




推理模型与行动链学习融合的Agent模型

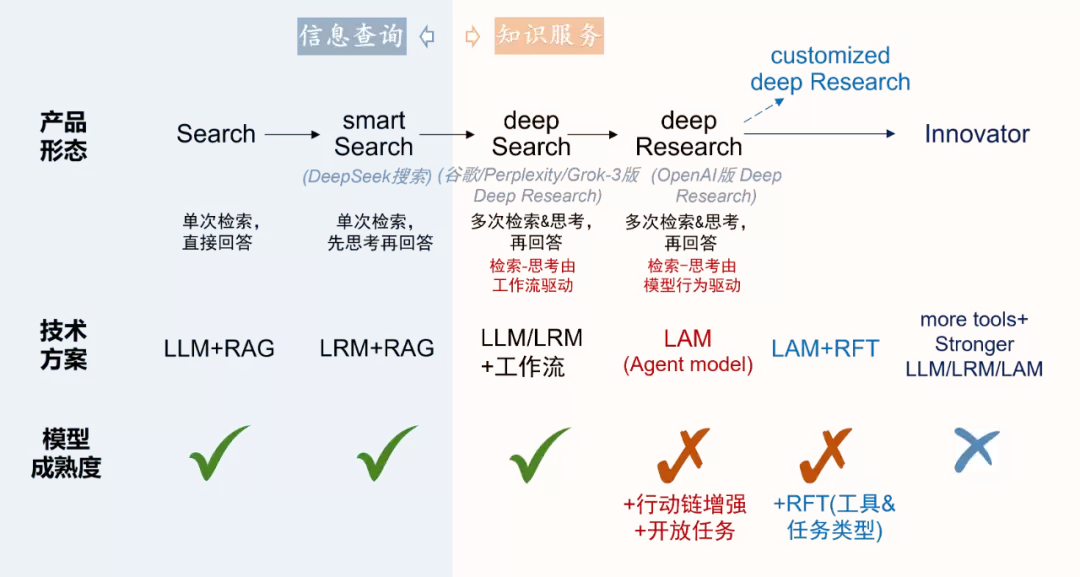
先说几个核心判断:AI正在从“会思考”走向“会行动”。OpenAI最近发布的Operator和Deep Research,不仅仅是产品层面的更新,它们标志着AI演进路线上一个关键的转折点——从IRL(推理模型)正式进入了Agent(智能体模型)时代。通往AGI的五个阶段:从聊天到行动OpenAI为这
先说几个核心判断:AI正在从“会思考”走向“会行动”。OpenAI最近发布的Operator和Deep Research,不仅仅是产品层面的更新,它们标志着AI演进路线上一个关键的转折点——从IRL(推理模型)正式进入了Agent(智能体模型)时代。
通往AGI的五个阶段:从聊天到行动
OpenAI为这条技术路线画了一幅清晰的进化图景。第一阶段是Chatbot,代表模型是GPT-3.5/GPT-4这些大语言模型(LLM)。第二阶段是Reasoner,以o1/o3为代表的大推理模型(LRM),它们学会了在回答前“先想一想”。
而现在,第三阶段Agent已经到来。Operator和Deep Research就是最好的证明。一个值得注意的细节是,OpenAI开始把“可替代的人类专家工时”作为模型能力的评估标准。这意味着,即便Agent模型在单个工具的使用上只达到普通人水平,但考虑到AI在信息获取和处理效率上的根本优势,它带来的生产力提升将是碘伏性的。
不过,Operator和Deep Research背后的技术,绝不是简单地把一个推理模型套上ReAct或Reflection这类Agentic工作流就完事了。它标志着模型能力本身的又一次升级。
那么,从推理模型到Agent,到底增强了什么能力?OpenAI透露,他们对o3模型的工具使用能力做了端到端的强化学习。这里要引入一个关键概念:我们把模型在推理过程中链式地调用工具的能力,称为行动链(Chain-of-Action, CoA)。而经过这种行动链学习的推理模型,我们姑且称之为大型智能体模型(Large Agent Models, LAMs)。

Agentic工作流 vs. Agent模型:本质区别在哪?
Agent模型的核心能力有两项:任务规划和工具使用。推理模型已经实现了任务规划的行为内化。在此基础上,进一步增强并把工具使用能力也内化到模型行为中的,就是Agent模型。
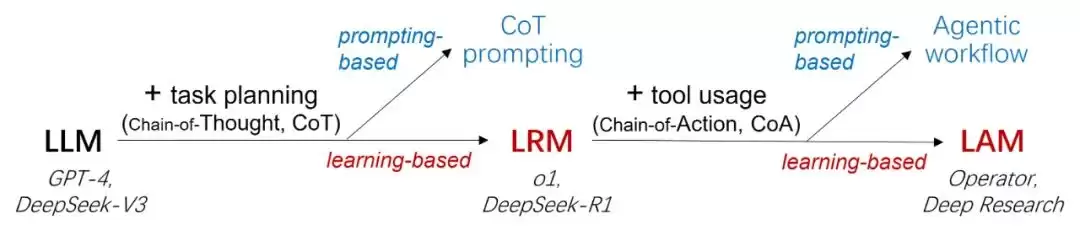
理解这一点,可以从推理模型的发展路径找类比。要让一个基础LLM具备推理能力(即生成思维链CoT),有两种思路。一种是基于提示词(Prompting-based)的方法,比如用CoT、ToT这类上下文学习技巧,来“逼迫”模型生成多步思考,也就是所谓的CoT prompting。另一种是基于学习的方法,无论是只用SFT,还是先SFT再加RL,或是直接上RL,最终得到像o1这样的推理模型。相比前一种工作流方法,后一种方式产生的思维链逻辑性更强,思考能递进式地深入。

同样的道理也适用于Agent。Agent需要进一步增加生成行动链(CoA)的能力。此前的Agentic工作流,用的也是类似的思路,是一种“被动”的行为——思考和行动的切换完全依赖预设的工作流和提示词框架。

而真正的Agent模型,是把耦合的思维链和行动链模式内化成了自身的本能。模型会“主动”地决定何时思考、何时行动。这样做的结果是,思考与行动之间的逻辑连贯性大大增强,能够支撑更长链的“思考-行动-观察”循环,从而解决更复杂的任务。
Agent模型:不仅仅是“能说话”和“能思考”
所以,Agent模型的定义是:在推理模型基础上,通过端到端的、面向任务的工具增强训练得到的模型。它能够自动生成耦合的CoT思维链和CoA行动链序列,其中每个动作都调用工具与外部环境交互,交互得到的反馈又指导后续的推理和动作,直到任务完成。
这背后是交互模式的根本改变。Chatbot和Reasoner只关注人与模型之间的二元交互。
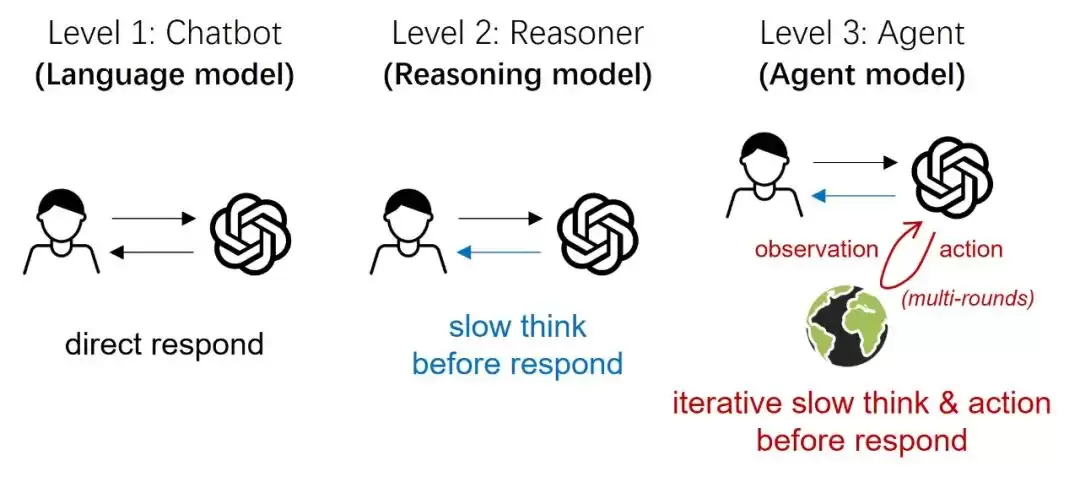
而Agent模型必须同时进行思考和行动,形乘人、模型和环境的三元结构:使用工具与环境交互获得反馈,经过多轮思考、行动和观测后,最终生成回复。
这里有个很关键的问题:如果模型在预训练阶段就已经学到了工具使用能力,并且这个能力继承到了推理模型中,我们还需要专门进行CoA学习吗?换句话说,CoT + A 是否自然就等于 CoA?
理论上,当预训练基座模型和推理模型的能力都足够强时,是存在这种可能性的。但讨论更一般的情况:预训练阶段的“工具使用”,关注的更多是单步行动能力,适合处理孤立任务,有点像学会了“单词”。而CoA学习是面向任务执行的端到端训练,学会执行一连串相互依赖的动作,形成逻辑性强、目标导向的行动序列,更像是“写文章”。
用做研究打个比方。研究生入学前就学会了查阅文献、做实验、画图这些基本技能。但只有从头到尾完整地完成一篇论文的研究和写作,才能真正掌握如何整合这些技能——比如根据导师反馈查新文献,根据新文献调整方法,再根据新方法重新设计实验。这就是CoA学习的价值。
训练Agent模型的两大难点
通过对推理模型进行端到端训练,让模型学会在推理过程中序列使用工具与外界互动,听起来很美好,但实际操作中有两个“硬骨头”。
问题一:平衡思考与行动
推理模型擅长一步步思考,但当你试图增强它的行动能力时,一个不小心它就可能忘了怎么思考。更关键的是,模型必须学会在推理过程中自主判断“何时该行动”。比如,当它意识到自己知识盲区时,能够主动触发搜索工具,获取新信息,再根据工具反馈继续推理,形成完整的“思考-行动-再思考”闭环。
问题二:处理与外部环境的交互
让模型通过工具与真实世界交互,成本太高,效率太低,风险也不小。尤其是环境本身是动态变化的,比如在线强化学习时,网络延迟、搜索结果波动都会让训练过程变得极不稳定。
以OpenAI的Deep Research为例,它的核心能力是通过网络搜索完成复杂研究任务,就必须同时解决这两个问题:判断“什么时候该查资料”(不能过度依赖搜索,也不能盲目自信),以及如何在动态且高成本的环境下进行高效RL训练。
一个可行的训练框架:AutoCoA
我们以开放领域问答任务为例,限定只使用网页搜索工具,来探索一种训练Agent模型的方案:AutoCoA。
这个方案包含两个核心阶段:SFT阶段,手把手教模型“何时”以及“如何”调用工具;RL阶段,面向任务目标,优化多步思考和行动的整体决策。
为了解决平衡思考与行动的问题,AutoCoA在SFT和RL阶段都混入了不调用工具的纯链式思考数据,确保模型不会“忘了”推理能力,并能根据任务难度自适应决定是否调用工具。此外,它把“何时行动”和“如何行动”在SFT中拆成两个阶段来教:先在step-level设计对比损失,让模型学会行动时机,再在trajectory-level训练模型生成工具参数。
为了解决与真实环境交互的高成本问题,AutoCoA让模型学习一个内置的“世界模型”来模拟环境。SFT的最后增加一个阶段,训练策略模型模拟工具调用并生成相应的observation。然后在RL阶段,模型先大量地基于这个内置世界模型生成observation进行roll out,快速收敛;最后才进行少量的真实工具调用,微调一下,确保模型能够适应真实场景。
实验效果:Agent模型完胜Agentic工作流
在6个开放域问答数据集上的测试结果相当清晰。对比了纯模型的baseline和各类Agentic工作流方案,经过CoA学习的各种Agent模型方案,效果都显著优于Agentic工作流。SFT阶段的step-level对比学习也起到了关键作用。
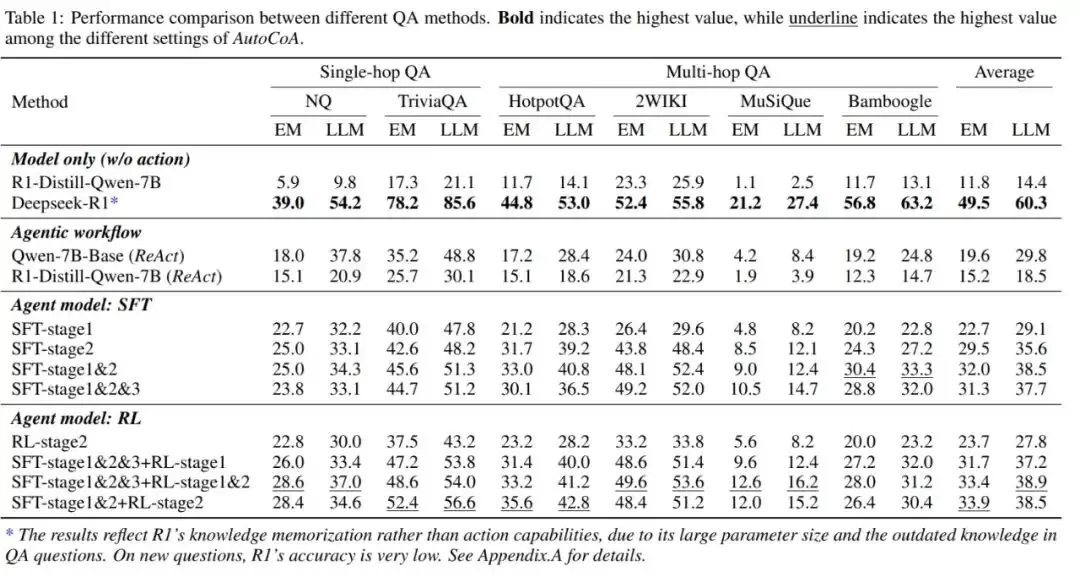
值得一提的是,在RL过程中,当内置世界模型和真实世界交互的比例达到5:1时,最终全真实世界交互的结果反而稍优于混合交互方案。这说明内置世界模型的学习足够好的话,可以大大降低对真实环境的依赖。
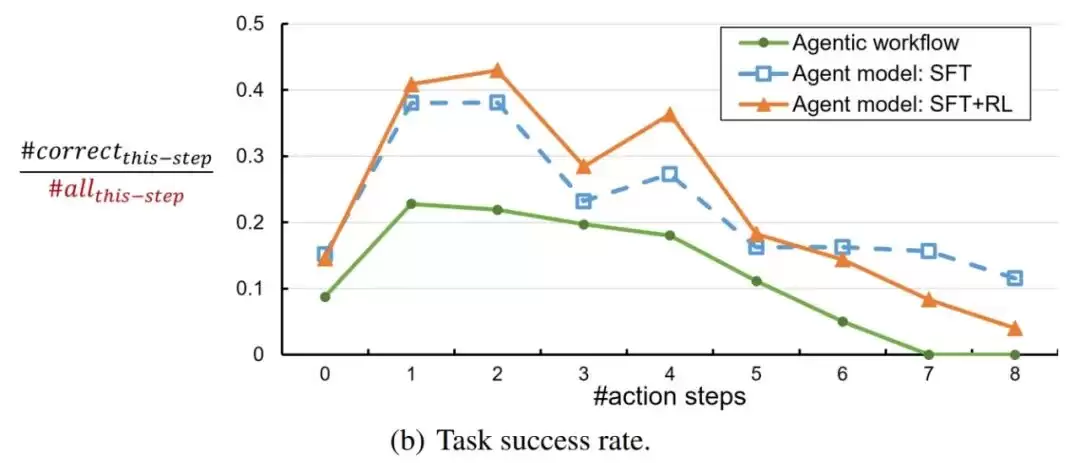
进一步分析也验证了,经过面向任务的端到端训练,Agent模型确实学会了思考与行动之间的切换模式,展现出了支持更长思考/行动轮次的能力。
结论与展望:Agent训练的未来
随着语言建模和逻辑推理能力的提升,像Deep Research这样的应用仅靠网络搜索和文档解析这类基本工具,就完成了极其复杂的研究任务。这揭示了一种通用的Agent训练方法:一旦模型的推理能力超过某个阈值,只需提供一些简单的工具和一个在受控环境内可验证的任务目标,就能实现Claude 3.7官方博客所描述的“Action Scaling”——行动的规模效应。
当然,AutoCoA只是一个初步尝试。展望未来,有很多值得探索的方向:改进的CoA数据合成、纯RL的训练路线、新的融合CoT和CoA的损失设计、更优的RL奖励函数。从任务场景来看,如何训练能够处理没有明确结果的开放式任务的Agent模型,也是重要的课题。最后,就像训练领域推理模型一样,应用强化微调(AgentRFT),针对特定任务和专业工具微调通用Agent模型,获得领域专用的Agent模型,是下一步非常清晰的发展路径。
以Deep Research代表的知识研究功能为例,下一阶段的发展方向就是“定制化的深度研究”(Customized Deep Research),这依赖于上述AgentRFT技术的成熟。
最后,一个值得注意的现实问题是:目前多数开源推理模型的工具使用能力,尤其是多轮工具使用能力,普遍还比较弱。正如前面提到的,当预训练基座模型的工具使用能力和推理模型的推理能力足够强时,CoA能力完全有可能通过直接RL或在推理模型中自然涌现。这再次印证了预训练和后训练交替增强、共同促进模型能力提升的规律。
Claude3.7提出的“混合推理”概念(同一个模型同时具备快思考和慢思考能力)也暗示了未来的一种可能性:从LLM到LRM再到LAM的演进,也许不是几个分明的阶段,而是一个平滑的连续谱。到那时,所谓的“Level1”到“Level3”可能不再是不同模型的严格区分,而是面对不同功能需求时的不同产品形态。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:推理模型与行动链学习融合的Agent模型要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点Daetama是面向数据科学面试和SQL能力提升的练习平台,已收录超100个覆盖基础到进阶的SQL题目,求职板块与课程模块在开发中,团队保持每周更新节奏,提供系统性刷题与模拟面试场景。
SpeakMulti是一款AI驱动的配音平台,可将YouTube视频翻译成多种语言,保留原始说话者的音色和语调,降低本地化成本。用户提交视频并选择目标语言后,AI自动完成配音,并由专家团队审核,确保准确自然。
需求人群 如果你经常需要从图片中提取文字——例如整理截图内容、翻译图片里的外语文本、识别带有水印的图片信息——那么 Umi-OCR 无疑是一款相当实用的工具。它完全在本地运行,无需联网,对隐私保护极为友好。 产品特色 这款工具的核心亮点都集中在实用性上。截屏识别操作非常顺手,按下快捷键即可框选区域,
艺术创作与人工智能的融合,正在开启一个全新的创作时代。moonlightai 正是这样一款AI绘画工具,能够帮助用户通过人工智能快速生成不同风格的绘画作品——无论你想复刻文艺复兴时期的古典优雅,还是为画作注入梵高般炽热的笔触,甚至从艾沃佐夫斯基的海浪星空中汲取灵感,它都能轻松实现。 需求人群 简单来
- 日榜
- 周榜
- 月榜
热点快看