




MCP Model Context Protocol 一篇文章全面掌握

MCP(模型上下文协议)是一套统一标准,使AI模型能以一致方式连接数据源和工具,解决传统函数调用对平台依赖性强的问题。它提供丰富现成工具和清晰架构,由主机、客户端和服务端组成,支持灵活切换模型并保障数据安全。
最近,MCP这个关键词频繁出现在我浏览的技术文章和评论区里。起初我也只是有个模糊的概念,但既然大家都在讨论,索性就深入把这个概念搞搞清楚,顺便记录一下学习心得。
在动笔之前,我大致扫了一眼市面上现有的介绍文章。坦白说,大部分要么是在直接翻译MCP的官方文档,要么就是在一些普通用户压根不关心的技术细节上大做文章(当然,还有一些纯AI生成的水文)。
所以,这篇文章决定换个角度。从一名实际使用者的视角出发,分享点真正能落地的干货。最后还会用一个具体的实例,带大家走一遍MCP的开发和应用流程。整篇文章的目标,就是回答清楚下面三个问题:
- MCP到底是什么?
- 为什么我们需要MCP?
- 作为一个普通用户或开发者,我们该怎么用它、甚至开发它?
当然,一篇文章的篇幅有限,不可能把MCP的所有细节都讲透。这里只萃取最核心、最精华的部分,跟大家好好聊聊。
1. 什么是MCP?
时间拨回到2024年11月25日,Anthropic发布了一篇名为《Introducing the Model Context Protocol》的文章,MCP就此诞生。
全称是Model Context Protocol,即模型上下文协议。它定义了一套标准,让应用程序和AI模型之间能够顺畅地交换上下文信息。更直白地说,它让开发者能够用一种统一的方式,把各种数据源、工具和功能连接到AI模型上。这就像给AI世界装了一个“USB-C”接口——不同设备通过同一个标准接口就能无缝连接。MCP的目标,就是建立这样一个通用标准,让AI应用的开发和集成变得前所未有的简单和统一。
一张图胜过千言万语,这里引用几张制作精良的示意图,帮助理解:
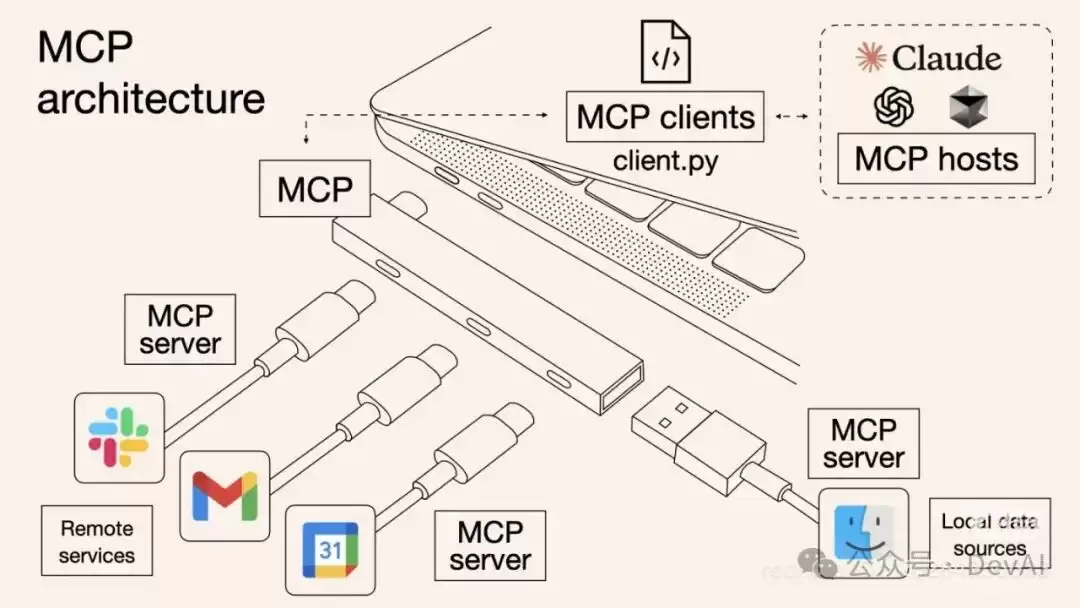
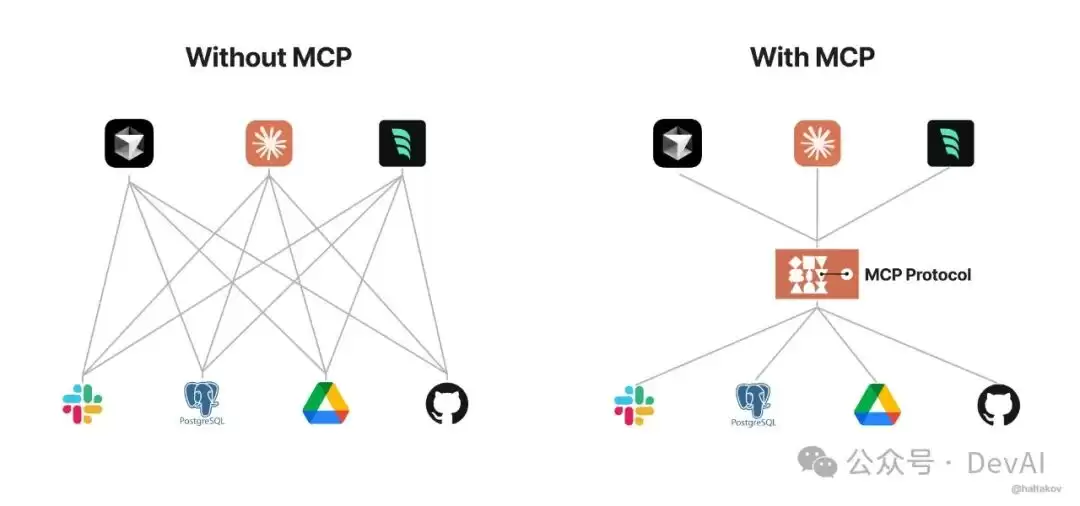
看明白了吗?MCP的本质,就是用更标准化的方式让大语言模型(LLM)调用不同的工具。下面这张图更直观,能帮你理解“中间协议层”这个概念。说白了,Anthropic就是想统一LLM调用工具的“语言”。
为了保证阅读的流畅性,我们把MCP Host / Client / Server这些专业技术术语的定义往后放放。初学者和普通用户可以暂时忽略这些概念,完全不耽误你对MCP的理解和使用。
2. 为什么需要MCP?
MCP的出现,可以说是Prompt Engineering发展的必然产物。给模型提供更结构化的上下文信息,对于提升其表现能力是立竿见影的。我们在编写提示词时,总是希望能给模型提供一些更具体、更个性化的信息(比如本地文件、数据库内容、网络实时数据等),这样模型才能真正理解现实世界中的复杂问题。
不妨回想一下,在没有MCP的时候,我们是怎么做的?大概率是手动从数据库里筛选,或者用其他工具检索出需要的信息,然后一条条复制粘贴到提示词里。随着要解决的问题越来越复杂,这种“手动搬砖”的模式很快就行不通了。
为了摆脱手工操作的局限,许多大模型平台(比如OpenAI、Google)引入了一个叫“函数调用”的功能。这个机制允许模型在需要的时候,主动去调用预先定义好的函数来获取数据或执行操作,大大提升了自动化水平。
但是,函数调用也有它的短板。关键在于函数调用对平台的依赖性太强。不同平台的函数调用API实现差异巨大,OpenAI的调用方式和Google的完全不兼容。开发者一旦想切换模型,就不得不重写一大堆代码,适配成本非常高。除此之外,安全性和交互性等问题也同样存在。
数据和工具本身就在那里,客观存在。问题在于,我们希望“将数据连接到模型”的这个环节,能够更智能、更统一。Anthropic正是洞察到了这个痛点,才设计了MCP。它就像是AI模型的一个“万能转接头”,让大语言模型能够轻松地获取数据或者调用工具。具体来说,MCP的优势体现在这几个方面:
- 生态丰富:MCP提供了大量现成的插件,拿过来就能用。
- 统一标准:它不依赖任何特定的AI模型,只要支持MCP,模型之间可以灵活切换。
- 数据安全:你的敏感数据可以存放在本地,没必要全部上传。我们可以自行设计接口,决定哪些数据传输给模型。
3. 用户如何使用MCP?
对于绝大多数用户来说,我们并不需要关心MCP是怎么实现的。我们只想知道,怎么才能最简单、最轻松地用上这个新特性。具体怎么配置,可以参考官方文档中针对Claude桌面用户的指南,这里就不赘述了。配置成功后,可以在Claude里测试一下:让它“写一首诗,并保存到桌面”。Claude会请求你的权限,然后直接在本地新建一个文件。
不仅如此,官方还提供了大量现成的MCP服务端(MCP Servers)。你只需要选择希望接入的工具,然后直接“接入”就好。相关的资源链接在这里:Awesome MCP Servers、MCP Servers Website、Official MCP Servers。比如官方介绍的文件系统工具,它可以让Claude像操作本地文件系统一样,读取和写入文件。
4. MCP架构解构
这里先放一张官方的架构图。
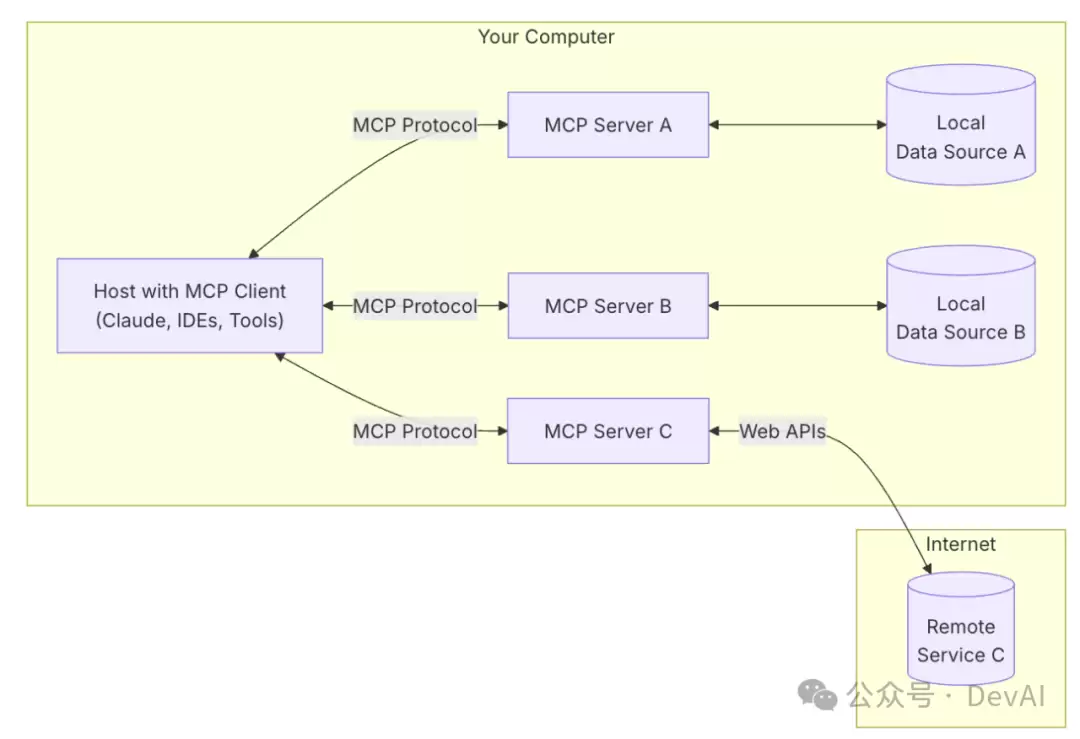
MCP由三个核心组件构成:主机、客户端和服务端。光说概念有点抽象,咱们通过一个实际场景来理解它们是怎么协同工作的。
假设你正在用Claude桌面版(也就是主机)问:“我桌面上有哪些文档?”
整个流程是这样的:你的问题先发给Claude桌面版(主机)。Claude模型分析后觉得,要回答这个问题,需要访问你的文件系统。这时,主机中内置的MCP客户端立刻被激活。这个客户端负责找到并连接一个合适的MCP服务端。在这个例子里,就是文件系统MCP服务端。它收到指令后,会执行实际的文件扫描操作,访问你的桌面目录,然后返回找到的文档列表。最后,Claude模型拿到这个结果,生成自然语言的回答,展示在Claude桌面版上。
这种架构设计的妙处在于,Claude可以在不同场景下灵活调用各种工具和数据源。而作为开发者,你只需要专注于开发对应的MCP服务端(Server),至于主机和客户端怎么实现的,完全不用操心。
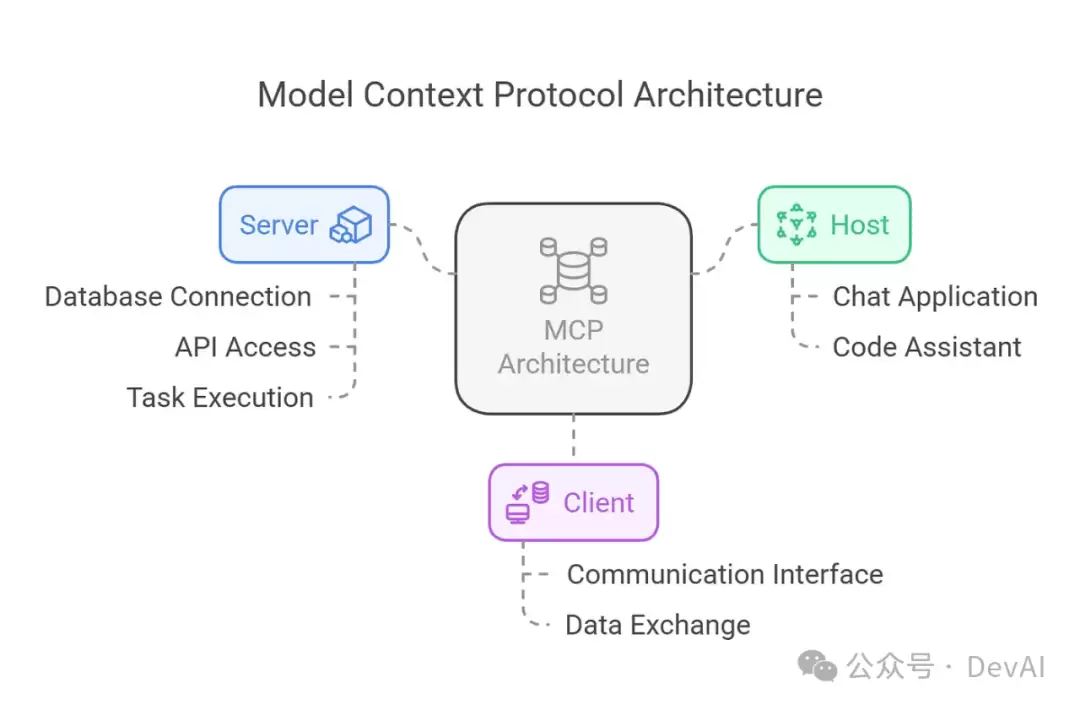
5. 原理:模型是如何确定工具的选用的?
在学习过程中,我一直有个疑问:Claude(模型)是怎么知道该用哪些工具的?好在Anthropic给出了详细的解释。
当用户提出一个问题时,流程是这样的:
- 客户端(比如Claude桌面版或Cursor)把你的问题发送给Claude。
- Claude分析当前可用的工具,然后决定用哪个(或者哪几个)。
- 客户端通过MCP服务端去执行选定的工具。
- 工具执行的结果被送回给Claude。
- Claude结合执行结果,构造最终的提示词,生成自然语言的回应。
- 最终,回应展示给用户!
有意思的是,MCP服务端是由Claude主动选择并调用的。它具体是怎么确定该用哪些工具的?会不会出现幻觉,调用一些根本就不存在的工具?这是个值得深思的问题。
6. 总结
MCP的出现,标志着AI与外部工具和数据交互开始走向标准化。通过这篇文章,我们主要了解了以下几点:
- MCP的本质:它是一套统一的协议标准,让AI模型能够以一致的方式连接各种数据源和工具,就像是AI世界的“USB-C”接口。
- MCP的价值:它解决了传统函数调用对平台依赖性强的问题,提供了更统一、开放、安全、灵活的工具调用机制。无论是用户还是开发者,都能从中受益。
- 使用与开发:对普通用户来说,MCP提供了丰富的现成工具,即使不了解任何技术细节也能直接上手。对开发者而言,MCP提供了清晰的架构和SDK,让开发工具变得相对简单。
MCP目前还处于发展初期,但潜力巨大。关键还是在于生态。基于统一标准构建起来的生态,会反过来正向促进整个领域的发展。
以上内容已经覆盖了MCP的基本概念、价值和使用方法。对于那些对技术实现感兴趣的读者,下面的附录提供了一个简单的MCP服务端开发实践,能帮助你更深入地理解MCP的工作原理。
附录A:MCP服务端开发实践
了解了MCP的各个组件之后,我们会发现,对绝大多数AI开发者来说,我们其实只需要关心服务端(Server)的实现。所以,我准备了一个最简单的例子,来演示如何实现一个MCP服务端。
MCP服务端可以提供三种主要类型的功能:
- 资源(Resources):类似文件的数据,可以被客户端读取(如API响应或文件内容)。
- 工具(Tools):可以被大语言模型调用的函数(需要用户批准)。
- 提示(Prompts):预先编写的模板,帮助用户完成特定任务。
本教程主要关注工具(Tools)。
A.I 使用LLM构建MCP的最佳实践
在正式动手之前,Anthropic提供了一个基于大语言模型开发MCP服务端的最佳实践。总结起来就两步:
1. 引入领域知识(说白了,就是给对话里塞一些MCP服务端开发的范例和资料)。比如,可以访问MCP官方文档的完整文本,或者导航到MCP的TypeScript SDK或Python SDK的Github项目中,复制相关内容,把这些作为提示词的上下文。
2. 描述你的需求。告诉它:你的服务端会开放哪些资源,它会提供哪些工具,它应该给出哪些引导或建议,它需要跟哪些外部系统互动。这里给出一个示例提示:
... (这里是已经引入的领域知识)
打造一个MCP服务端,它能够:
- 连接到我公司的PostgreSQL数据库
- 将表格结构作为资源开放出来
- 提供运行只读SQL查询的工具
- 包含常见数据分析任务的引导剩下的部分虽然也很重要,但更偏重方法论,实践性较弱,这里就不展开了,推荐直接看官方文档。
A.II 手动实践
这部分内容主要参考了官方的开发者快速入门指南。你可以选择直接跳过,或者快速浏览一遍。
我们准备一个简单的示例,用Python实现一个MCP服务端,功能是统计当前桌面上的txt文件数量,并获取对应文件的名字。你可以说它毫无用处,但它足够简单,能让大家在最短的实践里看到效果。以下实践均运行在MacOS系统上。
Step1. 前置工作
- 安装Claude桌面版。
- Python 3.10+ 环境。
- Python MCP SDK 1.2.0+。
Step2. 环境配置
这里使用的是官方推荐的配置方式:
# 安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建项目目录
uv init txt_counter
cd txt_counter
# 设置Python 3.10+ 环境
echo "3.11" > .python-version
# 创建虚拟环境并激活
uv venv
source .venv/bin/activate
# 安装依赖
uv add "mcp[cli]" httpx
# 创建服务端文件
touch txt_counter.py什么是uv?跟conda比有什么区别? 简单说,uv是一个用Rust编写的超快速(100x)Python包管理器和环境管理工具,由Astral开发。它的定位是替代pip和venv,专注于速度、简单性和现代Python工作流。
Step3. 构造一个提示词
"""
... (这里是已经引入的领域知识)
"""
打造一个MCP服务端,它能够:
- 功能:
- 统计当前桌面上的txt文件数量
- 获取对应文件的名字
要求:
- 不需要给出提示词和资源相关代码。
- 你可以假设我的桌面路径为 /Users/{username}/Desktop- 这里的领域知识可以复制MCP Python SDK的README文件。
Step4. 实现MCP服务端
以下代码由Claude 3.7直接生成。当然,这主要是因为我们的需求足够简单。当你需要实现更复杂的MCP服务端时,可能需要多步引导和调试才能得到最终代码。
import os
from pathlib import Path
from mcp.server.fastmcp import FastMCP
# 创建MCP服务端
mcp = FastMCP("桌面TXT文件统计器")
@mcp.tool()
def count_desktop_txt_files() -> int:
"""统计桌面上的.txt文件数量。"""
# 获取桌面路径
username = os.getenv("USER") or os.getenv("USERNAME")
desktop_path = Path(f"/Users/{username}/Desktop")
# 统计.txt文件
txt_files = list(desktop_path.glob("*.txt"))
return len(txt_files)
@mcp.tool()
def list_desktop_txt_files() -> str:
"""获取桌面上所有.txt文件的文件名列表。"""
# 获取桌面路径
username = os.getenv("USER") or os.getenv("USERNAME")
desktop_path = Path(f"/Users/{username}/Desktop")
# 获取所有.txt文件
txt_files = list(desktop_path.glob("*.txt"))
# 返回文件名
if not txt_files:
return "桌面上没有找到.txt文件。"
# 格式化文件名列表
file_list = "\n".join([f"- {file.name}" for file in txt_files])
return f"在桌面上找到 {len(txt_files)} 个.txt文件:\n{file_list}"
if __name__ == "__main__":
# 初始化并运行服务端
mcp.run()这个任务非常简单,只需要调用基本的os库就能完成。
Step5. 测试MCP服务端
官方文档里没有这一步,但我非常推荐大家都做一下。在终端运行:
$ mcp dev txt_counter.py
Starting MCP inspector...
Proxy server listening on port 3000
? MCP Inspector is up and running at http://localhost:5173 ?之后进入给出的链接,按照下图进行操作。
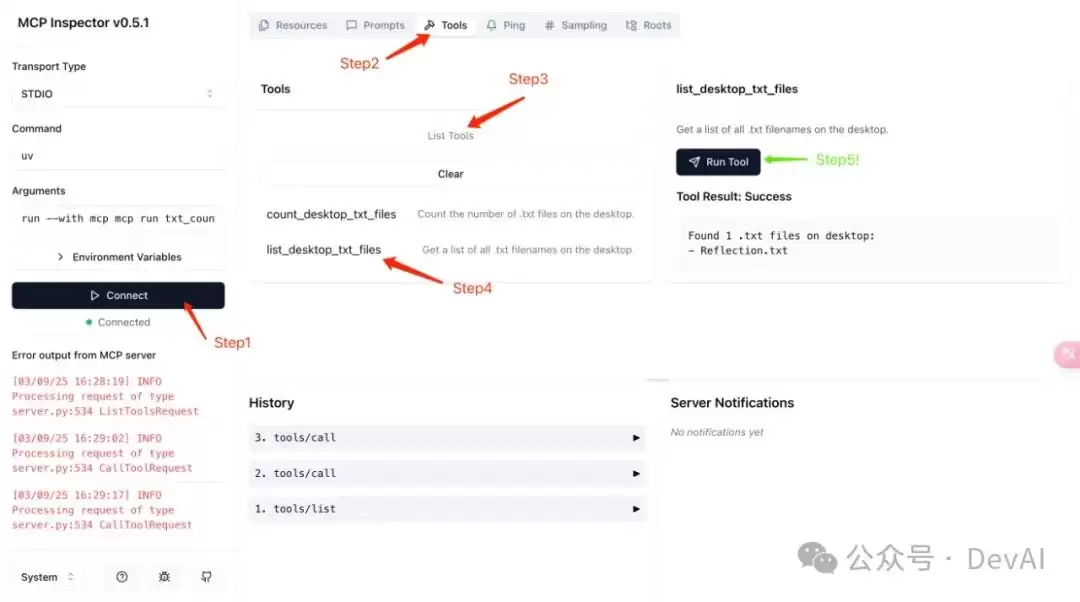
如果一切顺利,你应该能看到对应的输出(Tool Result)。
Step6. 接入Claude
最后一步,就是把我们写好的MCP服务端接入到Claude桌面版中。流程如下:
# 打开 claude_desktop_config.json (MacOS / Linux)
# 如果你用的是Cursor或者Vim,请更换对应的命令
code ~/Library/Application Support/Claude/claude_desktop_config.json在配置文件中添加以下内容,记得替换/Users/{username}为你的实际用户名:
{
"mcpServers":{
"txt_counter":{
"command":"/Users/{username}/.local/bin/uv",
"args":[
"--directory",
"/Users/{username}/work/mcp-learn/code-example-txt", // 你的项目路径
"run",
"txt_counter.py" // 你的MCP服务端文件名
]
}
}
}- 这里
uv最好是绝对路径,推荐用which uv命令获取。
配置好后重启Claude桌面版,如果配置成功,就能看到对应的MCP服务端了。
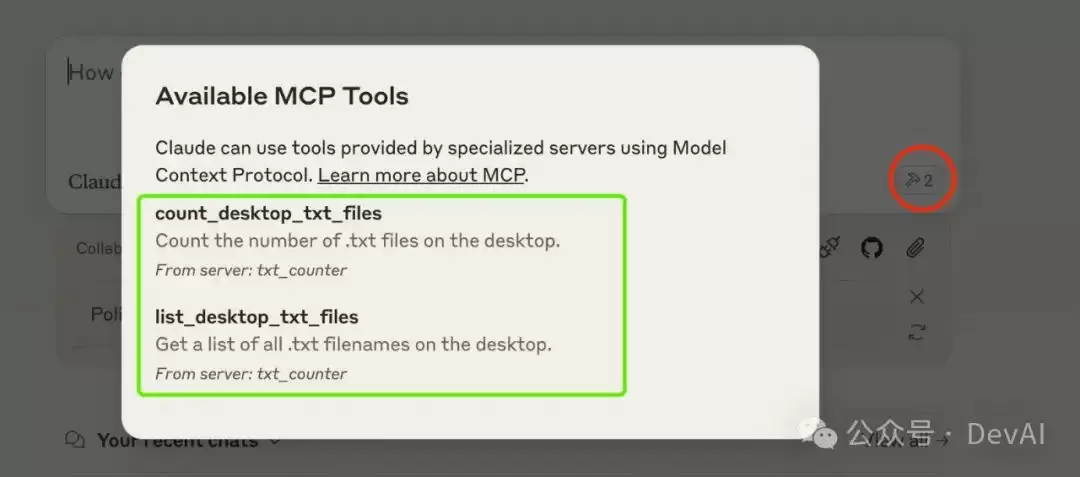
Step7. 实际使用
接下来,通过一个简单的提示词进行实际测试:
能推测我当前桌面上txt文件名的含义吗?它可能会请求你的使用权限,点击“允许本次对话”即可。
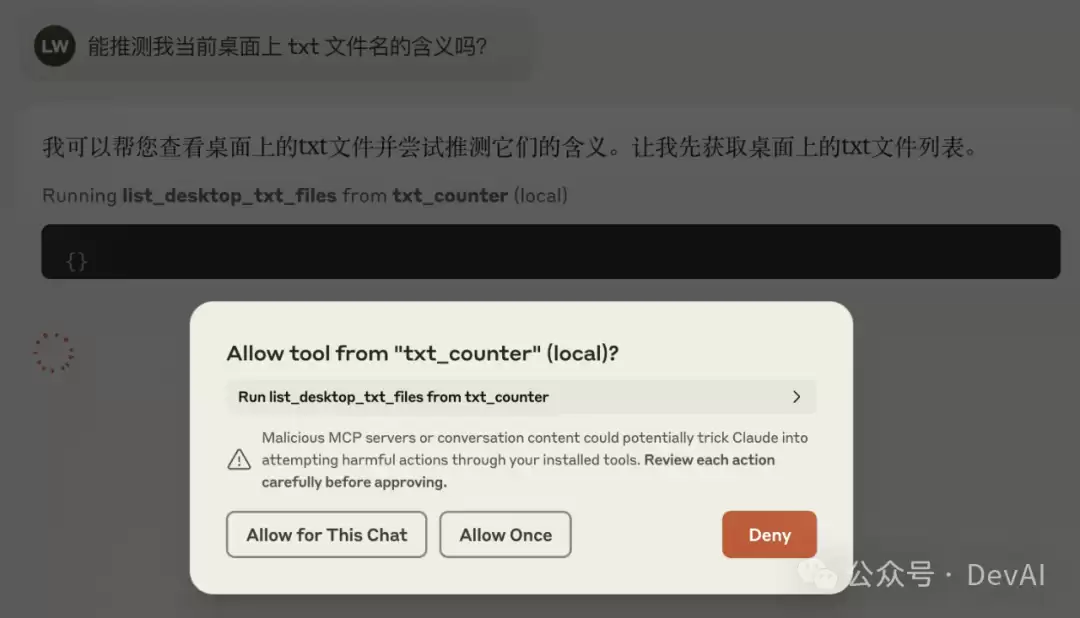

看起来,我们的MCP服务端已经正常工作了。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:MCP Model Context Protocol 一篇文章全面掌握要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看