




深度学习为何至今未取代传统计算机视觉技术

深度学习无法完全取代传统计算机视觉,因为前者需海量标注数据和长时间训练,而后者在数据稀缺时可控性强、可解释性高,处理简单任务更高效且资源需求低,同时理解传统技术有助于优化深度学习模型的设计与应用。
深度学习确实为计算机视觉领域带来了革命性突破,让机器在某些任务中甚至超越了人类——图像分类就是最典型的例证。但问题是,深度学习真的彻底取代了传统计算机视觉技术吗?一个在开发者社区中反复被提及的疑问是:“既然深度学习如此强大,还有必要学习那些旧方法吗?”答案是:深度学习只是工具箱里的一把锤子,而非万能螺丝刀。本文将从多个角度阐释,为什么传统计算机视觉技术仍然不可或缺,并且掌握它甚至能让你更高效地运用深度学习。
背景知识
在深度学习成为主流之前,进行图像分类通常要经历一个名为“特征提取”的步骤。所谓特征,就是图像中那些“有趣的”、具有描述性或信息量的局部区域。你需要借助各种传统计算机视觉手段——比如边缘检测、角点检测、对象检测等——来定位这些特征。接着,从属于同一类别(例如椅子、马匹)的图像中提取尽可能多的特征,并将这些特征集合视为该类别的“定义”(也就是“词袋”)。随后,在其他图像中搜索这些定义——如果某张图像包含了足够多的相关特征,就将其归入该类别。
这一方法的难点在于:每张图像中需要寻找哪些特征,完全依赖你手动判断。当分类类别增多(比如超过10或20个),工作会变得极其繁琐甚至不可行。你是寻找角点?边缘?还是纹理?不同对象往往需要不同类型的特征描述符。如果选取的特征过多,参数空间会急剧膨胀,而且你必须亲自反复调参。
深度学习引入了“端到端学习”的概念。简单来说,就是让机器自动学会在每个类别中寻找最具描述性和区分性的特征。神经网络能够自主发现图像中的隐含模式,你不再需要手动选择传统视觉技术来提取特征。正如《连线》杂志所描述的那样:
举例来说,如果你想教会一个[深度]神经网络识别猫咪,你无需告诉它要寻找胡须、耳朵、毛发或眼睛。你只需要给它展示成千上万张猫咪的图像,它自然会解决这个问题。如果它总是把狐狸误认成猫,你也不必重写代码,只需继续对它进行训练即可。
下图直观地展示了传统特征提取与端到端学习之间的对比:
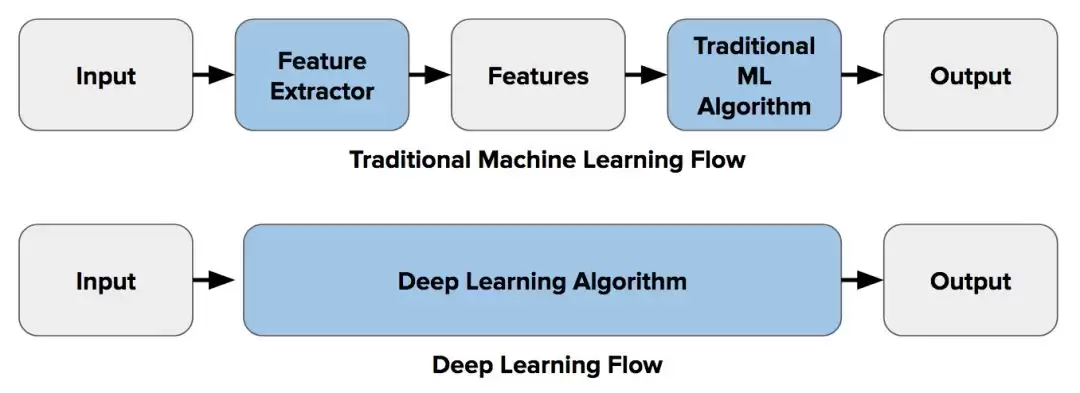
背景梳理清楚后,我们现在进入正题——为什么传统计算机视觉仍然至关重要。
深度学习需要大量数据
首先,深度学习是个“数据饕餮”。那些知名的图像分类模型都是在庞大数据集上训练而成的。排名前三的训练集规模如下:
- ImageNet:150万张图像,1000个对象类别
- COCO:250万张图像,91个对象类别
- PASCAL VOC:50万张图像,20个对象类别
训练不良的模型一旦脱离训练环境,表现很可能一塌糊涂。因为机器并未真正理解问题本质,它只是记住了所见的模式。深度学习模型内部包含数百万个参数,调整起来如同黑箱——你很难深入其中手动纠错。
传统计算机视觉则完全透明。你可以直接评估解决方案在训练环境之外的适用性,并将自己的领域知识融入算法。哪个环节出了问题,你能够清晰地知道需要调整什么以及如何调整。这种可控性在数据不足或场景多变时显得尤为珍贵。
深度学习有时会过度复杂化
这一点我最想强调。训练一个深度神经网络需要大量的时间和专用硬件(例如高性能GPU)。如果你想用自己还算不错的笔记本电脑来训练最新的图像分类模型?恐怕你得请一周假,回来后可能还没跑完。如果模型表现不佳,你还要回到原点更换一组训练参数重新开始——这个过程可能重复上百次。
然而,在很多情况下这些折腾完全是多余的。传统计算机视觉技术能用更少的代码、更短的时间解决问题。举个例子:我曾参与一个项目,需要检查传送带上每个罐子里是否有一个红勺子。你可以选择深度学习的路线,花几天甚至几周训练一个勺子检测模型;也可以写一个简单的基于红色阈值的算法——将像素中红色范围内的标记为白色,其余标记为黑色,然后统计白色像素的数量。一个小时就搞定了。
因此,掌握传统计算机视觉技术能帮你节省大量时间和不必要的麻烦。在合适的地方使用合适的工具,才是明智之举。
传统计算机视觉能提升你的深度学习水平
理解传统技术实际上能让你把深度学习运用得更加得心应手。计算机视觉领域最常用的神经网络是卷积神经网络。但卷积究竟是什么?它本质上是一种图像处理技术,索贝尔边缘检测使用的正是卷积。搞懂这一点,你就能更好地理解神经网络内部的工作机制,从而更有针对性地设计和微调模型。
再比如预处理。你喂给模型的数据通常需要先进行准备,而这些预处理步骤大多依赖传统计算机视觉技术。例如,当训练数据不足时,可以做“数据增强”:对训练集中的图像随机旋转、平移、裁剪等,生成“新”图像。这些操作本身都是标准的计算机视觉处理,却能显著增加训练数据量,提升模型的泛化能力。
结论
回到开头的问题:深度学习无法也不可能取代传统计算机视觉。第一,深度学习需要海量数据才能表现良好,而现实场景中数据往往不够——传统方法恰好能填补这个缺口。第二,针对特定简单任务,深度学习会“杀鸡用牛刀”,传统视觉技术更高效、更简洁。第三,掌握传统技术反而能让你在深度学习上做得更好——你既能理解模型内部机制,也能利用预处理手段优化结果。
深度学习是一种强大的计算机视觉工具,但绝不是包治百病的灵丹妙药。不要因为流行就一股脑地往上堆,选对工具才是关键。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:深度学习为何至今未取代传统计算机视觉技术要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看