




图解强化学习GRPO算法原理与手算步骤详解

在强化学习与大语言模型对齐的研究中,PPO算法以其出色的训练稳定性与效果而备受推崇。然而,其经典的Actor-Critic双网络设计也伴随着较高的计算资源消耗与复杂的超参数调优挑战。本文将深入解析一种旨在克服这些挑战的创新算法——GRPO(分组相对策略优化),探讨其如何以更精简的架构实现高效对齐。
GRPO 算法的基础认识
GRPO,全称为分组相对策略优化,可被视为PPO算法的一种高效简化版本。其核心理念非常直接:摒弃独立的价值网络评估,转而利用同一提示词下生成的多组回答进行内部奖励比较,以此替代PPO中复杂的优势函数估计过程。
具体而言,针对给定的提示,模型会并行生成多个候选回答,并获取每个回答的奖励评分。GRPO算法并不关注奖励的绝对数值,而是聚焦于这些评分在组内的相对排序与分布(例如通过归一化处理),从而判断哪些回答更优,并据此指导策略网络的更新。同时,它完整继承了PPO的核心稳定机制——策略更新裁剪,确保每次迭代的调整幅度可控。此外,算法引入了KL散度正则项,有效约束优化过程中的策略偏移,保障模型的基础能力与知识不会在微调中退化。
因此,GRPO的设计目标清晰明确:在维持甚至提升长文本推理与训练稳定性的前提下,大幅降低大语言模型进行人类反馈强化学习所需的显存开销与计算成本。
GRPO 算法的网络结构
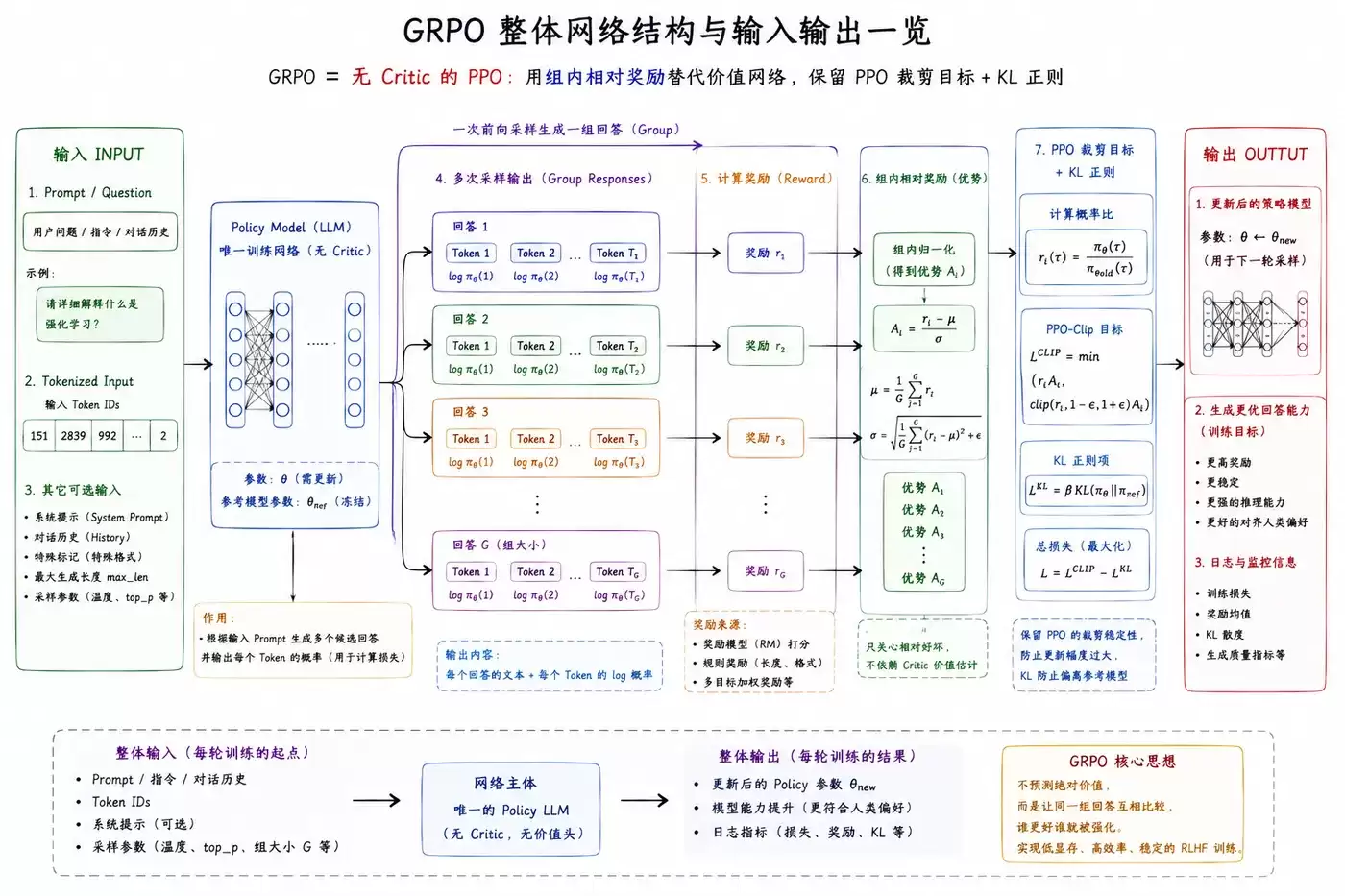
GRPO的网络结构是其“极简”设计哲学的直接体现。
Actor网络
唯一的可训练网络: 在GRPO框架中,需要被训练的网络有且仅有一个,即作为策略网络的Actor模型。
输入与输出: 它接收文本状态(提示词),并输出对应的动作(文本序列)、该动作的生成概率对数,以及与参考模型之间的KL散度值。
核心职能: 该网络承担了内容生成与提供训练信号的双重任务。整个训练流程,包括策略的迭代优化,都围绕这单一网络展开。
关于其架构,有几点关键说明:
首先,GRPO的结构极为精简。它移除了传统的Q网络、价值网络、目标网络,甚至无需学习温度参数,架构干净利落。
其次,训练过程中会固定一个参考模型(通常为初始的监督微调模型)。该模型参数冻结,不参与梯度更新,其唯一作用是作为计算KL散度正则项的基准锚点,防止当前策略过度偏离。因此,它不被计入可训练网络。
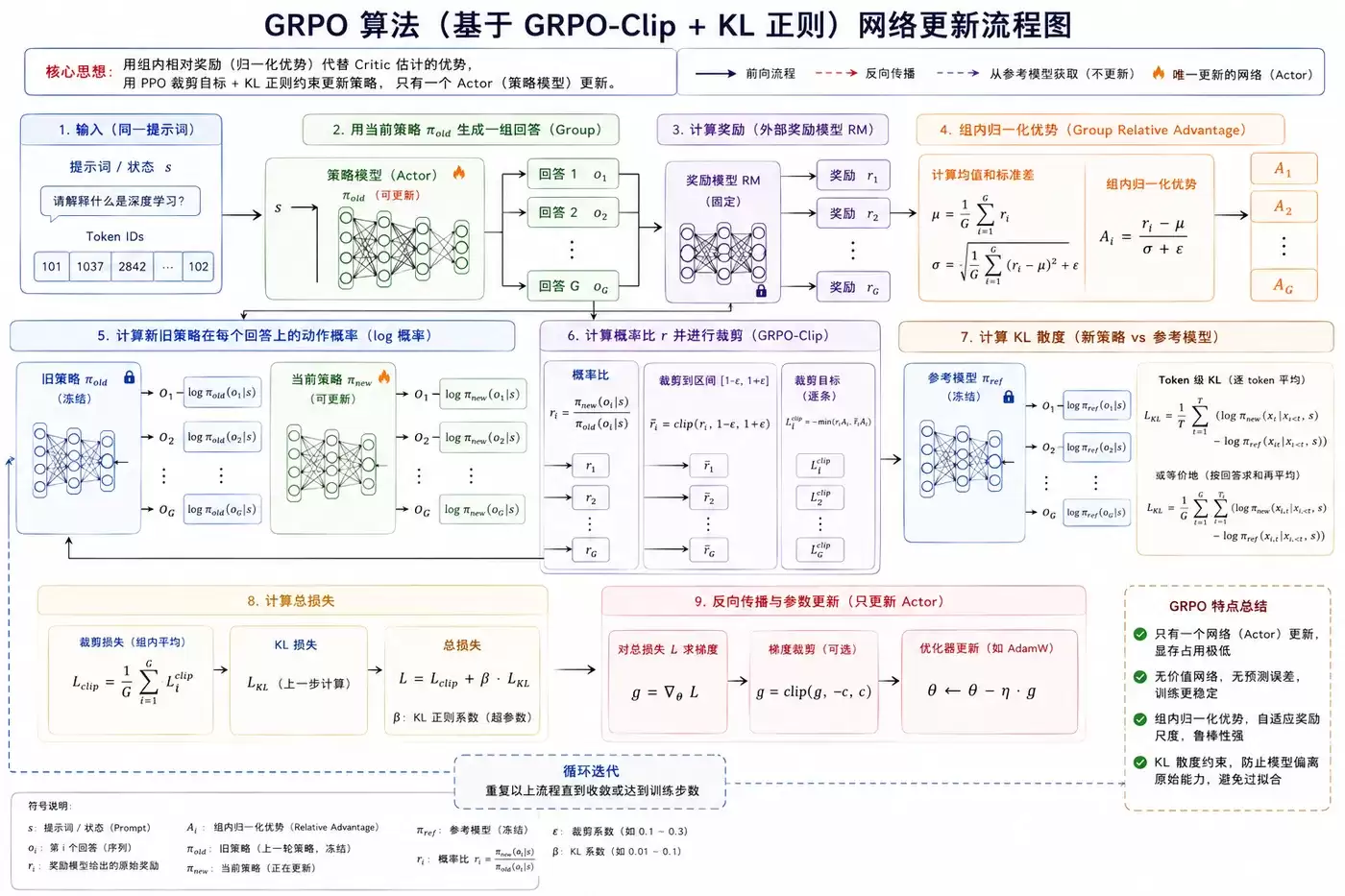
网络更新
GRPO的更新机制融合了PPO的精华并进行了关键创新。
核心损失函数: GRPO-Clip裁剪损失 + KL散度正则损失。
根本目标: 通过策略更新,使同一组回答中质量更高的输出拥有更高的生成概率,同时严格限制更新步长,确保训练过程稳定,避免模型性能崩溃或严重偏离原始分布。
更新流程与输入:
每次策略更新需要准备以下输入数据:
- 状态/提示词 (s)
- 旧策略下的动作概率 (π_old)
- 新策略下的动作概率 (π_new)
- 组内归一化优势 (A),该值来源于对同一提示词下多个回答的奖励进行组内计算与归一化处理。
- 参考模型的概率分布 (π_ref),用于计算KL散度。
计算步骤可概括如下:
- 计算新旧策略的概率比率:r = π_new / π_old。
- 将该比率裁剪至预设的安全区间,例如 [1-ε, 1+ε]。
- 通过公式 min(r*A, clip(r)*A) 计算得到裁剪损失项。
- 计算当前策略与参考模型之间的KL散度。
- 总损失 = 裁剪损失 + β * KL散度(其中β为正则化系数)。
- 最后,通过反向传播算法,更新唯一的Actor网络参数。

这种设计带来了若干显著优势:
- 显存占用大幅降低: 仅需维护和更新一个网络,极大节约了GPU显存资源。
- 训练过程高度稳定: 由于无需估计价值函数,彻底避免了因价值网络估计偏差带来的训练波动与不稳定性。
- 有效防止模型退化: KL散度约束如同“安全绳”,确保模型在优化特定目标时,其原有的语言理解与生成能力得以保留。
- 降低奖励尺度敏感度: 基于组内归一化的优势计算方式,使得算法对奖励函数的绝对数值范围不敏感,减轻了超参数调整的负担。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

广东人工智能发展务实创新引领产业升级
人工智能发展重心转向产业落地。广东以制造业痛点为导向,通过政策、资金和平台支持,加速AI场景化应用。企业积极利用AI解决生产难题,形成可复制新模式。面对供需错配等挑战,广东正通过区域协同与创新,构建全域协同的AI生态,推动技术深度融入实体经济。

教学流程图绘制教程 在线制作简单快速上手
教学流程图将教学方案可视化,有助于梳理思路、优化设计。其图形符号有规范,如长方形代表教师活动。利用BoardMix等在线工具可便捷绘制,支持颜色区分主体、标记媒体形式,并能协作编辑。常见类型包括逻辑演绎型、探究发现型等,可根据不同教学目标灵活选用。

Gerresheimer与Newel Health合作推进制药业数字化升级
瑞士数字医疗专家NewelHealth与德国包装巨头Gerresheimer达成战略合作,旨在助力制药行业数字化转型。双方将结合软件技术与硬件经验,共同开发数字医疗设备及混合疗法方案,帮助药企整合数字终点与真实世界数据,优化临床开发与产品部署,无需自建完整技术体系。

万能活动策划方案模板:从零到一高效执行指南
活动策划需系统规划以确保可执行。方案应明确目标、主题、受众、时间、形式、推广渠道及应急预案七大核心要素。执行阶段需细化物料清单与流程进度表,通过可视化工具管控全局,从而提升活动效率与成功率。

Newel Health与Gerresheimer合作推动制药行业数字化升级
NewelHealth与Gerresheimer达成战略合作,为制药行业提供一站式数字化解决方案。双方结合软件算法与智能硬件优势,协助药企设计数字化临床试验终点、开发医疗软件并构建真实世界数据平台。合作还将开发融合药物、设备和数字技术的混合疗法,顺应FDA监管便利,助力药企高效推进数字化进程。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
