




RAG+前沿动向:长文本、投标写作与R1可解释性探索

近期RAG前沿动向聚焦于R1与递归检索的融合、秘塔搜索的小大模型协同方案、FineFilter细粒度噪声过滤技术、RAG与GraphRAG系统评估方法、投标文档自动生成工具、长文本处理的NSA与MoBA方法,以及R1推理链可视化探索等关键进展。
在RAG技术快速迭代的当下,几个值得关注的趋势正悄然改变长文本处理与投标写作的方式。我们将聚焦于Ktransformer误区、长文本新策略、投标文件写作项目、RAG输入去噪、RAG与R1的结合,以及秘塔基于浅层搜索的深度研究方案。这些话题既涉及技术突破,也涵盖工程落地,值得深入剖析。
要深入研究,必须专题化、体系化。以下是对近期亮点的详细拆解,希望能为同行提供有价值的参考。
一、关于RAG+的一些进展
1、RAG+R1结合进展
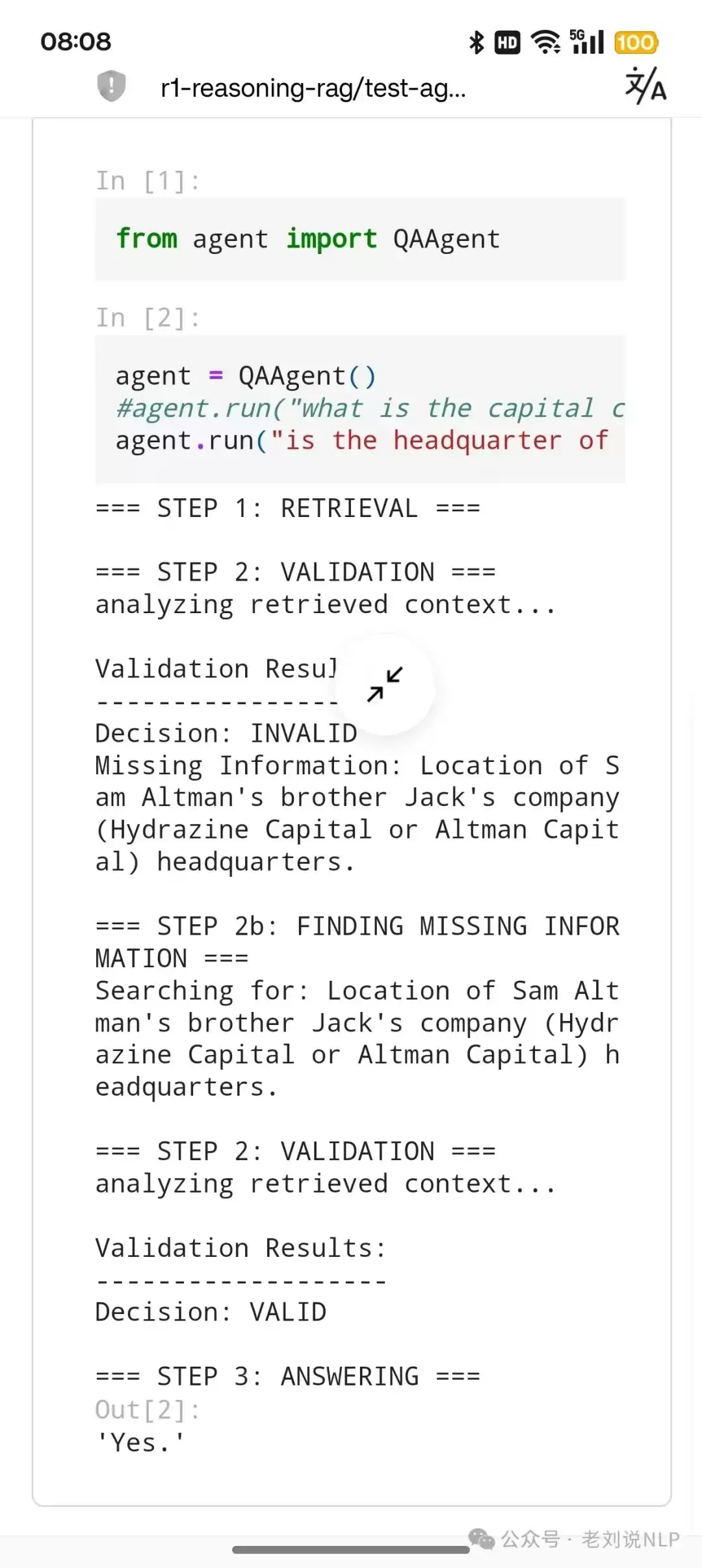
r1-reasoning-rag项目将DeepSeek R1的推理能力与递归式RAG相结合,核心思路是:利用R1的推理主动检索、丢弃、综合知识库中的信息,以回答复杂问题。代码简洁,仅包含三个脚本(llm、prompts、agent),基于LangChain构建,是一个直接但有效的演示。项目地址:github.com/deansaco/r1-reasoning-rag。
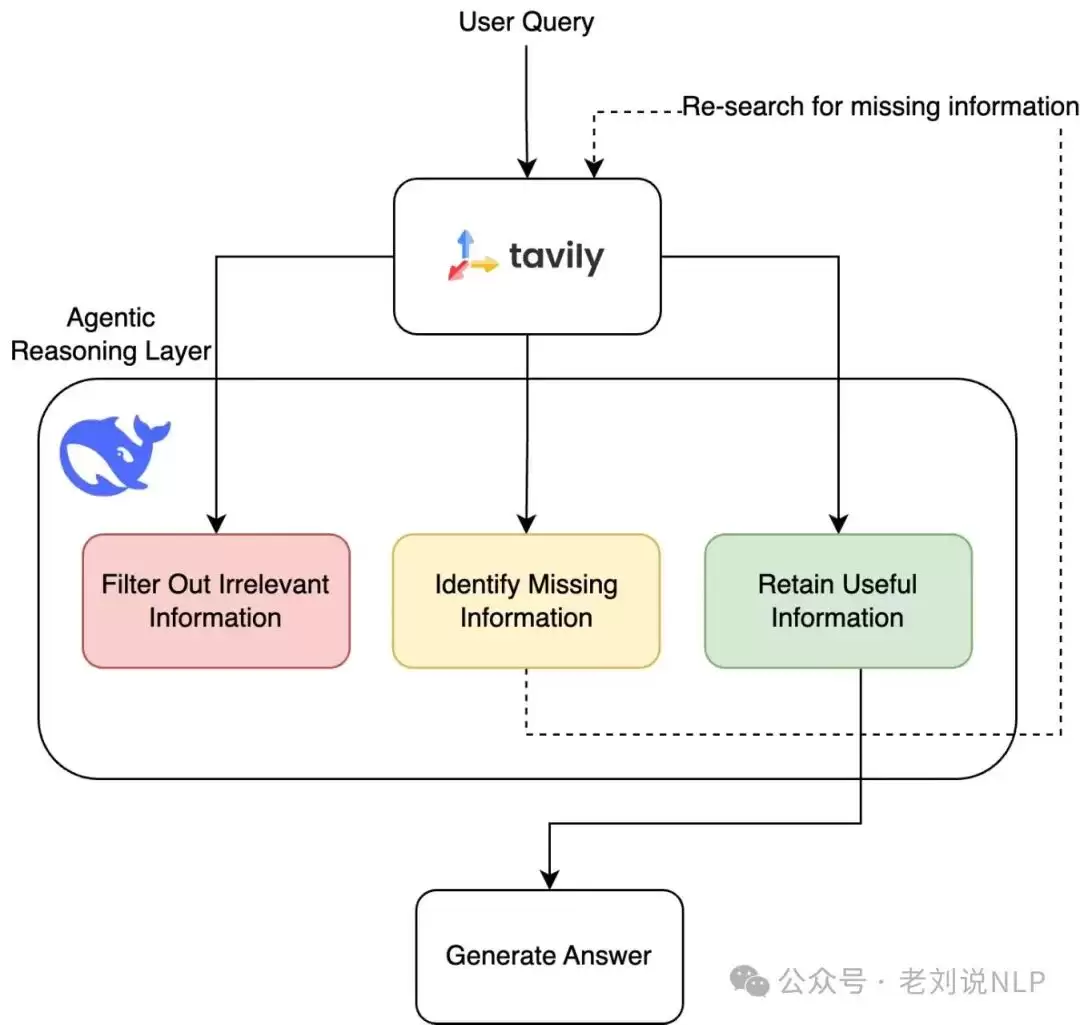
3、关于秘塔搜索的deepresearch方案
这一模式值得关注——先构思后搜索,先搜索再扩展。让模型先提出思考框架与路径,再整合资料。秘塔采用“小模型+大模型”协同架构:需要深度推理的框架思考、步骤拆解交由DeepSeek R1完成;同时,信息搜索、资料整合等可以快速完成的任务交给自研小模型处理,从而在2-3分钟内完成数百个网页的搜索与分析。

2、关于RAG中的embedding选型
embedding选型可参考HuggingFace上的MTEB和C-MTEB排行榜。参数并非越大越好,关键是根据服务器规格和应用场景多比较几个模型。此外,text reranking模型同样值得关注——它常是提升检索精度的隐形杠杆。
3、关于RAG的一个输入去噪工作
FineFilter提出了一种细粒度噪声过滤机制,通过句子级别的MinMax优化来识别并保留有效答案线索。工作流程包含三个模块:
- 过滤问题线索提取器:用包含答案的句子及其相似句子作为微调目标,提取潜在线索,并通过信息增益计算相关性。
- 重排器模块:通过成对损失函数训练,优化句子排名,利用生成模块的真实反馈标注训练数据。
- 自适应截断器模块:根据问题复杂性和文档内容,捕获最少的必要线索,并用LLM预测截断点。
在NQ、TriviaQA、HotpotQA三个开放域问答数据集上,FineFilter显著优于基线模型(采用LLaMA3-8B-Instruct和Mistral-7B-Instruct,LORA微调,EM和F1评估)。

4、RAG进展:RAG vs. GraphRAG系统评估
一份系统对比评估(arXiv:2502.11371)总结了关键发现。RAG采用语义相似度检索,将文本分块后用text-embedding-ada-002索引,检索Top-10块并用Llama-3.1生成响应。GraphRAG则选取两种代表方法:基于知识图的GraphRAG和基于社区的GraphRAG(后者进一步分为局部搜索和全局搜索)。
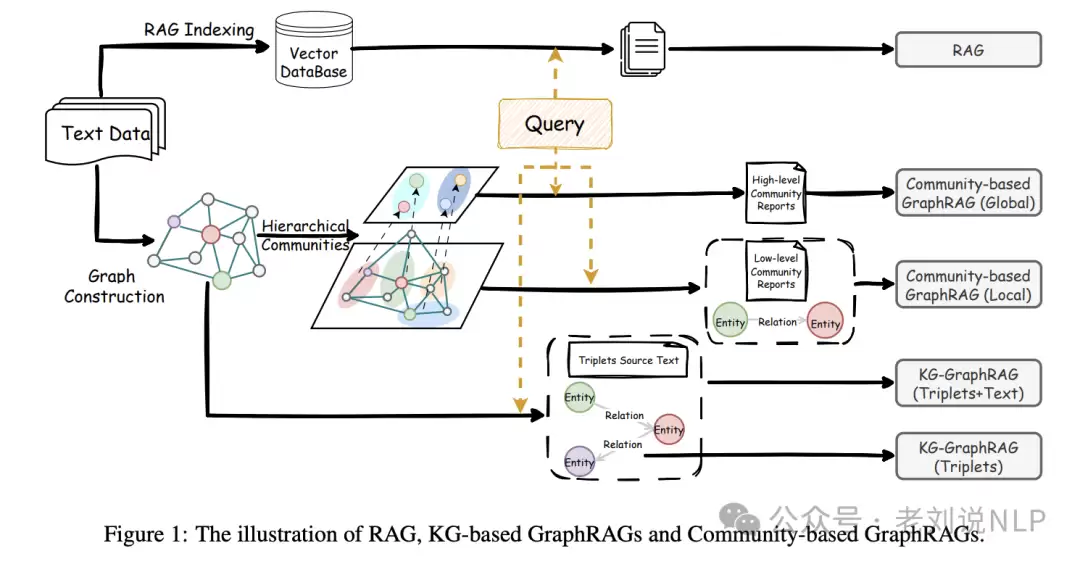
数据集涵盖四个问答数据集(Natural Questions、HotpotQA、MultiHop-RAG、NovelQA)和四个查询式摘要数据集(SQuALITY、QMSum、ODSum-story、ODSum-meeting)。评价指标包括Precision、Recall、F1、Accuracy(问答)和ROUGE-2、BERTScore(摘要)。
结论:RAG在单跳问题和需要详细信息的查询上表现更优;GraphRAG(尤其是基于社区的)在多跳问题上更有效。但社区GraphRAG的全局搜索因只检索高层社区信息而表现不佳。查询式摘要任务中,RAG在多文档摘要数据集上表现良好,社区GraphRAG的局部搜索优于全局搜索,集成策略与RAG单独表现相当。
二、长文本、投标协作以及R1可解释性的一些有趣探索
1、项目投标写作实现
社区成员开发了一个投标文件八股文写作工具(github.com/riddle911/autobid),基于Gemini Flash,可在几分钟内自动生成10万字的技术文档(已用于非正式投标场景)。核心在于prompts.py中几个prompt的构造:
- 生成大纲(耗时30秒至1分钟):让模型根据评分标准和技术要求生成大纲,区分system和user角色。
- 生成完整文档(约220秒,消费约0.09美元):为每个章节单独开上下文窗口,预置system role,通过user依次提交章节大纲和content summary,确保内容边界清晰。
- 工程层面处理了章节生成、拼接以及同一时间多次请求的管理。
该项目虽然粗糙,但可作为思路引子,有兴趣的开发者可以在此基础上独立完成正式工具。
2、关于Ktransformer的一些任务误区
近期关于Ktransformers的报道较多,存在不少误解。务必阅读一手信息源,细节总在原文档中。可参考:相关文章。
3、关于长文本进展:kimi与deepseek对狙
DeepSeek发布了Native Sparse Attention(NSA),核心是在计算注意力时只关注最重要的部分,采用动态层次稀疏策略:通过粗粒度标记压缩和细粒度标记选择保留全局上下文意识和局部精度。两个重点:一是将键和值组织为时间块,通过压缩token、选择性保留token和滑动窗口三条路径处理;二是硬件对齐系统优化块稀疏注意力以利用Tensor Core。
与此同时,Kimi发布了MoBA(Mixture of Block Attention),思路来自MOE:将长上下文切分为块,用智能路由器动态挑选对当前查询最重要的块。核心点:块划分和路由策略(门控机制选块)、混合模式(可在MoBA和全注意力间切换以平衡效率)、因果关系保持(通过因果掩码确保当前块注意力)、细粒度块分割以提高性能。
4、关于R1推理链条的可解释
frames of mind项目(github.com/dhealy05/frames_of_mind)将R1的思维过程可视化为图形。实现思路:将思想链保存为文本 → 使用OpenAI API转换为嵌入 → 使用t-SNE按顺序绘制嵌入。每个点代表一个思维步骤,数字为步骤编号。纵坐标表示连续思维步骤间的余弦距离(标准化到0-1),直观呈现R1思维的跳跃程度。图中灰色线条为不同思维序列,蓝色线条为所有序列的平均值,清晰展示了R1思维的波动规律。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:RAG+前沿动向:长文本、投标写作与R1可解释性探索要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点iCAR V27上市后的首次大规模OTA升级终于来了,这次更新覆盖了智能驾驶、主动安全和智能座舱三大板块,新增和优化的功能加起来超过140项。新系统会分批推送给所有V27车主,逐步完成全量更新。 智能辅助驾驶:更贴近日常场景 iCAR V27全系标配的超级猎鹰700+智驾系统,硬件基础来自地平线征程
随着城市出行需求持续升级,什么样的纯电代步车才能真正打动都市家庭?眼下,一款名为缤果PRO的车型正在悄然走红,尤其成为女性车主群体的新宠。上市仅一个多月,车主队伍便迅速壮大到数万人——她们不仅依靠这辆车开启了全新的通勤方式,还在社群里津津有味地分享着各自的用车故事。 先说硬实力。缤果PRO搭载的十二
iCAR V27正式上市后的首轮大规模OTA升级现已启动,本次更新聚焦智能驾驶、主动安全与智能座舱三大核心领域,新增及优化功能总数超过140项。系统将分批向所有V27车主推送,逐步实现全量升级覆盖。首先聚焦智能辅助驾驶板块。V27全系标配的超级猎鹰700+智驾系统,集成了地平线征程6P高算力芯片与2
近日,Meta首席执行官扎克伯格再度就AI对就业的影响发表看法。据《商业内幕》7月1日报道,他针对AI可能引发大规模失业的普遍担忧提出了不同见解:许多人认为人工智能必然会取代大量岗位,但扎克伯格并不认同这一结论。 在他看来,如果企业将更多资源投入“个人增强型智能”——即利用AI强化个体的工作能力,而
- 日榜
- 周榜
- 月榜
热点快看