




昇腾实现智谱GLM-5 744B模型单机高效推理

2026年2月12日,智谱AI正式发布了GLM-5——这款被誉为Agentic Engineering时代最具代表性的开源模型。从“写代码”到“写工程”,模型能力实现了跨越式提升。在编程与智能体(Agent)能力方面,GLM-5达成了开源模型的最优水平,真实开发场景下的使用体验已接近Claude Opus 4.5,尤其在复杂系统工程与长周期Agent任务中表现出色。值得一提的是,昇腾持续与智谱GLM系列保持同步适配,本次GLM-5开源后,昇腾AI基础软硬件在第一时间完成了0天适配,全面支持推理部署与训练复现。
更大参数规模,更强大的智能水平
- 参数规模扩展:模型参数从355B(激活32B)扩展至744B(激活40B),预训练数据量从23T提升至28.5T。更大的模型规模与更充裕的训练算力,切实推动了通用智能水平的跃升。
- 异步强化学习:采用全新“Slime”框架,支持更大规模模型与更复杂的强化学习任务,显著提升了后训练流程效率。同时引入异步智能体强化学习算法,使模型能够从长程交互中持续学习,充分释放预训练潜力。
- 稀疏注意力机制:首次集成DeepSeek Sparse Attention,在保证长文本效果的前提下,大幅降低部署成本,同时提升Token处理效率——这笔投入回报相当可观。
编程能力:对齐Claude Opus 4.5
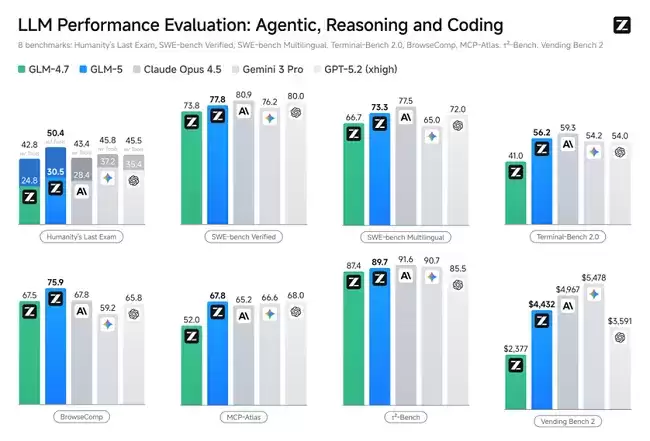
GLM-5在SWE-bench-Verified与Terminal Bench 2.0两项评测中分别取得77.4和55.7的成绩,均为开源模型最高分,并将Gemini 3.0 Pro甩在身后。
智能体能力:长程任务执行达到SOTA级
在多项Agent评测基准上,GLM-5均拿下开源第一。BrowseComp(联网检索与信息理解)、MCP-Atlas(工具调用与多步骤任务执行)、τ²-Bench(复杂多工具场景下的规划与执行)——全部取得最优成绩。
再来看看经营能力——Vending Bench 2中,GLM-5同样位居开源最佳。该测试要求模型在一年期内经营一个模拟自动售货机业务,最终账户余额达到4432美元,经营表现接近Claude Opus 4.5。长期规划与资源管理能力确实令人印象深刻。
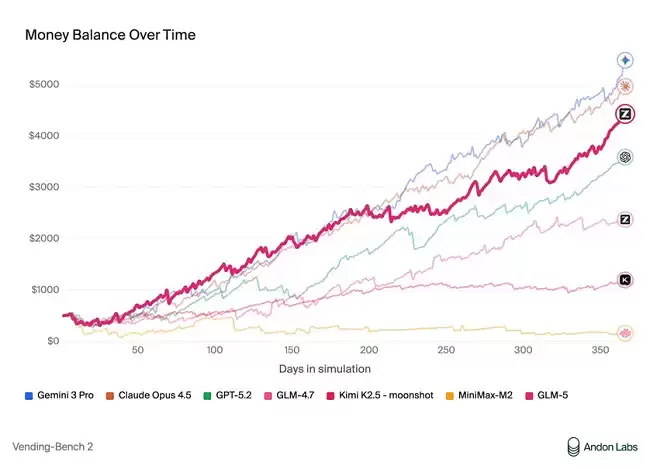
这些能力恰恰是Agentic Engineering的核心:模型不仅需要会写代码、完成工程任务,更要在长程任务中保持目标一致、有效管理资源、处理多步骤依赖关系——这才是真正Agentic Ready基座模型应有的表现。
基于昇腾实现GLM-5的混合精度高效推理
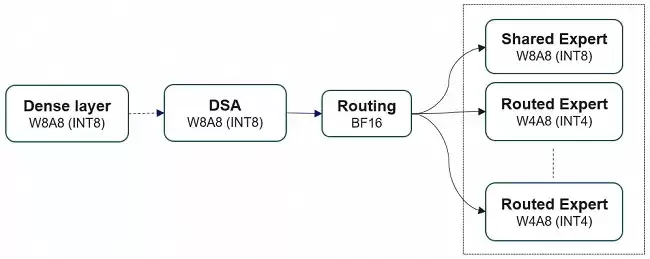
昇腾支持对GLM模型进行W4A8混合精度量化,744B超大参数模型基于Atlas 800 A3即可实现单机部署。
GLM-5是78层decoder-only大模型:前3层为Dense FFN,后75层为MoE(路由专家+共享专家),自带一层MTP(Multi-Token Prediction)用于加速解码。针对这一结构,昇腾对权重文件采用W4A8量化,显著降低显存占用,大幅提升Decode阶段执行速度。同时,利用Lightning Indexer、Sparse Flash Attention等高性能融合算子,加速端到端推理执行。目前支持vLLM-Ascend、SGLang和xLLM这几种主流推理引擎的高效部署。
- 权重下载:https://ai.atomgit.com/atomgit-ascend/GLM-5-w4a8
- 推理部署:https://atomgit.com/zai-org/GLM-5-code/blob/main/example/ascend.md
昇腾W4A8量化,极大降低显存占用
采用易扩展的MsModelSlim量化工具,全程轻松量化
1、按模块区分量化比特与算法:例如Attention与MLP主体采用W8A8,MoE专家采用W4A8;gate这类对量化敏感的层可按需回退,避免精度损失过大。
2、一键即可完成量化:支持GLM-5量化全流程——“预处理+子图融合+分层线性量化”,安装后一条命令行即可轻松搞定:msmodelslim quant --model_path ${model_path} --sa ve_path ${sa ve_path} --model_type GLM-5 --quant_type w4a8 --trust_remote_code True
MsModelSlim提供丰富量化策略,实现快速精度对齐
- 旋转Quarot算法:对权重进行Hadamard旋转与LayerNorm融合,降低激活异常值,改善量化后的数值分布。
- 多种离群值抑制算法:采用Flex_AWQ_SSZ算法与Flex_Smooth_Quant算法的混合策略,权重使用SSZ(Smooth Scale Zero)标定,支持缩放因子等超参数调整。
- 线性层量化策略:对单层Linear执行W8A8或W4A8量化,激活值按per-token粒度,权重按per-channel粒度。
高性能融合算子,加速推理执行
1、Lightning Indexer融合Kernel
在长序列场景下,TopK操作极易成为性能瓶颈。引入Lightning Indexer融合算子,将Score Batchmatmul、ReLU、ReduceSum、TopK等操作整合到一起,利用TopK计算耗时流水来掩盖其他操作耗时,从而提升计算流水收益。
2、Sparse Flash Attention融合Kernel
引入SFA,包含从完整KVCache中选取TopK相关Token以及计算稀疏Flash Attention的操作,通过离散聚合访存耗时掩盖其他操作耗时。
3、MLAPO融合Kernel
GLM-5在Sparse Flash Attention预处理阶段会对query和KV进行降维,并将query降维后的激活值传递给Indexer模块进行稀疏选择处理。近期将引入MLAPO,通过VV融合(多个Vector算子融合)技术,将前处理过程中的13个小算子直接融合成1个超级大算子。在MLAPO算子内部,还可通过Vector与Cube计算单元的并行处理及流水优化进一步提升性能。
基于昇腾实现GLM-5的训练复现
GLM-5采用了DeepSeek Sparse Attention(DSA)架构。针对DSA训练场景,昇腾团队设计并实现了昇腾亲和融合算子,优化方向主要有两个:一是优化Lightning Indexer Loss计算阶段的内存占用,二是利用昇腾Cube与Vector单元的流水并行提升计算效率。
训练部署指导:https://modelers.cn/models/MindSpeed/GLM-5

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

中国牵头全球首个自动驾驶世界标准 L3/L4上路新阶段
2026年6月,联合国世界车辆法规协调组织通过全球首个自动驾驶技术法规,由中国等多国共同牵头。法规明确L3 L4级系统安全要求、全生命周期管理及测试方法,将于同年7月生效。中国同步推进强制性国家标准,衔接国际规则,推动自动驾驶进入合规新阶段。

当贝耳机Air 1正式发布,AI软硬件一体化全面落地
提到当贝,许多人首先想到的便是“大屏”这一关键词。 这一点并不难理解。从服务超两亿用户的软件生态,到“每卖出两台激光投影,就有一台是当贝”的市场份额,这家智能科技企业在客厅场景中的影响力已十分稳固。然而,当贝的愿景显然不止局限于客厅。近期,当贝正式发布了其首款AI耳机——当贝耳机 Air 1。这绝非

万元起 杜卡迪全新揽途Multistrada V4 Rally上市
杜卡迪全新揽途MultistradaV4Rally上市,起售价23 8万元。搭载V4Grandturismo发动机,标配自动降低装置、Skyhook悬挂及前后雷达,兼顾长途探险与运动性能。翡翠绿版限量10台,售价24 1万元。

美团CEO王兴自公司成立从未卖股且无计划
在6月26日的美团股东大会上,CEO王兴放出了一个相当直白的表态:从公司成立至今,他个人手里的股票一股都没卖过,而且未来也没有任何减持计划。这话放在当前的市场环境下,分量不言而喻。 王兴还专门解释了去年那笔备受关注的股票转让——2024年他将个人持股的10%捐给了一家基金会。他强调,这完全是出于公益

芯明与钧舵机器人正式启动战略合作 深度融合生态共进
1月22日,钧舵机器人与芯明智能等企业签署战略合作协议,旨在从芯片级到系统级融合机械结构、感知与控制算法,打造低成本、高灵活性的智能末端执行器,推动具身智能生态共建。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-05 14:36
2026-07-05 14:36
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:33
2026-07-05 14:33
热门教程
2026-07-05 14:36
2026-07-05 14:36
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:34
2026-07-05 14:33
2026-07-05 14:33
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
