谱随机游走 + 多轮RL,完全可以在特定场景(如深度搜索)上系统性地超越闭源模型。这对构建垂直领域的Agent具有直接参考价值。
04 GLM-5.2核心能力:来自GitHub README的核实数据
模型规格方面:总参数量为744B,激活参数为40B(与GLM-5规格相同,GLM-5.2是其升级版)。预训练数据量达28.5T tokens,高于GLM-5的23T。上下文窗口为1M Token无损上下文,最大输出可达128K tokens。开源协议采用MIT,商用友好。
Coding能力的提升尤其值得关注。根据GitHub README数据:
- 在Terminal-Bench 2.1上,GLM-5.2得分81.0,而GLM-5.1为62.0,提升17.5%。作为对照,Claude Opus 4.8得分为85.0,两者差距已缩小至约4%,且GLM-5.2超越了Gemini 3.1 Pro。
- 在SWE-bench Pro上,GLM-5.2得分62.1,GLM-5.1为58.4。
官方给出的结论是:“On standard coding benchmarks, GLM-5.2 is the strongest open-source model, improving on GLM-5.1 by a wide margin.”
架构创新IndexShare(arXiv:2603.12201)是另一关键工程亮点。其底层原理是,稀疏注意力中每一层的indexer计算高度相似,通过跨层复用可大幅降低FLOPs。具体方案是将Layer分组为Full layers(有独立indexer)和Shared layers(复用上一Full layer的top-k indices)。效果显著:在1M上下文下,单token FLOPs降至2.9倍;对一个30B的DSA模型,可移除75%的indexer计算,Prefill加速1.82倍,Decode加速1.48倍。此外,MTP(Multi-Token Prediction)改进让投机解码的接受长度最多提升20%。
核心洞察在于:GLM-5.2的核心差异化体现在两个维度。第一,Coding能力通过Terminal-Bench 2.1验证为开源最强,已进入与Claude Opus 4.8的可比区间。第二,IndexShare让“1M无损上下文”从理论可能性变成工程上可高效部署的现实。
05 对研究者和开发者的实际价值
如果你是AI研究员,可按以下优先级关注这些工作:
- 第一优先级:AgentRL(arXiv:2510.04206)。作为多轮RL的基础设施论文,其“多任务联合训练达到各任务最优”的成果对未来Agent多任务学习路径有直接参考价值。
- 第二优先级:DeepDive(arXiv:2509.10446)。“知识图谱随机游走 + 多轮RL”的组合,是构建垂直领域Agent的有效路径。
- 第三优先级:IndexCache(arXiv:2603.12201)。稀疏注意力跨层索引复用技术,对超长上下文推理优化有重要参考价值。
- 第四优先级:slime(GitHub)。作为Megatron + SGLang方案的RL后训练框架,它是在多模型上验证过的生产级基础设施。
如果你是一名应用开发者,这些信息可能更实用:
- Coding场景:Terminal-Bench 2.1实测81.0分,开源最强,适合项目级代码生成和复杂代码任务。
- 长程Agent场景:1M无损上下文 + slime RL基础设施,非常适合需要持续执行数百轮工具调用的场景。
- 本地部署:已支持vLLM、SGLang、Transformers、KTransformers、Unsloth等主流推理框架,上手门槛较低。
三个核心判断送给大家:
- RL Scaling是智谱这代模型的核心主线。slime、AgentRL、DeepDive三篇开源工作,构成了一条完整的技术链路。
- Coding + 长程任务是GLM-5.2的核心差异化定位。Terminal-Bench 2.1上4%的差距,是GitHub README原文明确给出的数据。
- IndexShare/IndexCache是GLM-5.2最值得关注的工程创新,它让1M上下文从理论蓝图变成了可高效部署的产品。
行动建议:如果你在评估技术选型,本周可以实测GLM-5.2在Coding任务上的实际表现,对照Terminal-Bench 2.1的数据做针对性验证。本月可以跟团队一起评估1M无损上下文在项目级开发场景中的实用性。最后,永远要区分“预训练Scaling”和“RL Scaling”这两条不同的技术路线,在工程资源上,RL Scaling或许是当下更聚焦的发力点。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Stable Diffusion WebUI本地模型下载配置与性能优化指南
StableDiffusionWebUI适合在个人电脑上运行本地绘图模型,关键在于准备显卡环境、正确下载模型、放入对应目录,并通过分辨率、采样器、显存参数等设置提升生成效率与稳定性。

Stable Diffusion WebUI插件安装配置教程:浏览器、编辑器或扩展市场
StableDiffusionWebUI插件可增强模型管理、提示词、图像处理与工作流效率。安装前需确认版本、环境和来源,按内置扩展页、网址安装或本地导入完成配置,并做好备份与兼容性检查。

Stable Diffusion WebUI Docker一键部署:镜像拉取端口映射数据目录配置
使用Docker部署StableDiffusionWebUI可降低环境配置难度,重点在于选择镜像、映射7860端口、挂载模型与输出目录,并提前确认显卡驱动、存储空间和访问权限。

Stable Diffusion WebUI API Key 获取与配置教程:账号注册与国内网络设置
围绕StableDiffusionWebUI的APIKey配置,说明账号注册、密钥获取、本地接口认证、国内网络访问设置、验证方法与安全注意事项,适合AI绘画工具初次部署和团队接入使用。

Stable Diffusion WebUI Linux服务器部署完整教程:从环境准备到后台运行
StableDiffusionWebUI在Linux服务器部署需先确认GPU、驱动、Python与依赖环境,再拉取项目、配置模型和启动参数。后台运行建议使用tmux、nohup或systemd,并做好访问鉴权、端口限制、资源监控与模型来源校验。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
2026-07-03 16:15
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:14
2026-07-03 16:13
2026-07-03 16:13
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
